Roboti Soubor .txt obsahuje směrnice pro vyhledávače. Můžete jej použít k zabránění prohledávačům procházet konkrétní části vašeho webu a poskytnout vyhledávačům užitečné tipy, jak mohou nejlépe procházet váš web. Soubor robots.txt hraje v SEO velkou roli.
Při implementaci souboru robots.txt mějte na paměti následující doporučené postupy:
- Při provádění změn v souboru buďte opatrní robots.txt: tento soubor má potenciál znepřístupnit velké části vašeho webu pro vyhledávače.
- Soubor robots.txt by měl být umístěn v kořenovém adresáři vašeho webu (např.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpnebohttps). - Různé vyhledávače interpretují směrnice odlišně. Ve výchozím nastavení vždy vyhrává první odpovídající směrnice. Ale u Googlu a Bingu vyhrává specifičnost.
- Nepoužívejte co nejvíce direktivu pro procházení pro vyhledávače.
Co je to Soubor robots.txt?
Soubor robots.txt sděluje vyhledávačům, jaká jsou pravidla zapojení vašeho webu. Velkou součástí provádění SEO je odesílání správných signálů do vyhledávačů a soubor robots.txt je jedním ze způsobů, jak sdělit vaše předvolby procházení vyhledávačům.
V roce 2019 jsme se dočkali některá vylepšení týkající se standardu robots.txt: Google navrhl rozšíření Protokolu pro vyloučení robotů a otevřel svůj analyzátor robots.txt.
TL; DR
- roboti Google Tlumočník .txt je docela flexibilní a překvapivě shovívavý.
- V případě zmatených směrnic se Google na bezpečné straně mýlí a předpokládá, že sekce by měly být spíše omezené než neomezené.
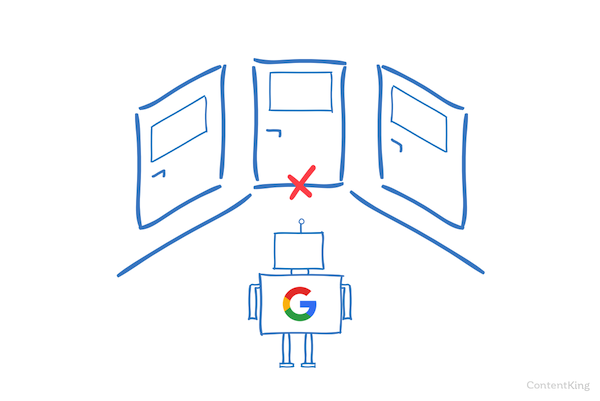
Vyhledávače pravidelně kontrolují soubor robots.txt na webu, aby zjistil, zda existují nějaké pokyny pro procházení webu. Tyto pokyny nazýváme směrnice.
Pokud není k dispozici žádný soubor robots.txt nebo neexistují žádné příslušné směrnice, procházejí vyhledávače celou webovou stránku.
Ačkoli všechny hlavní vyhledávače respektují soubor robots.txt, vyhledávače se mohou rozhodnout váš soubor robots.txt ignorovat (jeho části). Zatímco směrnice v souboru robots.txt jsou silným signálem pro vyhledávače, je důležité si uvědomit, že soubor robots.txt je spíše volitelná směrnice pro vyhledávače než mandát.

Soubor robots.txt je nejcitlivější soubor ve vesmíru SEO. Jeden znak může rozbít celý web.
Terminologie kolem souboru robots.txt
Soubor robots.txt je implementací standardu pro vyloučení robotů nebo se také nazývá protokol pro vyloučení robotů.
Proč by vás měl zajímat soubor robots.txt?
Soubor robots.txt hraje z hlediska SEO zásadní roli. Říká vyhledávačům, jak mohou nejlépe procházet vaše webové stránky.
Pomocí souboru robots.txt můžete zabránit vyhledávačům v přístupu k určitým částem vašeho webu, zabránit duplicitnímu obsahu a poskytnout vyhledávačům užitečné tipy, jak může efektivněji procházet vaše webové stránky.
Buďte opatrní při provádění změn v souboru robots.txt: tento soubor má potenciál znepřístupnit velké části vašeho webu pro vyhledávače.

Robots.txt se často používá ke snížení duplicitního obsahu, čímž zabíjení interního propojení, takže s ním buďte opravdu opatrní. Moje rada je použít ji pouze pro soubory nebo stránky, které by vyhledávací stroje nikdy neměly vidět, nebo mohou mít významný vliv na procházení tím, že jsou povoleny. Běžné příklady: oblasti přihlášení, které generují mnoho různých adres URL, testovací oblasti nebo kde může existovat více fazetová navigace. Nezapomeňte v souboru robots.txt sledovat jakékoli problémy nebo změny.

Velká většina problémů, se kterými se soubory robots.txt setkávám, spadá do tří segmentů:
- Nesprávné zacházení se zástupnými znaky. Je docela běžné vidět zablokované části webu, které mají být blokovány. Pokud si nejste opatrní, mohou se směrnice navzájem střetnout.
- Někdo, například vývojář, provedl změnu z čista jasna (často při prosazování nového kódu) a nechtěně se změnil soubor robots.txt bez vašeho vědomí.
- Zahrnutí směrnic, které nepatří do souboru robots.txt. Robots.txt je webový standard a je poněkud omezený. Často vidím vývojáře, jak připravují směrnice, které prostě nebudou fungovat (alespoň pro většinu prohledávačů). Někdy je to neškodné, jindy ne tolik.
Příklad
Podívejme se na příklad, který to ilustruje:
Vy Provozujeme web elektronického obchodu a návštěvníci mohou pomocí filtru rychle prohledávat vaše produkty. Tento filtr generuje stránky, které v zásadě zobrazují stejný obsah jako ostatní stránky. To funguje skvěle pro uživatele, ale matou to vyhledávače, protože vytváří duplicitní obsah.
Nechcete, aby vyhledávače indexovaly tyto filtrované stránky a ztrácely na těchto adresách URL svůj filtrovaný obsah. Proto byste měli nastavit Disallow pravidla, aby vyhledávací stroje neměly přístup k těmto filtrovaným stránkám produktů.
Zabránění duplicitnímu obsahu lze provést také pomocí kanonické adresy URL nebo značka meta robotů, ale neřeší to, aby vyhledávací stroje procházely pouze stránky, na kterých záleží.
Použití kanonické adresy URL nebo značky meta robotů nezabrání vyhledávačům procházet tyto stránky. Zabrání to pouze vyhledávačům ve zobrazování těchto stránek ve výsledcích vyhledávání. Jelikož vyhledávače mají pro procházení webu omezený čas, měli byste tento čas věnovat stránkám, které chcete ve vyhledávačích zobrazit.
Nesprávně nastavený soubor robots.txt může brzdit váš výkon SEO. Okamžitě zkontrolujte, zda se jedná o váš web!

Je to velmi jednoduchý nástroj, ale pokud není správně nakonfigurován, může soubor robots.txt způsobit spoustu problémů. pro větší weby. Dělat chyby, jako je blokování celého webu po zavedení nového designu nebo CMS, nebo neblokování částí webu, které by měly být soukromé, je velmi snadné. U větších webů je velmi důležité zajistit efektivní procházení Google a dobře strukturovaný soubor robots.txt je základním nástrojem v tomto procesu.
Musíte si dát čas, abyste pochopili, které části vašeho webu jsou nejlépe chráněny. od Googlu, aby trávili co nejvíce svého zdroje procházením stránek, na kterých vám opravdu záleží.
Jak vypadá soubor robots.txt?
Příklad toho, jak může jednoduchý soubor robots.txt pro web WordPress vypadat takto:
Vysvětlíme anatomii souboru robots.txt na základě výše uvedeného příkladu:
- User-agent: značka
user-agentoznačuje, pro které vyhledávání následující příkazy jsou míněny. -
*: to znamená, že směrnice jsou určeny pro všechny vyhledávače. -
Disallow: toto je směrnice označující, jaký obsah není přístupnýuser-agent. -
/wp-admin/: toto jepath, který je prouser-agentnepřístupný.
Stručně: tento soubor robots.txt říká všem vyhledávačům, aby zůstaly mimo adresář /wp-admin/.
Pojďme analyzovat různé komponenty souborů robots.txt podrobněji:
- User-agent
- zakázat
- povolit
- soubor Sitemap
- Zpoždění procházení
User-agent v souboru robots.txt
Každý vyhledávač by se měl identifikovat pomocí user-agent. Roboti Google se například identifikují jako Googlebot, roboti Yahoo jako Slurp a robot Bing jako BingBot a tak dále.
Záznam user-agent definuje začátek skupiny směrnic. Všechny směrnice mezi prvním user-agent a dalším user-agent záznamem jsou považovány za směrnice pro první user-agent.
Směrnice se mohou vztahovat na konkrétní uživatelské agenty, ale lze je také použít na všechny uživatelské agenty. V takovém případě se použije zástupný znak: User-agent: *.
Zakázat směrnici v souboru robots.txt
Můžete vyhledávačům říct, aby k nim neměly přístup určité soubory, stránky nebo části vašeho webu. To se provádí pomocí Disallow směrnice. Za směrnicí Disallow následuje path, ke kterému by se nemělo přistupovat. Pokud není definována žádná path, bude směrnice ignorována.
Příklad
V tomto příkladu se všem vyhledávačům říká, aby nepřistupovaly k adresáři /wp-admin/.
Povolit směrnici v souboru robots.txt
Směrnice Allow se používá k vyrovnání směrnice Disallow. Direktivu Allow podporují Google a Bing. Pomocí směrnic Allow a Disallow můžete vyhledávačům sdělit, že mají přístup ke konkrétnímu souboru nebo stránce v adresáři, který je jinak zakázán. Za směrnicí Allow následuje path, ke kterému lze přistupovat. Pokud není definován žádný path, bude směrnice ignorována.
Příklad
Ve výše uvedeném příkladu nemají všechny vyhledávače přístup k /media/ adresář, kromě souboru /media/terms-and-conditions.pdf.
Důležité: při použití Allow a Disallow direktivy společně, nepoužívejte zástupné znaky, protože by to mohlo vést ke konfliktním směrnicím.
Příklad konfliktních směrnic
Vyhledávače nebudou vědět, co mají dělat s adresou URL . Není jim jasné, zda mají přístup. Pokud směrnice nejsou Googlu jasné, použijí nejméně restriktivní směrnici, což v tomto případě znamená, že by ve skutečnosti měli přístup k
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt je jednou z funkcí, které nejčastěji vidím implementovány nesprávně, takže neblokuje to, co chtěli blokovat, nebo blokuje více, než očekávali, a má negativní dopad na jejich web. Robots.txt je velmi výkonný nástroj, ale příliš často je nesprávně nastaven.
Použití zástupného znaku *
Zástupný znak lze použít nejen k definování user-agent, ale lze jej také použít k odpovídat adresám URL. Zástupný znak podporují Google, Bing, Yahoo a Ask.
Příklad
Ve výše uvedeném příkladu nemají všechny vyhledávače povolen přístup k adresám URL, které obsahují otazník (?).

Vývojáři nebo si majitelé stránek často myslí, že v souboru robots.txt mohou využívat všechny druhy regulárních výrazů, zatímco ve skutečnosti je platné jen velmi omezené množství shody vzorů – například zástupné znaky (
*). Zdá se, že občas dochází k záměně mezi soubory .htaccess a robots.txt.
Použití konce adresy URL $
K označení konce adresy URL můžete použít znak dolaru ($) na konci path.
Příklad
Ve výše uvedeném příkladu nemají vyhledávače přístup ke všem adresám URL, které končí příponou .php . URL s parametry, např. nebude zakázáno, protože adresa URL nekončí po .php.
Přidejte do robotů soubor Sitemap. txt
Přestože byl soubor robots.txt vytvořen proto, aby vyhledávacím strojům řekl, které stránky nemají procházet, lze soubor robots.txt také použít k nasměrování vyhledávacích strojů na soubor XML sitemap. Toto podporují Google, Bing, Yahoo a Ask.
Na soubor XML by měl být odkazováno jako na absolutní adresu URL. Adresa URL nemusí být na stejném hostiteli jako soubor robots.txt.
Odkaz na soubor Sitemap XML v souboru robots.txt je jedním z nejlepších postupů, které vám doporučujeme vždy použít, i když možná jste již odeslali svůj soubor Sitemap XML v Google Search Console nebo v Nástrojích pro webmastery Bing. Pamatujte, že existuje více vyhledávačů.
Upozorňujeme, že v souboru robots.txt je možné odkazovat na více souborů Sitemap XML.
Příklady
Více Soubory XML Sitemap definované v souboru robots.txt:
Jeden soubor XML Sitemap definovaný v robotech.Soubor txt:
Výše uvedený příklad říká všem vyhledávačům, aby nepřistupovaly k adresáři /wp-admin/ a že soubor Sitemap XML lze najít na
Comments are preceded by a # a může buď být umístěny na začátku řádku, nebo za směrnici na stejném řádku. Vše po # bude ignorováno. Tyto komentáře jsou určeny pouze pro člověka.
Příklad 1
Příklad 2
Výše uvedené příklady komunikují stejnou zprávu.
Zpoždění procházení v souboru robots.txt
The Crawl-delay směrnice je neoficiální směrnice používaná k zabránění přetížení serverů příliš velkým počtem požadavků. Pokud jsou vyhledávače schopny server přetížit, přidání Crawl-delay do souboru robots.txt je pouze dočasnou opravou. Skutečností je, že váš web běží na špatném hostitelském prostředí nebo je váš web nesprávně nakonfigurován, a měli byste to co nejdříve opravit.
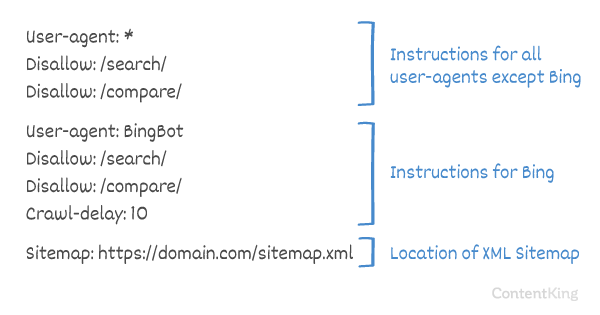
Způsob, jakým vyhledávače zpracovávají Crawl-delay, se liší. Níže vysvětlíme, jak to hlavní vyhledávače zpracovávají.
Zpoždění procházení a Google
Prohledávač Google, Googlebot, nepodporuje Crawl-delay směrnice, takže se neobtěžujte s definováním zpoždění procházení Google.
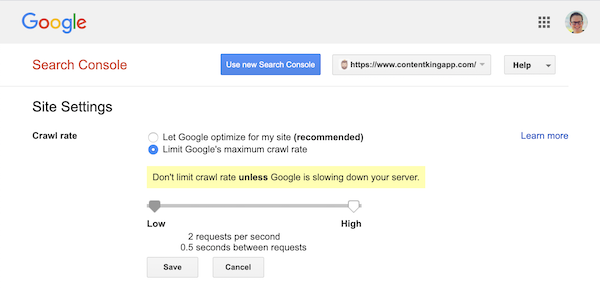
Google však definování rychlosti procházení (nebo „rychlosti požadavku“, pokud chcete) podporuje. ) v Google Search Console.
- Přihlaste se ke staré Google Search Console.
- Vyberte web, který chcete chcete definovat rychlost procházení pro.
- Je možné vyladit pouze jedno nastavení:
Crawl ratepomocí posuvníku, kde můžete nastavit preferovanou rychlost procházení. Ve výchozím nastavení rychlost procházení je nastavena na „Nechat Google optimalizovat pro můj web (doporučeno)“.
Takto vypadá v Google Search Console:
Zpoždění procházení a Bing, Yahoo a Yandex
Bing, Yahoo a Yandex všechny podporují Crawl-delay směrnice k omezení procházení webu. Jejich interpretace zpoždění procházení se však mírně liší, takže si nezapomeňte zkontrolovat jejich dokumentaci:
- Bing a Yahoo
- Yandex
Směrnice Crawl-delay by měla být umístěna hned za směrnice Disallow nebo Allow.
Příklad:
Zpoždění procházení a Baidu
Baidu nepodporuje směrnici crawl-delay, je však možné zaregistrovat účet Baidu Webmaster Tools v pomocí kterého můžete řídit frekvenci procházení, podobně jako v Google Search Console.
Kdy použít soubor robots.txt?
Doporučujeme vždy použít soubor robots.txt. Není absolutně nic na škodu mít jeden, a je to skvělé místo, kde můžete vyhledávačům vydat směrnice, jak nejlépe procházet vaše webové stránky.

Soubor robots.txt může být užitečný k zabránění procházení a indexování určitých oblastí nebo dokumentů na vašem webu. Příkladem je například pracovní web nebo soubory PDF. Pečlivě si naplánujte, co je třeba indexovat pomocí vyhledávačů, a mějte na paměti, že obsah, který byl pomocí souboru robots.txt znepřístupněn, mohou prohledávače vyhledávačů stále najít, pokud je propojen s jinými oblastmi webu.
doporučené postupy pro Robots.txt
Doporučené postupy pro robots.txt jsou rozděleny do následujících kategorií:
- Umístění a název souboru
- Pořadí priorit
- Na robota pouze jedna skupina směrnic
- Buďte co nejkonkrétnější
- Směrnice pro všechny roboty a zároveň zahrňte směrnice pro konkrétního robota
- Soubor Robots.txt pro každou (sub) doménu.
- Pokyny ke konfliktům: robots.txt vs. Google Search Console
- Sledujte svůj soubor robots.txt
- Nepoužívejte ve svém souboru robots.txt noindex
- Zabránit kusovníku UTF-8 v souboru robots.txt
Umístění a název souboru
Soubor robots.txt by měl být vždy umístěn v e root webu (v adresáři nejvyšší úrovně hostitele) a nést název souboru robots.txt, například: . Všimněte si, že adresa URL souboru robots.txt rozlišuje, stejně jako kterákoli jiná URL, velká a malá písmena.
Pokud soubor robots.txt nelze najít ve výchozím umístění, vyhledávače předpokládají, že na vašem webu neexistují žádné směrnice, a procházejí se pryč.
Pořadí priority
Je důležité si uvědomit, že vyhledávače zpracovávají soubory robots.txt odlišně. Ve výchozím nastavení vždy vyhrává první odpovídající směrnice.
U Google a Bing však vyhrává specifičnost. Například: směrnice Allow zvítězí nad směrnicí Disallow, pokud je její délka znaků delší.
Příklad
V příklad nad všemi vyhledávači, včetně Google a Bing, nemá přístup do adresáře /about/, kromě podadresáře /about/company/.
Příklad
Ve výše uvedeném příkladu nemají všechny vyhledávače kromě Google a Bing přístup k adresáři /about/. To zahrnuje adresář /about/company/.
Google a Bing mají povolený přístup, protože směrnice Allow je delší než Disallow směrnice.
Na robota pouze jedna skupina směrnic
Na jeden vyhledávač můžete definovat pouze jednu skupinu směrnic. Mít více skupin směrnic pro jeden vyhledávač je matoucí.
Buďte co nejkonkrétnější
Směrnice Disallow se spouští při částečných shodách jako studna. Při definování směrnice Disallow buďte co nejkonkrétnější, abyste zabránili neúmyslnému znemožnění přístupu k souborům.
Příklad:
Výše uvedený příklad neumožňuje přístup vyhledávačů k:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
směrnice pro všechny roboty a zároveň obsahují směrnice pro konkrétního robota
pro robota pouze jedna skupina směrnic je platná. V případě, že směrnice určené pro všechny roboty budou následovány směrnicemi pro konkrétního robota, budou brány v úvahu pouze tyto konkrétní směrnice. Aby konkrétní robot také dodržoval směrnice pro všechny roboty, musíte tyto směrnice opakovat pro konkrétního robota.
Podívejme se na příklad, který to objasní:
Příklad
Pokud nechcete, aby googlebot měl přístup k /secret/ a /not-launched-yet/, musíte tyto směrnice zopakovat pro googlebot konkrétně:
Upozorňujeme, že váš soubor robots.txt je veřejně dostupný. Zakázání sekcí webových stránek tam může být použito jako útok pro lidi se zákeřnými úmysly.

Soubor robots.txt může být nebezpečný. Říkáte vyhledávačům nejen to, kam nechcete, aby hledali, ale také lidem, kde schováváte svá špinavá tajemství.
Soubor Robots.txt pro každou (pod) doménu
Pouze směrnice Robots.txt použít na (sub) doménu, na které je soubor hostován.
Příklady
platí pro , ale ne pro nebo
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Z tohoto důvodu jsme vytvořili sledování změn a upozornění na soubor robots.txt.
Vidíme to pořád: soubory robots.txt se mění bez znalosti digitálního marketingu tým. Nebuďte tím člověkem. Začněte sledovat svůj soubor robots.txt, nyní obdržíte upozornění, když se změní!
Nepoužívejte ve svém souboru robots.txt noindex
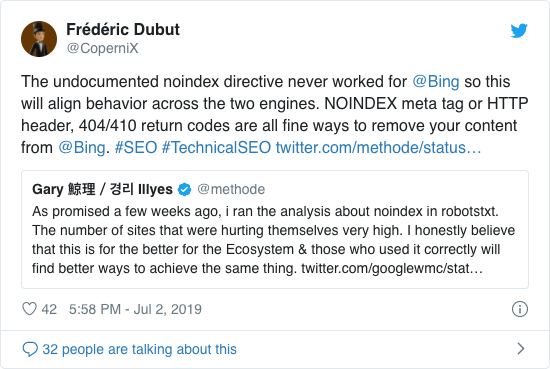
Google již léta otevřeně doporučoval nepoužívat neoficiální směrnici noindex. Od 1. září 2019 to však Google úplně přestal podporovat.
Neoficiální direktiva noindex v Bingu nikdy nefungovala, jak potvrzuje Frédéric Dubut v tomto tweetu:
Nejlepší způsob, jak signalizovat vyhledávačům, že by stránky neměly být indexovány, je použití značky meta robots nebo X-Robots-Tag .
Zabraňte kusovníku UTF-8 v souboru robots.txt
Kusovník znamená značku pořadí bajtů, neviditelný znak na začátku soubor používaný k označení kódování Unicode textového souboru.
Zatímco Google uvádí, že ignoruje volitelnou značku pořadí bajtů Unicode na začátku souboru robots.txt, doporučujeme zabránit „UTF-8 BOM“, protože jsme viděli, že to způsobuje problémy s interpretací soubor robots.txt vyhledávači.
Přestože Google tvrdí, že si s tím poradí, existují dva důvody, proč BOM UTF-8 zabránit:
- Nechci, aby existovaly nejasnosti ohledně vašich preferencí při procházení do vyhledávačů.
- Existují i jiné vyhledávače, které nemusí být tak shovívavé, jak Google tvrdí.
Příklady Robots.txt
V této kapitole pojednáme o široké škále příkladů souborů robots.txt:
- Povolit všem robotům přístup ke všemu
- Zakázat všem robotům přístup ke všemu
- Všichni roboti Google nemají přístup
- Všichni roboti Google, kromě novinek Googlebot, nemají přístup
- Googlebot a Slurp nemají žádný přístup
- Všichni roboti nemají přístup ke dvěma adresáře
- Všichni roboti nemají přístup k jednomu konkrétnímu souboru
- Googlebot nemá přístup k / admin / a Slurp nemá přístup k / private /
- Soubor Robots.txt pro WordPress
- Soubor Robots.txt pro Magento
Povolit všem robotům přístup ke všemu
Existuje několik způsobů abyste vyhledávačům řekli, že mají přístup ke všem souborům:
Nebo mít prázdný soubor robots.txt nebo vůbec žádný soubor robots.txt.
Zakázat všem robotům přístup ke všemu
Příklad Soubor robots.txt níže říká všem vyhledávačům, aby nepřistupovaly na celý web:
Upozorňujeme, že rozdíl může mít pouze JEDEN znak navíc.
Všichni roboti Google nemají přístup
Upozorňujeme, že když zakážete robota Googlebot, bude to platit pro všechny roboty Googlebot. To zahrnuje roboty Google, kteří hledají například novinky (googlebot-news) a obrázky (googlebot-images).
Vše Google roboti, kromě novinek Googlebot, nemají přístup
Googlebot a Slurp nemají žádný přístup
Všichni roboti nemají přístup ke dvěma adresářům
Všichni roboti nemají přístup k jednomu konkrétnímu souboru
Googlebot nemá přístup k / admin / a Slurp nemá přístup k / private /
Robots.txt soubor pro WordPress
Níže uvedený soubor robots.txt je speciálně optimalizován pro WordPress za předpokladu:
- Nechcete, aby byla procházena vaše administrátorská sekce.
- Nechcete, aby byly procházeny vaše interní stránky s výsledky vyhledávání.
- Nechcete, aby byly procházeny vaše stránky značek a autorů.
- Nechcete, aby byla vaše stránka 404 procházena.
Upozorňujeme, že tento soubor robots.txt bude ve většině případů fungovat, ale měli byste jej vždy upravit a otestovat, abyste se ujistili, že se vztahuje na váš přesná situace.
Soubor Robots.txt pro Magento
Níže uvedený soubor robots.txt je speciálně optimalizován pro Magento a bude vytvářet interní výsledky vyhledávání, přihlašovací stránky, identifikátory relací a filtrované výsledky sady, které obsahují price, color, material a size kritéria nepřístupná prohledávačům.
Upozorňujeme, že tento soubor robots.txt bude fungovat ve většině obchodů Magento, ale vy měli byste to vždy upravit a otestovat, abyste se ujistili, že platí pro vaši přesnou situaci.
Stále se snažím blokovat interní výsledky vyhledávání v souboru robots.txt na libovolném webu, protože tyto typy adres URL pro vyhledávání jsou nekonečné a nekonečné mezery. Existuje velký potenciál, že se Googlebot dostane do pastí prohledávače.
Jaká jsou omezení souboru robots.txt?
Soubor Robots.txt obsahuje směrnice
Přestože je soubor robots.txt vyhledáváním dobře respektován motory, je to stále směrnice a nikoli mandát.
Stránky se stále zobrazují ve výsledcích vyhledávání
Stránky, které jsou pro roboty nepřístupné pro vyhledávače.txt, ale mají odkazy na ně, se mohou stále zobrazovat ve výsledcích vyhledávání, pokud jsou propojeny ze stránky, která je procházena. Příklad toho, jak to vypadá:

Tyto adresy URL je možné z Googlu odebrat pomocí nástroje pro odstraňování adres URL z Google Search Console. Upozorňujeme, že tyto adresy URL budou pouze dočasně „skryty“. Aby zůstaly mimo stránky s výsledky Google, je třeba každých 180 dní odeslat žádost o skrytí adres URL.

Pomocí souboru robots.txt zablokujte nežádoucí a pravděpodobně škodlivé přidružené zpětné odkazy. nepoužívejte soubor robots.txt ve snaze zabránit indexování obsahu vyhledávacími stroji, protože to nevyhnutelně selže. Místo toho použijte v případě potřeby direktivu robots noindex.
Soubor Robots.txt je uložen do mezipaměti až 24 hodin
Google uvedl, že roboti Soubor .txt se obvykle ukládá do mezipaměti až na 24 hodin. Je důležité to vzít v úvahu při provádění změn v souboru robots.txt.
Není jasné, jak jiné vyhledávače řeší ukládání souboru robots.txt do mezipaměti. , ale obecně je nejlepší vyhnout se ukládání souboru robots.txt do mezipaměti na av oidové vyhledávací stroje trvají déle, než je nutné, aby mohly změny zachytit.
Velikost souboru Robots.txt
U souborů robots.txt Google aktuálně podporuje limit velikosti souboru 500 kibibytů (512 kilobajtů). Jakýkoli obsah po této maximální velikosti souboru může být ignorován.
Není jasné, zda ostatní vyhledávače mají maximální velikost souborů pro soubory robots.txt.
Často kladené otázky o souboru robots.txt
🤖 Jak vypadá příklad souboru robots.txt?
Zde je příklad obsahu souboru robots.txt: User-agent: * Disallow:. To prozradí všem prohledávačům, že mají přístup ke všemu.
⛔ Co dělá příkaz Disallow all v souboru robots.txt?
Když nastavíte soubor robots.txt na hodnotu „Disallow all“, v podstatě říká všem prohledávačům, aby se nedostaly. Žádným prohledávačům, včetně Google, není povolen přístup na váš web. To znamená, že nebudou moci procházet, indexovat a hodnotit váš web. To povede k obrovskému poklesu organického provozu.
✅ Co dělá Povolit vše v souboru robots.txt?
Když nastavíte soubor robots.txt na „Povolit vše“, řeknete každému prohledávači, že má přístup ke každé adrese URL na webu. Neexistují prostě žádná pravidla zapojení. Toto je ekvivalent toho, že máte prázdný soubor robots.txt nebo vůbec žádný soubor robots.txt.
🤔 Jak důležitý je soubor robots.txt pro SEO?
V obecně je soubor robots.txt velmi důležitý pro účely SEO. U větších webů je soubor robots.txt zásadní, aby vyhledávačům poskytl velmi jasné pokyny, k jakému obsahu nemá přistupovat.