Ikkunassa ROW_NUMBER on lukuisia käytännön sovelluksia, jotka ylittävät selvästi ilmeiset sijoitustarpeet. Suurimman osan ajasta, kun lasket rivinumeroita, sinun on laskettava ne jonkin järjestyksen perusteella ja annat haluamasi järjestysmäärittelyn funktion ikkunan järjestyslausekkeessa. On kuitenkin tapauksia, joissa sinun on laskettava rivinumerot tietyssä järjestyksessä; toisin sanoen epädeterministiseen järjestykseen. Tämä voi tapahtua koko kyselytuloksessa tai osioissa. Esimerkkejä ovat yksilöllisten arvojen osoittaminen tulosriveille, tietojen deduplikaatio ja minkä tahansa rivin palauttaminen ryhmää kohden.
Huomaa, että rivinumeroiden määritteleminen epädeterministisen järjestyksen perusteella on erilainen kuin niiden määrääminen satunnaisessa järjestyksessä. Ensimmäisten kanssa et vain välitä siitä, missä järjestyksessä ne on määritetty ja määrittävätkö kyselyn toistuvat suoritukset edelleen samat rivinumerot samoille riveille vai ei. Jälkimmäisen kohdalla oletat toistuvien teloitusten muuttavan jatkuvasti, mitkä rivit määritetään mihin rivinumeroihin. Tässä artikkelissa tarkastellaan erilaisia tekniikoita rivinumeroiden laskemiseksi epädeterministisessä järjestyksessä. Toivo on löytää tekniikka, joka on sekä luotettava että optimaalinen.
Erityiset kiitokset Paul Whiteille jatkuvaa taittamista koskevasta vinkistä, ajonaikaisesta jatkuvasta tekniikasta ja aina erinomaisesta tiedonlähteestä!
Kun tilaus on tärkeää
Aloitan tapauksista, joissa rivinumeroiden järjestyksellä on merkitystä.
Käytän esimerkissä taulukkoa T1. Luo tämä taulukko seuraavan koodin avulla ja täytä se esimerkkitiedoilla:
Harkitse seuraavaa kyselyä (kutsumme sitä kyselyksi 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Täällä haluat, että rivinumerot määritetään jokaiselle ryhmälle, jonka sarake grp tunnistaa sarakkeen datacol-järjestyksellä. Kun suoritin tämän kyselyn järjestelmässäni, sain seuraavan tuloksen:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Rivinumerot määritetään tähän osittain deterministisessä ja osittain epädeterministisessä järjestyksessä. Tarkoitan tällä sitä, että sinulla on varmuus siitä, että saman osion sisällä rivi, jolla on suurempi datacol-arvo, saa suuremman rivinumeron. Koska datacol ei kuitenkaan ole ainutlaatuinen grp-osiossa, rivinumeroiden järjestys rivien välillä, joilla on samat grp- ja datacol-arvot, on epämääräinen. Näin on riveillä, joiden id-arvo on 2 ja 11. Molemmilla on grp-arvo A ja datacol-arvo 50. Kun suoritin tämän kyselyn järjestelmässäni ensimmäistä kertaa, rivillä, jolla oli tunnus 2, oli rivinumero 2 ja rivi tunnuksella 11 sai rivinumeron 3. Älä välitä todennäköisyydestä, että tämä tapahtuu käytännössä SQL Serverissä; jos suoritan kyselyn uudelleen, teoriassa riville, jonka tunnus on 2, voidaan määrittää rivi numero 3 ja riville, jonka tunnus on 11, rivinumerolle 2.
Jos sinun on määritettävä rivinumeroita täysin deterministisessä järjestyksessä, joka takaa toistettavissa olevat tulokset kyselyn suorituksissa, kunhan taustalla olevat tiedot eivät muutu, tarvitset ikkunoiden osiointi- ja tilauslausekkeiden elementtien yhdistelmän ainutlaatuisen. Tämä voidaan saavuttaa tapauksessamme lisäämällä sarakkeen tunnus ikkunajärjestyslausekkeeseen tiebreakerina. Tällöin OVER-lauseke olisi:
OVER (PARTITION BY grp ORDER BY datacol, id)
SQL-palvelimen on joka tapauksessa, kun lasketaan rivinumeroita mielekkäiden järjestysmääritysten perusteella, kuten kyselyssä 1, rivit järjestetään ikkunan osioinnin ja järjestyselementtien yhdistelmällä. Tämä voidaan saavuttaa joko vetämällä ennakolta tilattu data indeksistä tai lajittelemalla tiedot. Tällä hetkellä T1: ssä ei ole hakemistoa, joka tukisi kyselyn 1 ROW_NUMBER-laskentaa, joten SQL Serverin on valittava tietojen lajittelu. Tämä näkyy kuvassa 1 esitetyn kyselyn 1 suunnitelmassa.
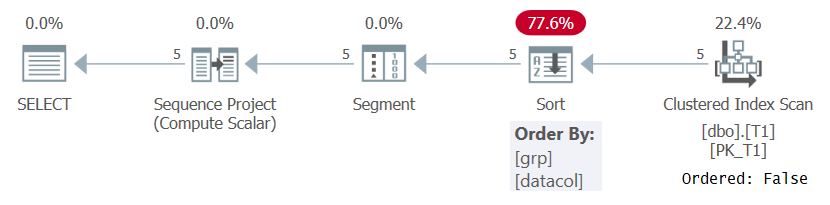 Kuva 1: Kyselyn 1 suunnitelma ilman tukihakemistoa
Kuva 1: Kyselyn 1 suunnitelma ilman tukihakemistoa
Huomaa, että suunnitelma skannaa tiedot klusteroidusta hakemistosta Järjestetty: Väärä -ominaisuudella. Tämä tarkoittaa, että skannauksen ei tarvitse palauttaa hakemistonäppäimen järjestämiä rivejä. Näin on, koska klusteroitua hakemistoa käytetään tässä vain siksi, että se sattuu kattamaan kyselyn eikä sen avaimen järjestyksestä. Suunnitelmassa käytetään sitten lajittelua, mikä johtaa ylimääräisiin kustannuksiin, N Log N-skaalaukseen ja viivästyneeseen vasteaikaan. Segmenttioperaattori tuottaa lipun, joka osoittaa, onko rivi osion ensimmäinen vai ei. Lopuksi, Sequence Project -operaattori määrittää jokaisessa osiossa rivinumerot, jotka alkavat yhdellä.
Jos haluat välttää lajittelua, voit valmistaa peittoindeksin, jossa on osiointi- ja järjestyselementteihin perustuva avainluettelo ja peiteelementteihin perustuva sisällysluettelo.Haluan ajatella tätä hakemistoa POC-indeksinä (osiointia, tilaamista ja peittämistä varten). Tässä on kyselymme tukevan POC: n määritelmä:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Suorita kysely 1 uudelleen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Suorituksen suunnitelma on esitetty kuvassa 2.
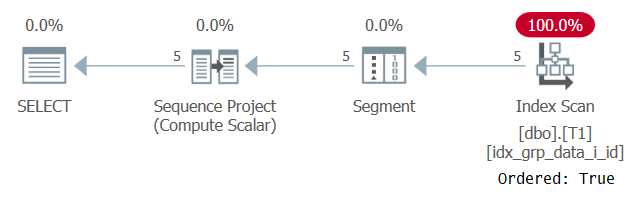 Kuva 2: Kyselyn 1 suunnitelma POC-indeksillä
Kuva 2: Kyselyn 1 suunnitelma POC-indeksillä
Huomaa, että tällä kertaa suunnitelma skannaa POC-indeksin Järjestetty: Tosi-ominaisuudella. Tämä tarkoittaa, että skannaus takaa, että rivit palautetaan hakemistoavainjärjestyksessä. Koska tiedot vedetään ennakkotilattuna hakemistosta, kuten ikkunatoiminto tarvitsee, nimenomaista lajittelua ei tarvita. Tämän suunnitelman skaalaus on lineaarinen ja vasteaika on hyvä.
Kun järjestyksellä ei ole väliä
Asiat muuttuvat hieman hankaliksi, kun sinun on annettava rivinumerot täysin epädeterministisillä Luonnollinen asia, jonka haluat tehdä tällaisessa tapauksessa, on käyttää funktiota ROW_NUMBER määrittelemättä ikkunan järjestyslauseketta. Tarkista ensin, salliko SQL-standardi tämän. Tässä on standardin asiaankuuluva osa, joka määrittelee ikkunan syntaksisäännöt funktiot:
Huomaa, että kohdassa 6 luetellaan funktiot < ntile-funktio >, < johto- tai viivetoiminto >, < sijoitusfunktion tyyppi > tai ROW_NUMBER ja sitten kohta 6a sanoo, että funktioille < ntile-funktio >, < lyijy- tai viivetoiminto >, RANK tai DENSE_RANK, ikkunan järjestyslausekkeen on b e läsnä. Ei ole nimenomaista kieltä, joka ilmoittaa, edellyttääkö ROW_NUMBER ikkunajärjestyslauseketta vai ei, mutta funktion mainitseminen kohdassa 6 ja sen jättäminen pois 6a: sta voi tarkoittaa, että lause on valinnainen tälle toiminnolle. On melko selvää, miksi RANK: n ja DENSE_RANK: n kaltaiset toiminnot vaativat ikkunajärjestyslauseketta, koska nämä toiminnot ovat erikoistuneet siteiden käsittelyyn, ja siteet ovat olemassa vain, kun tilaustiedot on määritetty. Voit kuitenkin varmasti nähdä, kuinka ROW_NUMBER-funktio voisi hyötyä valinnaisesta ikkunoiden järjestyslausekkeesta.
Joten kokeilemme sitä ja yritämme laskea rivinumerot ilman ikkunoiden järjestystä SQL Serverissä:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Tämä yritys aiheuttaa seuraavan virheen:
Toiminto ”ROW_NUMBER” täytyy olla OVER-lauseke ORDER BY -toiminnolla.
Jos tarkistat SQL-palvelimen dokumentaation ROW_NUMBER-funktiosta, löydät seuraavan tekstin:
ORDER BY-lauseke määrittää järjestyksen, jossa riveille määritetään yksilöllinen ROW_NUMBER määritetyssä osiossa. Se on pakollinen. ”
Joten ilmeisesti ikkunajärjestyslauseke on pakollinen SQL Serverin ROW_NUMBER-funktiolle. . Tämä pätee muuten myös Oraclessa.
Minun on sanottava, etten ole varma, että ymmärrän syy ng tämän vaatimuksen takana. Muista, että annat määrittää rivinumerot osittain epädeterministisen järjestyksen perusteella, kuten kyselyssä 1. Joten miksi et sallisi epädeterminismin koko ajan? Ehkä on jokin syy, mistä en ajattele. Jos voit ajatella tällaista syytä, jaa.
Joka tapauksessa voit väittää, että jos et välitä tilauksesta, koska ikkunajärjestyslauseke on pakollinen, voit määrittää minkä tahansa Tilaus. Tämän lähestymistavan ongelmana on, että jos tilaat jonkin sarakkeen kysytyistä taulukoista, tämä saattaa merkitä tarpeetonta suoritusrangaistusta. Jos tukihakemistoa ei ole, maksat nimenomaisesta lajittelusta. Kun tukihakemisto on paikallaan, rajoitat tallennusmoottorin hakemistotilausten skannausstrategiaan (indeksilinkkiluettelon mukaisesti). Et salli sille enemmän joustavuutta, kuten yleensä, kun tilauksella ei ole väliä valita hakemistotilausskannauksen ja allokointitilauksen skannauksen välillä (perustuu IAM-sivuihin).
Yksi idea, joka kannattaa kokeilla on määrittää vakio, kuten 1, ikkunan järjestyslausekkeeseen. Jos sitä tuetaan, toivot, että optimoija on tarpeeksi älykäs ymmärtääkseen, että kaikilla riveillä on sama arvo, joten tilauksella ei ole todellista merkitystä eikä siksi tarvitse pakottaa lajittelu- tai hakemistotilausten tarkistusta. Tässä kysely yrittää tätä lähestymistapaa:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Valitettavasti SQL Server ei tue tätä ratkaisua. Se tuottaa seuraavan virheen:
Toiminnot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue kokonaislukuindeksejä ORDER BY -lausekkeen lausekkeina.
Ilmeisesti SQL Server olettaa, että jos käytät kokonaisluvuvakiota ikkunoiden järjestyslausekkeessa, se edustaa elementin järjestysasemaa SELECT-luettelossa, kuten silloin, kun määrität kokonaisluvun esityksessä ORDER BY-lauseke. Jos näin on, toinen kokeilemisen arvoinen vaihtoehto on määrittää ei-integraalivakio, kuten näin:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Osoittautuu, että myös tätä ratkaisua ei tueta. SQL Server luo seuraavan virheen:
Toiminnot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue vakioita ORDER BY -lausekkeen lausekkeina.
Ikkunoiden järjestyslauseke ei ilmeisesti tue minkäänlaista vakiota.
Tähän mennessä olemme oppineet seuraavaa funktion ROW_NUMBER ikkunoiden järjestyskohdista SQL Serverissä:
- ORDER BY vaaditaan.
- Järjestystä ei voi järjestää kokonaisluvulla, koska SQL Server uskoo, että yrität määrittää järjestyskohdan SELECTissa.
- Ei voi järjestää kaikenlainen vakio.
Johtopäätöksenä on, että sinun pitäisi tilata lausekkeilla, jotka eivät ole vakioita. Voit tietysti järjestää sarakeluettelon kyselytaulukosta. Mutta pyrimme löytämään tehokkaan ratkaisun, jossa optimoija voi huomata, että tilauksen merkitystä ei ole.
Jatkuva taitto
Tähän mennessä on päätelty, että et voi käyttää vakioitaROW_NUMBER-ikkunan järjestyslauseke, mutta entä vakioihin perustuvat lausekkeet, kuten seuraavassa kyselyssä:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Tämä yritys kuitenkin joutuu jatkuvan prosessin uhriksi taitto, jolla on yleensä positiivinen suorituskyky kyselyihin. Tämän tekniikan idea on parantaa kyselyn suorituskykyä taittamalla osa vakioihin perustuvasta lausekkeesta tulosvakioksi kyselyn käsittelyn varhaisessa vaiheessa. Täältä löydät yksityiskohdat siitä, millaisia ilmaisuja voidaan taittaa jatkuvasti. Lauseke 1 + 0 on taitettu arvoon 1, mikä johtaa samaan virheeseen, jonka sait määritettäessä vakio 1 suoraan:
Ikkunalliset toiminnot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue kokonaislukuindeksejä ORDER BY -lausekelausekkeina.
Voit kohdata samanlaisen tilanteen yrittäessäsi liittää kahta merkkijonolitraalia, kuten näin:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Saat saman virheen kuin mitä määritit kirjaimellisesti ”Ei järjestystä” suoraan:
ikkunoitu funktiot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue vakioita ORDER BY -lausekkeen lausekkeina.
Bizarro-maailma – virheitä estävät virheet
Elämä on täynnä yllätyksiä …
Yksi asia, joka estää jatkuvan taittumisen, on, kun lauseke johtaa normaalisti virheeseen. Esimerkiksi lauseke 2147483646 + 1 voidaan taittaa vakiona, koska se johtaa kelvolliseen INT-tyyppiseen arvoon. Tämän seurauksena yritys suorittaa seuraava kysely epäonnistuu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Ilmoitetut funktiot, aggregaatit ja SEURAAVA ARVO FOR-funktiot eivät tue kokonaislukuindeksejä ORDER BY -lausekkeen lausekkeina.
Lauseketta 2147483647 + 1 ei kuitenkaan voida taittaa vakiona, koska tällainen yritys olisi johtanut INT-ylivuotovirheeseen. Vaikutus tilaamiseen on varsin mielenkiintoinen. Kokeile seuraavaa kyselyä (kutsumme tätä kyselyksi 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Kumma kyllä tämä kysely toimii onnistuneesti! Tapahtuma on, että toisaalta SQL Server ei käytä jatkuvaa taittoa, ja siksi järjestys perustuu lausekkeeseen, joka ei ole yksi vakio. Toisaalta optimoija arvelee, että tilausarvo on sama kaikilla riveillä, joten se ohittaa järjestyslausekkeen kokonaan. Tämä vahvistetaan, kun tarkastellaan kyselyn suunnitelmaa kuvan 3 mukaisesti.
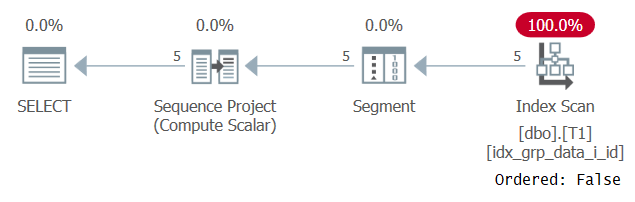 Kuva 3: Kyselyn 2 suunnitelma
Kuva 3: Kyselyn 2 suunnitelma
Huomioi että suunnitelma skannaa jonkin peittoindeksin Järjestetty: Väärä -ominaisuudella. Tämä oli täsmälleen suorituskykytavoitteemme.
Vastaavalla tavalla seuraava kysely sisältää onnistuneen jatkuvan taittoyrityksen ja epäonnistuu siksi:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Toiminnot, aggregaatit ja funktioiden SEURAAVA ARVO eivät tue kokonaislukuindeksejä ORDER BY -lausekkeen lausekkeina.
Seuraava kysely sisältää epäonnistuneen jatkuvan taittoyrityksen, joten se onnistuu luomalla aiemmin kuvassa 3 esitetty suunnitelma:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Seuraava kyselyyn sisältyy onnistunut jatkuva taittoyritys (VARCHAR-kirjain ”1” muunnetaan implisiittisesti INT 1: ksi ja sitten 1 + 1 taitetaan arvoon 2), ja siksi epäonnistuu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Toiminnot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue kokonaislukuindeksejä ORDER BY -lausekkeen lausekkeina.
Seuraava kysely sisältää epäonnistui jatkuva taittoyritys (ei voi muuntaa ”A”: ta INT: ksi), ja siksi se onnistuu, luomalla aiemmin kuvassa 3 esitetty suunnitelma:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Ollakseni rehellinen, vaikka tämä omituinen tekniikka saavuttaa alkuperäisen suorituskykytavoitteemme, en voi sanoa, että pidän sitä turvallisena, joten en ole niin mukava luottaa siihen.
Toimintoihin perustuvat ajonaikavakiot
Jatkamalla hyvän ratkaisun etsimistä rivinumeroiden laskemiseksi epädeterministisessä järjestyksessä, on olemassa muutamia tekniikoita, jotka näyttävät turvallisemmilta kuin viimeinen omituinen ratkaisu: funktioihin perustuvien ajonaikavakioiden käyttäminen, vakioon perustuvan alalausekkeen käyttäminen aliaksinen sarake, joka perustuu vakioon ja käyttää muuttujaa.
Kuten selitän T-SQL-virheissä, ongelmissa ja parhaissa käytännöissä – determinismi, useimmat T-SQL: n toiminnot arvioidaan vain kerran kyselyssä olevaa viittausta kohti – ei kerran riviä kohden. Näin on jopa useimmissa epämääräisissä toiminnoissa, kuten GETDATE ja RAND. Tästä säännöstä on hyvin vähän poikkeuksia, kuten funktiot NEWID ja CRYPT_GEN_RANDOM, jotka arvioidaan kerran rivillä. Suurin osa toiminnoista, kuten GETDATE, @@ SPID ja monet muut, arvioidaan kerran kyselyn alussa, ja niiden arvoja pidetään sitten ajonaikavakioina. Viittaus tällaisiin toimintoihin ei taittu vakiona. Nämä ominaisuudet tekevät funktioon perustuvasta ajonaikavakiosta hyvän valinnan ikkunoiden järjestyselementtinä, ja näyttää siltä, että T-SQL tukee sitä. Samalla optimoija ymmärtää, että käytännössä ei ole tilauksen merkitystä, välttäen tarpeettomia suorituskyky rangaistuksia.
Tässä on esimerkki GETDATE-toiminnosta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Tämä kysely saa saman suunnitelman kuin aiemmin kuvassa 3.
Tässä on toinen esimerkki @@ SPID-funktiolla (palautetaan nykyisen istunnon tunnus):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Entä funktio PI? Kokeile seuraavaa kyselyä:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Tämä epäonnistuu seuraavan virheen kanssa:
Perutut funktiot, aggregaatit ja NEXT VALUE FOR -funktiot eivät tue vakioita ORDER BY -lausekkeen lausekkeina.
Funktiot, kuten GETDATE ja @@ SPID, arvioidaan uudelleen kerran suunnitelman suorituksen aikana, joten he eivät voi saada vakiona taitettuna. PI edustaa aina samaa vakiota ja taittuu siten vakiona.
Kuten aiemmin mainittiin, on hyvin vähän toimintoja, jotka arvioidaan kerran rivillä, kuten NEWID ja CRYPT_GEN_RANDOM. Tämä tekee heistä huonon valinnan ikkunoiden tilauselementiksi, jos tarvitset epädeterminististä järjestystä – älä sekoita satunnaiseen järjestykseen. Miksi maksaa turha lajittelurangaistus?
Tässä on esimerkki NEWID-funktiosta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Tämän kyselyn suunnitelma näkyy kuvassa 4, mikä vahvistaa, että SQL Server lisäsi nimenomaisen lajittelu toiminnon tuloksen perusteella.
 Kuva 4: Suunnittele kysely 3
Kuva 4: Suunnittele kysely 3
Jos haluat rivinumerot määritettäväksi satunnaisessa järjestyksessä, kaikin keinoin, sitä tekniikkaa haluat käyttää. Sinun tarvitsee vain olla tietoinen siitä, että siitä aiheutuu lajittelukustannukset.
Alikyselyn käyttäminen
Voit myös käyttää vakioon perustuvaa alakyselyä ikkunan järjestyslausekkeena (esim. ORDER BY (VALITSE ”Ei tilaus”)). Myös tämän ratkaisun kanssa SQL Serverin optimoija tunnistaa, että tilauksen merkitystä ei ole, eikä siksi aseta tarpeetonta lajittelua tai rajoita tallennusmoottorin valintoja sellaisiin, joiden on taattava tilaus. Yritä suorittaa seuraava kysely esimerkkinä:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Saat saman suunnitelman kuin aiemmin kuvassa 3.
Yksi suurimmista eduista Tämän tekniikan avulla voit lisätä oman henkilökohtaisen kosketuksesi.Ehkä pidät todella NULL-tiedostoista:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Ehkä todella pidät tietystä numerosta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Ehkä haluat lähettää jollekulle viestin:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Sinä ymmärrät.
Suoritettava, mutta hankala
On olemassa pari tekniikkaa, jotka toimivat, mutta ovat hieman hankalia. Yksi on määritellä vakion perusteella lausekkeelle sarake-alias ja käyttää sitten kyseistä sarakkeen aliasta ikkunoiden järjestyselementtinä. Voit tehdä tämän joko taulukkolausekkeella tai CROSS APPLY -operaattorin ja taulukon arvon rakentajan kanssa. Tässä on esimerkki jälkimmäisestä:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Saat saman suunnitelman kuin aiemmin kuvassa 3.
Toinen vaihtoehto on käyttää muuttujaa ikkunoiden järjestyselementtinä:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Tämä kysely saa myös aiemmin kuvassa 3 esitetyn suunnitelman.
Entä jos käytän omaa UDF: ää ?
Saatat ajatella, että oman vakion palauttavan UDF: n käyttäminen voi olla hyvä valinta ikkunan järjestyselementtinä, kun haluat epämääräistä järjestystä, mutta se ei ole. Tarkastellaan esimerkkinä seuraavaa UDF-määritelmää:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Yritä käyttää UDF: ää ikkunoiden järjestyslausekkeena, kuten näin (kutsumme tätä kyselyksi 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Ennen SQL Server 2019: tä (tai rinnakkaista yhteensopivuustasoa < 150) käyttäjän määrittelemät toiminnot arvioidaan riviä kohden . Vaikka he palauttaisivat vakion, he eivät pääse linjaan. Näin ollen toisaalta voit käyttää sellaista UDF: ää ikkunoiden tilauselementtinä, mutta toisaalta tämä johtaa eräänlaiseen rangaistukseen. Tämä vahvistetaan tutkimalla kyselyn suunnitelma kuvan 5 mukaisesti.
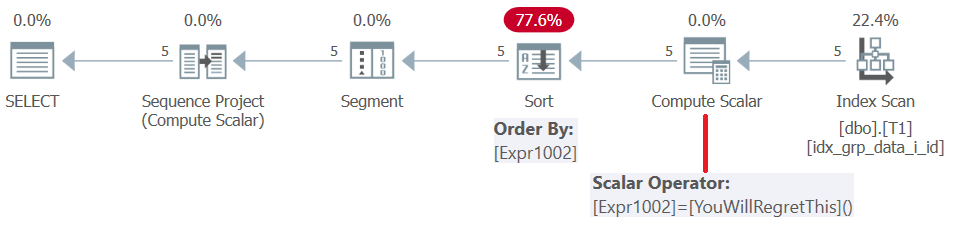 Kuva 5: Kyselyn 4 suunnitelma
Kuva 5: Kyselyn 4 suunnitelma
Alkaen SQL Server 2019: stä, yhteensopivustasolla > = 150 tällaiset käyttäjän määrittelemät toiminnot viivat, mikä on enimmäkseen hieno asia, mutta tapauksessamme johtaa virheeseen:
Toiminnot, aggregaatit ja funktioiden SEURAAVA ARVO eivät tue vakioita ORDER BY -lausekkeen lausekkeina.
Joten UDF: n käyttäminen vakio ikkunan tilauselementtinä joko pakottaa lajittelun tai virheen riippuen käyttämästäsi SQL Server -versiosta ja tietokannan yhteensopivuustasosta. Lyhyesti sanottuna, älä tee tätä.
Osioitujen rivien numerot epädeterministisessä järjestyksessä
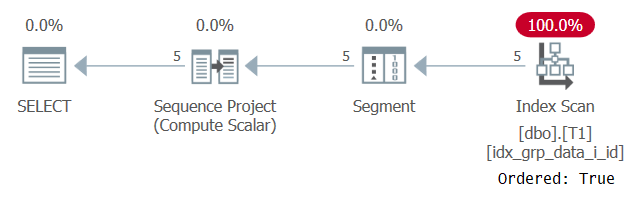
Epädeterministiseen järjestykseen perustuvien osioitujen rivinumeroiden yleinen käyttötapa on palauttaa mikä tahansa rivi ryhmää kohden. Ottaen huomioon, että tässä skenaariossa on määritelmän mukaan osiointielementti, luulet, että tällaisessa tapauksessa turvallinen tekniikka olisi käyttää ikkunan osiointielementtiä myös ikkunoiden järjestyselementtinä. Ensimmäisessä vaiheessa lasketaan rivinumerot näin:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Tämän kyselyn suunnitelma on esitetty kuvassa 6.
 Kuva 6: Suunnitelma kyselylle 5
Kuva 6: Suunnitelma kyselylle 5
Syy siihen, että tukihakemisto skannataan Järjestetty: Tosi-ominaisuudella, johtuu siitä, että SQL Serverin on käsiteltävä kunkin osion rivejä yksikkö. Näin on ennen suodatusta. Jos suodatat vain yhden rivin kullekin osiolle, sinulla on vaihtoehdoina sekä tilaus- että hash-algoritmit.
Toinen vaihe on sijoittaa kysely rivinumerolaskennalla taulukko-lausekkeeseen ulompi kysely suodattaa rivit rivillä numero 1 jokaisessa osiossa, kuten näin:
Teoriassa tämän tekniikan oletetaan olevan turvallinen, mutta Paul White löysi virheen, joka osoittaa, että tätä menetelmää käyttämällä voit saada määritteitä eri lähdekentät palautetulla tulosrivillä osiota kohti. Toimintoon perustuvan ajonvakion tai vakioon perustuvan alalausekkeen käyttäminen, koska tilauselementti näyttää olevan turvallinen myös tässä tilanteessa, joten varmista, että käytät sen sijaan seuraavaa ratkaisua:
Kukaan kulkee tällä tavalla ilman lupaani
Yritä laskea rivinumeroiden lukeminen epädeterministisen järjestyksen perusteella on yleinen tarve. Olisi ollut hienoa, jos T-SQL yksinkertaisesti tekisi ikkunoiden järjestyslausekkeen valinnaiseksi ROW_NUMBER-funktiolle, mutta ei. Jos ei, olisi ollut hienoa, jos se ainakin sallisi vakion käyttämisen tilauselementtinä, mutta se ei myöskään ole tuettu vaihtoehto.Mutta jos kysyt hienosti vakioon perustuvan alikyselyn tai funktioon perustuvan ajonaikavakion muodossa, SQL Server sallii sen. Nämä ovat kaksi vaihtoehtoa, joista olen mukavin. En todellakaan tunne olosi mukavaksi omituisten virheellisten lausekkeiden kanssa, jotka näyttävät toimivan, joten en voi suositella tätä vaihtoehtoa.