Robotit .txt-tiedosto sisältää ohjeita hakukoneille. Voit estää sitä hakukoneita indeksoimasta tiettyjä verkkosivustosi osia ja antaa hakukoneille hyödyllisiä vinkkejä siitä, miten ne voivat parhaiten indeksoida verkkosivustosi. Robots.txt-tiedostolla on suuri rooli hakukoneoptimoinnissa.
Kun otat robots.txt-tiedostoa käyttöön, pidä mielessä seuraavat parhaat käytännöt:
- Ole varovainen, kun teet muutoksia robots.txt: Tämä tiedosto voi tehdä suurista verkkosivustosi osista hakukoneiden saataville.
- Robots.txt-tiedoston tulisi sijaita verkkosivustosi juuressa (esim.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httptaihttps). - Eri hakukoneet tulkitsevat direktiivejä eri tavalla. Oletusarvoisesti ensimmäinen vastaava direktiivi voittaa aina. Mutta Googlen ja Bingin myötä spesifisyys voittaa.
- Vältä indeksointiviive-direktiivin käyttöä hakukoneissa mahdollisimman paljon.
Mikä on robots.txt-tiedosto?
Robots.txt-tiedosto kertoo hakukoneille verkkosivustosi aktivointisäännöt. Suuri osa SEO: n tekemisestä on oikean signaalin lähettämistä hakukoneille, ja robots.txt on yksi tapa kommunikoida indeksointiasetuksesi hakukoneille.
Olemme nähneet vuonna 2019 melko joitain kehityksiä robots.txt-standardin ympärillä: Google ehdotti laajennusta robottien poissulkemisprotokollalle ja hankki avoimen lähteen sen robots.txt-jäsentimestä.
TL; DR
- Googlen robotit .txt-tulkki on melko joustava ja yllättävän anteeksiantava.
- Jos sekaannusdirektiivejä esiintyy, Google erehtyy turvallisilla puolilla ja olettaa, että osioita tulisi rajoittaa eikä rajoittaa.
Hakukoneet tarkistavat säännöllisesti verkkosivuston robots.txt-tiedoston tarkistaakseen, onko verkkosivuston indeksointiin liittyviä ohjeita. Kutsumme näitä ohjeita direktiiveiksi.
Jos robots.txt-tiedostoa ei ole tai sovellettavia direktiivejä ei ole, hakukoneet indeksoivat koko verkkosivuston.
Vaikka kaikki suuret hakukoneet kunnioittavat robots.txt-tiedosto, hakukoneet voivat jättää robots.txt-tiedoston ohittamatta. Vaikka robots.txt-tiedoston tiedostot ovat vahva signaali hakukoneille, on tärkeää muistaa, että robots.txt-tiedosto on joukko valinnaisia direktiivejä hakukoneille eikä toimeksiantoa.

Robots.txt on arkaluontoisin tiedosto SEO-universumissa. Yksi merkki voi rikkoa kokonaisen sivuston.
robots.txt-tiedoston ympärillä oleva terminologia
Robots.txt-tiedosto on robots-poissulkemisstandardin toteutus, tai sitä kutsutaan myös nimellä robottien poissulkemisprotokolla.
Miksi sinun pitäisi välittää robots.txt-tiedostosta?
Robots.txt-tiedostolla on keskeinen rooli SEO-näkökulmasta. Se kertoo hakukoneille, kuinka he voivat parhaiten indeksoida verkkosivustosi.
Robots.txt-tiedoston avulla voit estää hakukoneita pääsemästä tiettyihin verkkosivustosi osiin, estää päällekkäistä sisältöä ja antaa hakukoneille hyödyllisiä vinkkejä siitä, miten ne voi indeksoida verkkosivustosi tehokkaammin.
Ole kuitenkin varovainen, kun teet muutoksia robots.txt-tiedostoon: tämä tiedosto voi tehdä suurista verkkosivustosi osista hakukoneiden saataville.

Robots.txt-tiedostoa käytetään usein päällekkäisen sisällön vähentämiseen, mikä tappaa sisäisiä linkityksiä, joten ole todella varovainen sen kanssa. Minun neuvoni on käyttää sitä koskaan vain tiedostoihin tai sivuihin, joita hakukoneiden ei pitäisi koskaan nähdä, tai ne voivat vaikuttaa merkittävästi indeksointiin sallimalla ne. Yleisiä esimerkkejä: sisäänkirjautumisalueet, jotka luovat monia eri URL-osoitteita, testialueet tai joissa voi olla useita monipuolisia navigointijärjestelmiä. Ja varmista, että tarkkailet robots.txt-tiedostosi mahdollisten ongelmien tai muutosten varalta.

Suurin osa robots.txt-tiedostoista näkemistäni ongelmista jakautuu kolmeen ryhmään:
- Jokerimerkkien väärinkäsittely. On melko tavallista nähdä sivuston estetyt osat, jotka oli tarkoitus estää. Joskus, jos et ole varovainen, direktiivit voivat myös olla ristiriidassa keskenään.
- Joku, kuten kehittäjä, on tehnyt muutoksen tyhjästä (usein uuden koodin työntämisen yhteydessä) ja muuttanut vahingossa robots.txt-tiedosto ilman sinun tietosi.
- sellaisten direktiivien sisällyttäminen, jotka eivät kuulu robots.txt-tiedostoon. Robots.txt on verkkostandardi, ja sitä on jonkin verran rajoitettu. Usein näen kehittäjien laativan direktiivejä, jotka eivät yksinkertaisesti toimi (ainakaan indeksointirobottien suurimmalle osalle). Joskus se on vaaraton, joskus ei niin paljon.
Esimerkki
Katsotaanpa esimerkki tämän havainnollistamiseksi:
Sinä Juuri verkkokauppasivusto ja kävijät voivat käyttää suodatinta hakeaksesi nopeasti tuotteitasi. Tämä suodatin luo sivuja, jotka näyttävät periaatteessa samaa sisältöä kuin muut sivut. Tämä toimii hyvin käyttäjille, mutta hämmentää hakukoneita, koska se luo päällekkäistä sisältöä.
Et halua, että hakukoneet indeksoivat nämä suodatetut sivut ja tuhlaavat arvokasta aikaa näihin URL-osoitteisiin suodatetulla sisällöllä. Siksi sinun on määritettävä Disallow -säännöt, jotta hakukoneet eivät pääse näihin suodatettuihin tuotesivuihin.
Päällekkäisen sisällön estäminen voidaan tehdä myös ensisijaisella URL-osoitteella tai meta-robotti-tunniste ei kuitenkaan käsittele sitä, että hakukoneet voivat indeksoida vain tärkeitä sivuja.
Kanonisen URL-osoitteen tai meta-robotti-tunnisteen käyttö ei estä hakukoneita indeksoimasta näitä sivuja. Se vain estää hakukoneita näyttämästä näitä sivuja hakutuloksissa. Koska hakukoneilla on rajoitettu aika indeksoida verkkosivustoja, tämä aika tulisi käyttää sivuille, jotka haluat näkyvän hakukoneissa.
Väärin asetettu robots.txt-tiedosto saattaa estää SEO-suorituskykyäsi. Tarkista heti, onko kyse verkkosivustollasi!

Se on hyvin yksinkertainen työkalu, mutta robots.txt-tiedosto voi aiheuttaa paljon ongelmia, jos sitä ei ole määritetty oikein, etenkään suuremmille verkkosivustoille. On erittäin helppoa tehdä virheitä, kuten estää koko sivusto uuden mallin tai CMS: n käyttöönoton jälkeen, tai estää sivuston osia, joiden tulisi olla yksityisiä. Suuremmille verkkosivustoille on erittäin tärkeää varmistaa, että Google indeksoi tehokkaasti, ja hyvin jäsennelty robots.txt-tiedosto on välttämätön työkalu prosessissa.
Sinun on käytettävä aikaa ymmärtääksesi, mitkä sivustosi osat ovat parhaiten poissa Googlelta, jotta he käyttävät mahdollisimman suuren osan resursseistaan indeksoimalla sinulle todella tärkeitä sivuja.
miltä robots.txt-tiedosto näyttää?
Esimerkki siitä, millainen yksinkertainen robots.txt-tiedosto WordPress-verkkosivustolle voi olla näyttävät tältä:
Selitetään robots.txt-tiedoston anatomia yllä olevan esimerkin perusteella:
- User-agent:
user-agentilmaisee haun moottorit seuraaville direktiiveille. -
*: tämä osoittaa, että direktiivit on tarkoitettu kaikille hakukoneille. -
Disallow: tämä on direktiivi, joka ilmoittaa, mihin sisältöönuser-agentei ole pääsyä. -
/wp-admin/: tämä onpath, johon ei pääseuser-agent.
Yhteenvetona: tämä robots.txt-tiedosto kehottaa kaikkia hakukoneita pysymään poissa /wp-admin/ -hakemistosta.
Analysoidaan erilaisia robots.txt-tiedostojen komponentit tarkemmin:
- User-agent
- Estä
- Salli
- Sivustokartta
- Indeksointiviive
robots.txt-tiedoston käyttäjäagentti
Jokaisen hakukoneen tulisi tunnistaa itsensä user-agent. Googlen robotit tunnistavat esimerkiksi Googlebot, esimerkiksi Yahoon robotit Slurp ja Bingin robotit BingBot ja niin edelleen.
user-agent -tietue määrittelee direktiiviryhmän alun. Kaikkia ensimmäisen user-agent – ja seuraavan user-agent -tietueen välissä olevia direktiivejä käsitellään ensimmäisen user-agent.
Direktiivejä voidaan soveltaa tiettyihin käyttäjäagentteihin, mutta niitä voidaan soveltaa myös kaikkiin käyttäjäagentteihin. Tällöin käytetään jokerimerkkiä: User-agent: *.
Estä direktiivi robots.txt-tiedostossa
Voit kertoa hakukoneille, ettei niitä käytetä tietyt tiedostot, sivut tai verkkosivustosi osiot. Tämä tehdään Disallow -direktiivin avulla. Disallow -direktiivin jälkeen seuraa path, jota ei pitäisi käyttää. Jos path -määritystä ei määritetä, direktiivi jätetään huomioimatta.
Esimerkki
Tässä esimerkissä kaikkia hakukoneita kehotetaan olemaan käyttämättä hakemistoa /wp-admin/.
Salli direktiivi robots.txt-tiedostossa
Allow -direktiiviä käytetään torjumaan Disallow -direktiiviä. Google ja Bing tukevat Allow -direktiiviä. Käyttämällä Allow – ja Disallow -direktiivejä yhdessä voit kertoa hakukoneille, että he voivat käyttää tiettyä tiedostoa tai sivua hakemistossa, joka on muuten kielletty. Allow -direktiiviä seuraa path, johon pääsee. Jos path -määritystä ei määritetä, direktiivi jätetään huomioimatta.
Esimerkki
Yllä olevassa esimerkissä kaikki hakukoneet eivät saa käyttää /media/ hakemisto, paitsi tiedosto /media/terms-and-conditions.pdf.
Tärkeää: kun käytetään Allow ja Disallow direktiivejä yhdessä, muista olla käyttämättä jokerimerkkejä, koska tämä voi johtaa ristiriitaisiin direktiiveihin.
Esimerkki ristiriitaisista direktiiveistä
Hakukoneet eivät tiedä mitä tehdä URL-osoitteella . Heille on epäselvää, saako hän käyttää niitä. Kun direktiivit eivät ole Googlelle selkeitä, ne käyttävät vähiten rajoittavaa direktiiviä, mikä tässä tapauksessa tarkoittaa, että ne pääsisivät käyttämään
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt on yksi niistä ominaisuuksista, joiden yleisimmin näen olevan väärin toteutettu, joten se ei estä sitä, mitä he halusivat estää, tai se estää enemmän kuin he odottivat, ja sillä on kielteinen vaikutus heidän verkkosivustoonsa. Robots.txt on erittäin tehokas työkalu, mutta se asetetaan liian usein väärin.
Jokerimerkin käyttäminen *
Jokerimerkkiä voidaan käyttää user-agent -määritelmän lisäksi myös vastaa URL-osoitteita. Yleismerkkiä tukevat Google, Bing, Yahoo ja Ask.
Esimerkki
Yllä olevassa esimerkissä kaikilla hakukoneilla ei ole pääsyä URL-osoitteisiin, joissa on kysymysmerkki (?).

Kehittäjät tai sivuston omistajat näyttävät usein ajattelevan voivansa käyttää kaikenlaisia säännöllisiä lausekkeita robots.txt-tiedostossa, kun taas vain hyvin rajoitettu määrä kuvien vastaavuutta on oikea – esimerkiksi jokerimerkit (
*). .Htaccess-tiedostojen ja robots.txt-tiedostojen välillä näyttää olevan ajoittain sekaannusta.
URL-osoitteen lopun käyttäminen $
URL-osoitteen lopun ilmoittamiseksi voit käyttää dollarin merkkiä ($) path -kohdan lopussa.
Esimerkki
Yllä olevassa esimerkissä hakukoneet eivät saa käyttää kaikkia .php-pääteisiä URL-osoitteita . URL-osoitteet parametreilla, esim. ei kielletä, koska URL-osoite ei pääty .php jälkeen.
Lisää sivustokartta robotteihin. txt
Vaikka robots.txt-tiedosto on keksitty kertomaan hakukoneille, mitä sivuja ei saa indeksoida, robots.txt-tiedostoa voidaan käyttää myös ohjaamaan hakukoneita XML-sivustokarttaan. Google, Bing, Yahoo ja Ask tukevat tätä.
XML-sivustokarttaan tulisi viitata absoluuttisena URL-osoitteena. URL-osoitteen ei tarvitse olla samassa isännässä kuin robots.txt-tiedosto.
Viittaaminen robots.txt-tiedoston XML-sivustokarttaan on yksi parhaista käytännöistä, joita suosittelemme aina tekemään, vaikka olet saattanut jo lähettää XML-sivustokarttasi Google Search Consolessa tai Bing Webmaster Toolsissa. Muista, että hakukoneita on enemmän.
Huomaa, että robots.txt-tiedostossa on mahdollista viitata useisiin XML-sivustokarttoihin.
Esimerkkejä
Useita Robots.txt-tiedostoon määritetyt XML-sivustokartat:
Yksi roboteissa määritelty XML-sivustokartta.txt-tiedosto:
Yllä oleva esimerkki kehottaa kaikkia hakukoneita olemaan käyttämättä hakemistoa /wp-admin/ ja että XML-sivustokartta löytyy osoitteesta
Comments are preceded by a # ja voi joko sijoitetaan linjan alkuun tai samalle linjalle annetun direktiivin jälkeen. Kaikki # -kohdan jälkeen ohitetaan. Nämä kommentit on tarkoitettu vain ihmisille.
Esimerkki 1
Esimerkki 2
Yllä olevat esimerkit välittävät saman viestin.
Indeksointiviive robots.txt-tiedostossa
Crawl-delay -direktiivi on epävirallinen direktiivi, jota käytetään estämään palvelimien ylikuormitus liian monilla pyynnöillä. Jos hakukoneet pystyvät ylikuormittamaan palvelinta, Crawl-delay -palvelun lisääminen robots.txt-tiedostoon on vain väliaikainen korjaus. Tosiasia on, että verkkosivustosi toimii huonossa isäntäympäristössä ja / tai verkkosivustosi on määritetty väärin, ja sinun on korjattava se mahdollisimman pian.
Tapa, jolla hakukoneet käsittelevät Crawl-delay -tapaa, eroaa toisistaan. Alla kerromme, kuinka suuret hakukoneet käsittelevät sitä.
Indeksoinnin viive ja Google
Googlen indeksointirobotti Googlebot ei tue Crawl-delay -direktiivi, joten älä vaivaudu määrittelemään Googlen indeksointiviivettä.
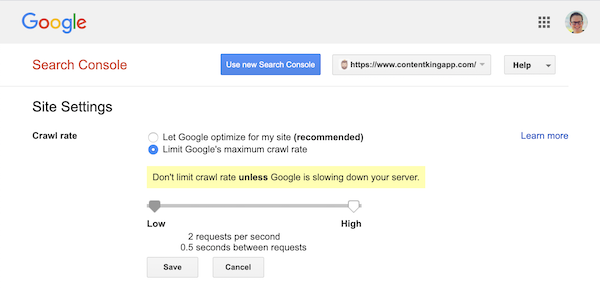
Google kuitenkin tukee indeksointinopeuden (tai ”pyynnön nopeuden”) määrittelyä, jos haluat ) Google Search Consolessa.
- Kirjaudu vanhaan Google Search Consoleen.
- Valitse haluamasi verkkosivusto. haluat määrittää indeksointinopeuden.
- Voit säätää vain yhtä asetusta:
Crawl rateliukusäätimellä, jolla voit asettaa ensisijaisen indeksointinopeuden. indeksointinopeudeksi on asetettu ”Anna Googlen optimoida sivustoni (suositus)”.
Tältä näyttää Google Search Consolessa:
Indeksointiviive ja Bing, Yahoo ja Yandex
Bing, Yahoo ja Yandex kaikki tukevat Crawl-delay -direktiivi verkkosivuston indeksoinnin kuristamiseksi. Heidän tulkintansa indeksointiviiveestä on kuitenkin hieman erilainen, joten muista tarkistaa heidän dokumentaationsa:
- Bing ja Yahoo
- Yandex
Crawl-delay -direktiivi tulisi sijoittaa heti Disallow – tai Allow -direktiivien jälkeen.
Esimerkki:
Indeksointiviive ja Baidu
Baidu ei tue crawl-delay -direktiiviä, mutta Baidu Webmaster Tools -tili on mahdollista rekisteröidä jonka avulla voit hallita indeksointitiheyttä, kuten Google Search Consolessa.
Milloin robots.txt-tiedostoa käytetään?
Suosittelemme aina käyttämään robots.txt-tiedostoa. Sillä ei ole mitään haittaa, ja se on loistava paikka antaa hakukoneiden direktiivejä siitä, miten he voivat parhaiten indeksoida verkkosivustosi.

Robots.txt-tiedosto voi olla hyödyllinen estämään tiettyjä sivustosi alueita tai asiakirjoja indeksoimasta. Esimerkkejä ovat esimerkiksi lavastussivusto tai PDF-tiedostot. Suunnittele huolellisesti, mitä hakukoneiden on indeksoitava, ja pidä mielessä, että robots.txt-tiedostoon pääsemättömäksi tehty sisältö saattaa edelleen löytyä hakukoneiden indeksoijilta, jos siihen on linkki verkkosivuston muilta alueilta.
Robots.txt parhaat käytännöt
Robots.txt-sovelluksen parhaat käytännöt luokitellaan seuraavasti:
- Sijainti ja tiedostonimi
- Etujärjestys
- Vain yksi direktiiviryhmä robottia kohti
- Ole mahdollisimman tarkka
- Kaikkien robottien direktiivit sisältäen myös ohjeet tietylle robotille
- Robots.txt-tiedosto kullekin (ala) toimialueelle.
- Ristiriitaiset ohjeet: robots.txt vs. Google Search Console
- Seuraa robots.txt-tiedostoa
- Älä käytä noindexiä robots.txt-tiedostossasi
- Estä UTF-8 BOM robots.txt-tiedostossa
Sijainti ja tiedostonimi
Robots.txt-tiedosto tulee aina sijoittaa e root verkkosivustolta (isännän ylätason hakemistossa) ja kantaa tiedostonimi robots.txt, esimerkiksi: . Huomaa, että robots.txt-tiedoston URL-osoite on, kuten mikä tahansa muu URL, isot ja pienet kirjaimet.
Jos robots.txt-tiedostoa ei löydy oletussijainnista, hakukoneet olettavat, ettei direktiivejä ole, ja indeksoivat verkkosivustosi.
Etujärjestys
On tärkeää huomata, että hakukoneet käsittelevät robots.txt-tiedostoja eri tavalla. Oletusarvoisesti ensimmäinen vastaava direktiivi voittaa aina.
Google- ja Bing-spesifisyys kuitenkin voittaa. Esimerkiksi: Allow -direktiivi voittaa Disallow -direktiivin, jos sen merkin pituus on pidempi.
Esimerkki
Kaikkien hakukoneiden, Google ja Bing mukaan lukien, esimerkki ei saa käyttää hakemistoa /about/, paitsi alihakemistoa /about/company/.
Esimerkki
Yllä olevassa esimerkissä kaikilla hakukoneilla, paitsi Google ja Bing, ei ole pääsyä hakemistoon /about/. Se sisältää hakemiston /about/company/.
Google ja Bing saavat käyttää, koska Allow -direktiivi on pidempi kuin Disallow -direktiivi.
Vain yksi direktiiviryhmä robottia kohti
Voit määrittää vain yhden direktiiviryhmän hakukonetta kohti. Useiden direktiiviryhmien käyttäminen yhdelle hakukoneelle hämmentää niitä.
Ole mahdollisimman tarkka
Disallow -direktiivi laukaisee osittaiset vastaavuudet hyvin. Ole mahdollisimman tarkka määritellessäsi Disallow -direktiiviä, jotta estät tahattoman tiedostojen käytön estämisen.
Esimerkki:
Yllä oleva esimerkki ei salli hakukoneiden pääsyä:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Kaikkien robottien direktiivit ja myös ohjeet tietylle robotille
Robotille vain yksi direktiiviryhmä on voimassa. Jos kaikkia robotteja varten tarkoitettuja direktiivejä noudatetaan tietyn robotin direktiiveillä, otetaan huomioon vain nämä erityisdirektiivit. Jotta tietty robotti noudattaa myös kaikkien robottien direktiivejä, sinun on toistettava nämä direktiivit kyseiselle robotille.
Katsotaanpa esimerkkiä, joka tekee tämän selväksi:
Esimerkki
Jos et halua, että googlebot käyttää /secret/ ja /not-launched-yet/, sinun on toistettava nämä direktiivit kohdalle googlebot erityisesti:
Huomaa, että robots.txt-tiedosto on julkisesti saatavilla. Sivuston osien kieltäminen siellä voi olla hyökkäysvektori ihmisillä, joilla on ilkeä tahallisuus.

Robots.txt voi olla vaarallinen. Et vain kerro hakukoneille, mihin et halua heidän näyttävän, vaan kerrot ihmisille, mihin piilotat likaiset salaisuutesi.
Robots.txt-tiedosto kullekin (ala) toimialueelle
Vain Robots.txt-direktiivit sovelletaan (ala) verkkotunnukseen, jossa tiedosto on isännöity.
Esimerkkejä
pätee tiedostoon , mutta ei tai
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Rakensimme robots.txt-muutosten seurannan ja hälytykset tästä syystä.
Näemme sen koko ajan: robots.txt-tiedostot muuttuvat tietämättä digitaalista markkinointia tiimi. Älä ole kyseinen henkilö. Aloita robots.txt-tiedostosi seuranta, niin saat ilmoituksia, kun se muuttuu!
Älä käytä noindex-tiedostoa robots.txt-tiedostossa
Vuosien ajan Google suositteli jo avoimesti epävirallisen noindex-direktiivin käyttöä. Google lopetti kuitenkin sen tukemisen 1. syyskuuta 2019 lähtien.
Epävirallinen noindex-direktiivi ei koskaan toiminut Bingissä, kuten Frédéric Dubut vahvisti tässä twiitissä:
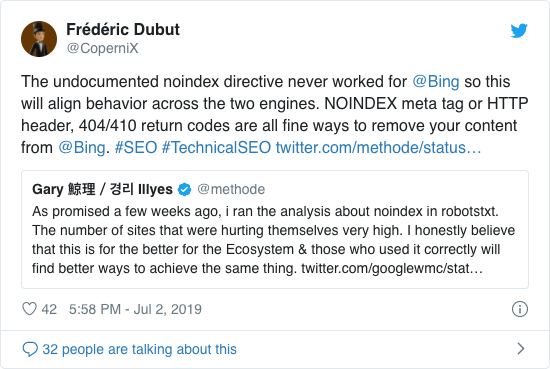
Paras tapa ilmoittaa hakukoneille, että sivuja ei pitäisi indeksoida, on käyttää metarobotteja tai X-Robots-tagia .
Estä UTF-8 BOM robots.txt-tiedostossa
BOM tarkoittaa tavujärjestysmerkkiä, näkymätöntä merkkiä tiedosto, jota käytetään tekstitiedoston Unicode-koodauksen osoittamiseen.
Vaikka Google väittää jättävänsä huomiotta valinnaisen Unicode-tavutilauksen merkinnän robots.txt-tiedoston alussa, suosittelemme estämään ”UTF-8 BOM”, koska olemme nähneet sen aiheuttavan ongelmia hakukoneet käyttävät robots.txt-tiedostoa.
Vaikka Google sanoo pystyvänsä käsittelemään sitä, tässä on kaksi syytä estää UTF-8 BOM:
- Älä et halua olla epäselvää hakukoneiden indeksoinnista.
- Siellä on muitakin hakukoneita, jotka eivät välttämättä ole yhtä anteeksiantavia kuin Google väittää olevansa.
Esimerkkejä Robots.txt-tiedostoista
Tässä luvussa käsitellään monenlaisia robots.txt-tiedostoesimerkkejä:
- Salli kaikille robotteille pääsy kaikkeen
- Estä kaikkien robottien pääsy kaikkeen
- Kaikilla Google-robotteilla ei ole pääsyä
- Kaikilla Google-roboteilla, lukuun ottamatta Googlebot-uutisia, ei ole pääsyä
- Googlebotilla ja Slurpilla ei ole pääsyä
- Kaikilla robotteilla ei ole pääsyä kahteen hakemistot
- Kaikilla robotteilla ei ole pääsyä yhteen tiettyyn tiedostoon
- Googlebotilla ei ole pääsyä tiedostoon / admin / ja Slurpilla ei ole pääsyä kansioon / private /
- Robots.txt-tiedosto WordPressille
- Robots.txt-tiedosto Magentolle
Salli kaikille robotteille pääsy kaikkeen
On monia tapoja kertoa hakukoneille, että he voivat käyttää kaikkia tiedostoja:
Tai jos sinulla on tyhjä robots.txt-tiedosto tai ei lainkaan robots.txt-tiedostoa.
Estä kaikkien robottien pääsy kaikkeen
Esimerkki Alla oleva robots.txt kertoo kaikille hakukoneille, että niitä ei tule käyttää koko sivustoa:
Huomaa, että vain YKSI ylimääräinen merkki voi tehdä kaiken eron.
Kaikilla Google-roboteilla ei ole pääsyä
Huomaa, että kun estät Googlebotin, tämä koskee kaikkia Googleboteja. Tämä sisältää Google-robotit, jotka etsivät esimerkiksi uutisia (googlebot-news) ja kuvia (googlebot-images).
Kaikki Google-botit, lukuun ottamatta Googlebot-uutisia, eivät voi käyttää
Googlebotilla ja Slurpilla ei ole pääsyä
Kaikilla robotteilla ei ole pääsyä kahteen hakemistoon
Kaikilla robotteilla ei ole pääsyä yhteen tiettyyn tiedostoon
Googlebotilla ei ole pääsyä / admin / ja Slurpilla ei ole pääsyä kohteisiin / private /
Robots.txt tiedosto WordPressille
Alla oleva robots.txt-tiedosto on optimoitu erityisesti WordPressille olettaen, että:
- Et halua, että järjestelmänvalvojaosasi indeksoidaan.
- Et halua, että sisäiset hakutulossivusi indeksoidaan.
- Et halua indeksoida tagisi ja kirjoittajasi sivuja.
- Et ’ t haluat, että 404-sivusi indeksoidaan.
Huomaa, että tämä robots.txt-tiedosto toimii useimmissa tapauksissa, mutta sinun on aina mukautettava sitä ja testattava sen varmistamiseksi, että se koskee tarkka tilanne.
Robots.txt-tiedosto Magentoa varten
Alla oleva robots.txt-tiedosto on optimoitu erityisesti Magentoa varten, ja se tekee sisäiset hakutulokset, kirjautumissivut, istuntotunnisteet ja suodatetut tulokset sarjat, jotka sisältävät price, color, material ja size ehtoja, joihin indeksointirobotit eivät pääse.
Huomaa, että tämä robots.txt-tiedosto toimii useimmissa Magento-kaupoissa, mutta sinä tulisi aina säätää ja testata sen varmistamiseksi, että se soveltuu juuri sinun tilanteeseesi.
Etsin silti aina estää sisäiset hakutulokset robots.txt-tiedostossa millä tahansa sivustolla, koska tämäntyyppiset haku-URL-osoitteet ovat rajattomia ja loputtomia välilyöntejä. Googlebotilla on paljon potentiaalia indeksointirobotille.
Mitkä ovat robots.txt-tiedoston rajoitukset?
Robots.txt-tiedosto sisältää direktiivejä
Vaikka haku noudattaa hyvin robots.txt-tiedostoa moottorit, se on edelleen direktiivi eikä mandaatti.
Sivut näkyvät edelleen hakutuloksissa
Sivut, joihin robotit eivät pääse hakukoneille.txt, mutta heillä on linkkejä niihin, voivat silti näkyä hakutuloksissa, jos ne on linkitetty indeksoidulta sivulta. Esimerkki tältä:

Nämä URL-osoitteet on mahdollista poistaa Googlesta Google Search Consolen URL-osoitteiden poistotyökalun avulla. Huomaa, että nämä URL-osoitteet ”piilotetaan” vain väliaikaisesti. Jotta ne pysyisivät Googlen tulossivujen ulkopuolella, sinun on lähetettävä pyyntö piilottaa URL-osoitteet 180 päivän välein.

Estä ei-toivotut ja todennäköisesti haitalliset tytäryhtiöiden käänteiset linkit robots.txt-tiedoston avulla. Älä käytä robots.txt-tiedostoa yrittäessäsi estää hakukoneiden indeksoimasta sisältöä, koska tämä väistämättä epäonnistuu. Käytä sen sijaan robottidirektiiviä noindex tarvittaessa.
Robots.txt-tiedosto on välimuistissa jopa 24 tuntia
Google on ilmoittanut, että robotit .txt-tiedosto välimuistissa on yleensä jopa 24 tuntia. On tärkeää ottaa tämä huomioon, kun teet muutoksia robots.txt-tiedostoon.
On epäselvää, miten muut hakukoneet käsittelevät robots.txt-tiedoston välimuistia. , mutta yleensä on parasta välttää robots.txt-tiedoston välimuistiin tallentaminen av oid-hakukoneet vievät muutosta nopeammin kuin on välttämätöntä.
Robots.txt-tiedoston koko
Robots.txt-tiedostoille Google tukee tällä hetkellä 500 kibibyten tiedostokokorajoitusta (512 kilotavua). Tämän suurimman tiedostokoon jälkeinen sisältö voidaan jättää huomiotta.
On epäselvää, onko muilla hakukoneilla enimmäiskoko robots.txt-tiedostoille.
Usein kysytyt kysymykset robots.txt-tiedostosta
🤖 Miltä robots.txt-esimerkki näyttää?
Tässä on esimerkki robots.txt-tiedoston sisällöstä: User-agent: * Disallow:. Tämä kertoo kaikille indeksointiroboteille, että he voivat käyttää kaikkea.
⛔ Mitä Disallow all tekee robots.txt-tiedostossa?
Kun asetat robots.txt-tiedoston arvoksi ”Disallow all”, olet periaatteessa kehotetaan kaikkia indeksointirobotteja pitämään poissa. Yksikään indeksointirobotti, myös Google, ei saa käyttää sivustoasi. Tämä tarkoittaa, että he eivät voi indeksoida ja luokitella sivustoasi. Tämä johtaa orgaanisen liikenteen huomattavaan vähenemiseen.
✅ Mitä kaikki sallivat tehdä robots.txt-tiedostossa?
Kun asetat robots.txt-tiedoston asetukseksi Salli kaikki, kerrot jokaiselle indeksoijalle, että he voivat käyttää kaikkia sivuston URL-osoitteita. Käyttöönottoa koskevia sääntöjä ei yksinkertaisesti ole. Huomaa, että tämä vastaa tyhjää robots.txt-tiedostoa tai ei lainkaan robots.txt-tiedostoa.
🤔 Kuinka tärkeä robots.txt-tiedosto on hakukoneoptimoijalle?
yleensä robots.txt-tiedosto on erittäin tärkeä SEO-tarkoituksiin. Suuremmille verkkosivustoille robots.txt on välttämätöntä, jotta hakukoneille annetaan erittäin selkeät ohjeet siitä, mihin sisältöön ei saa päästä.