Aロボット.txtファイルには、検索エンジンのディレクティブが含まれています。これを使用して、検索エンジンがWebサイトの特定の部分をクロールするのを防ぎ、検索エンジンがWebサイトを最適にクロールする方法に関する役立つヒントを提供できます。 robots.txtファイルはSEOで大きな役割を果たします。
robots.txtを実装するときは、次のベストプラクティスに留意してください。
- 変更を加えるときは注意してください。 robots.txt:このファイルを使用すると、ウェブサイトの大部分に検索エンジンからアクセスできなくなる可能性があります。
- robots.txtファイルはウェブサイトのルートにある必要があります(例:
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpまたはhttps)。 - 検索エンジンが異なれば、ディレクティブの解釈も異なります。デフォルトでは、最初に一致するディレクティブが常に優先されます。ただし、GoogleとBingでは、特異性が優先されます。
- 検索エンジンにcrawl-delayディレクティブを使用することはできるだけ避けてください。
とはrobots.txtファイル?
robots.txtファイルは、検索エンジンにWebサイトの活動ルールを伝えます。 SEOを行う上で重要なのは、検索エンジンに適切な信号を送信することです。robots.txtは、クロールの設定を検索エンジンに伝える方法の1つです。
2019年には、かなりの成果が見られました。 robots.txt標準に関するいくつかの開発:Googleは、Robots Exclusion Protocolの拡張を提案し、robots.txtパーサーをオープンソース化しました。
TL; DR
- Googleのロボット.txtインタープリターは非常に柔軟性があり、驚くほど寛容です。
- 混乱の指示があった場合、Googleは安全側で誤りを犯し、セクションを制限なしではなく制限する必要があると想定します。
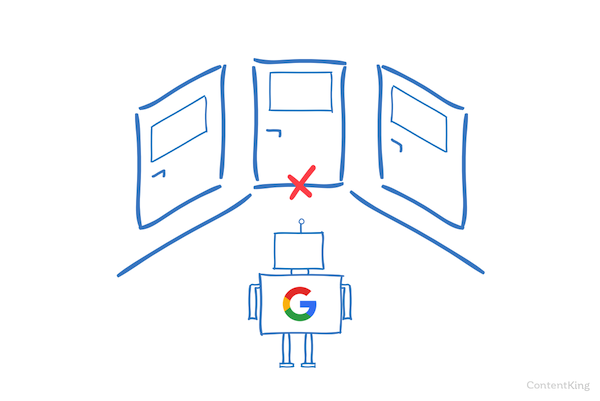
検索エンジンは、ウェブサイトのrobots.txtファイルを定期的にチェックして、ウェブサイトをクロールする手順があるかどうかを確認します。これらの命令をディレクティブと呼びます。
robots.txtファイルが存在しない場合、または該当するディレクティブがない場合、検索エンジンはウェブサイト全体をクロールします。
すべての主要な検索エンジンは尊重しますがrobots.txtファイルの場合、検索エンジンはrobots.txtファイル(の一部)を無視することを選択する場合があります。 robots.txtファイルのディレクティブは検索エンジンへの強力なシグナルですが、robots.txtファイルは必須ではなく、検索エンジンへのオプションのディレクティブのセットであることを覚えておくことが重要です。

robots.txtは、SEOユニバースで最も機密性の高いファイルです。 1つの文字でサイト全体を壊すことができます。
robots.txtファイルに関する用語
robots.txtファイルは、ロボット除外標準の実装であり、別名ロボット除外プロトコル。
robots.txtを気にする必要があるのはなぜですか?
robots.txtは、SEOの観点から重要な役割を果たします。検索エンジンに、ウェブサイトを最適にクロールする方法を説明します。
robots.txtファイルを使用すると、検索エンジンがウェブサイトの特定の部分にアクセスするのを防ぎ、コンテンツの重複を防ぎ、検索エンジンに役立つヒントを提供できます。ウェブサイトをより効率的にクロールできます。
robots.txtに変更を加える場合は注意が必要です。ただし、このファイルを使用すると、ウェブサイトの大部分に検索エンジンがアクセスできなくなる可能性があります。

Robots.txtは、重複コンテンツを減らすために頻繁に使用されます。内部リンクを殺すので、本当に注意してください。私のアドバイスは、検索エンジンが決して見るべきではない、または許可されることによってクロールに大きな影響を与える可能性があるファイルまたはページにのみ使用することです。一般的な例:多くの異なるURLを生成するログイン領域、テスト領域、または複数のファセットナビゲーションが存在する可能性がある場所。また、robots.txtファイルで問題や変更がないかどうかを確認してください。

robots.txtファイルで見られる問題の大部分は、次の3つのバケットに分類されます。
- ワイルドカードの取り扱いの誤り。遮断されることを意図したサイトの一部が遮断されるのはかなり一般的です。注意しないと、ディレクティブが互いに競合する場合があります。
- 開発者などの誰かが突然変更を加え(多くの場合、新しいコードをプッシュするとき)、誤って変更しました。あなたの知らないうちにrobots.txt。
- robots.txtファイルに属していないディレクティブが含まれています。 Robots.txtはWeb標準であり、多少制限されています。開発者が、単に機能しないディレクティブを作成しているのをよく目にします(少なくともクローラーの大多数にとって)。無害な場合もあれば、それほど害がない場合もあります。
例
これを説明するための例を見てみましょう:
あなたはeコマースWebサイトを運営しており、訪問者はフィルターを使用して製品をすばやく検索できます。このフィルターは、基本的に他のページと同じコンテンツを表示するページを生成します。これはユーザーにとってはうまく機能しますが、重複するコンテンツが作成されるため、検索エンジンが混乱します。
検索エンジンがこれらのフィルタリングされたページにインデックスを付けて、フィルタリングされたコンテンツでこれらのURLに貴重な時間を浪費することは望ましくありません。そのため、検索エンジンがこれらのフィルタリングされた製品ページにアクセスしないように、Disallowルールを設定する必要があります。
重複コンテンツの防止は、正規URLまたはメタロボットタグ。ただし、これらは検索エンジンが重要なページのみをクロールできるようにすることには対応していません。
正規URLまたはメタロボットタグを使用しても、検索エンジンがこれらのページをクロールするのを防ぐことはできません。検索エンジンがこれらのページを検索結果に表示するのを防ぐだけです。検索エンジンはウェブサイトをクロールする時間が限られているので、この時間は検索エンジンに表示したいページに費やす必要があります。
robots.txtファイルが正しく設定されていないと、SEOのパフォーマンスが低下している可能性があります。これがあなたのウェブサイトに当てはまるかどうかをすぐに確認してください!

これは非常にシンプルなツールですが、robots.txtファイルが正しく構成されていないと、特に多くの問題が発生する可能性があります。大規模なWebサイトの場合。新しいデザインやCMSが公開された後にサイト全体をブロックしたり、非公開にする必要のあるサイトのセクションをブロックしなかったりするなど、間違いを犯しやすいです。大規模なウェブサイトの場合、Googleのクロールを効率的に行うことは非常に重要であり、適切に構造化されたrobots.txtファイルはそのプロセスに不可欠なツールです。
サイトのどのセクションを遠ざけるのが最適かを理解するには、時間をかける必要があります。 Googleから、あなたが本当に気にかけているページをクロールするためにできるだけ多くのリソースを費やすようにします。
robots.txtファイルはどのように表示されますか?
WordPressWebサイトの単純なrobots.txtファイルの例次のようになります:
上記の例に基づいてrobots.txtファイルの構造を説明しましょう:
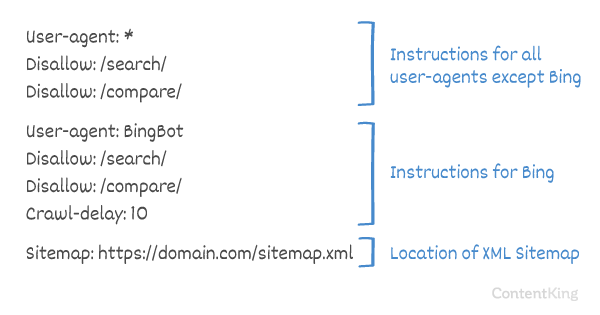
- ユーザーエージェント:
user-agentはどの検索を検索するかを示しますエンジンは、以下のディレクティブを意味します。 -
*:これは、ディレクティブがすべての検索エンジンを対象としていることを示します。 -
Disallow:これは、user-agentがアクセスできないコンテンツを示すディレクティブです。 -
/wp-admin/:これはpathであり、user-agentではアクセスできません。
要約:このrobots.txtファイルは、すべての検索エンジンに/wp-admin/ディレクトリから離れるように指示します。
さまざまなものを分析しましょうrobots.txtファイルのコンポーネントの詳細:
- ユーザーエージェント
- 禁止
- 許可
- サイトマップ
- Crawl-delay
robots.txtのユーザーエージェント
各検索エンジンは、user-agent。 GoogleのロボットはGooglebotとして識別されます。たとえば、YahooのロボットはSlurpとして識別され、BingのロボットはBingBotとして識別されます。など。
user-agentレコードは、ディレクティブのグループの開始を定義します。最初のuser-agentと次のuser-agentレコードの間にあるすべてのディレクティブは、最初のuser-agent。
ディレクティブは特定のユーザーエージェントに適用できますが、すべてのユーザーエージェントに適用することもできます。その場合、ワイルドカードが使用されます:User-agent: *。
robots.txtのディレクティブを禁止する
検索エンジンにアクセスしないように指示できますWebサイトの特定のファイル、ページ、またはセクション。これは、Disallowディレクティブを使用して行われます。 Disallowディレクティブの後には、アクセスしてはならないpathが続きます。 pathが定義されていない場合、ディレクティブは無視されます。
例
この例では、すべての検索エンジンが/wp-admin/ディレクトリにアクセスしないように指示されています。
robots.txtのallowディレクティブ
Allowディレクティブは、Disallowディレクティブを打ち消すために使用されます。 AllowディレクティブはGoogleとBingでサポートされています。 AllowディレクティブとDisallowディレクティブを一緒に使用すると、他の方法では許可されていないディレクトリ内の特定のファイルまたはページにアクセスできることを検索エンジンに伝えることができます。 Allowディレクティブの後には、アクセス可能なpathが続きます。 pathが定義されていない場合、ディレクティブは無視されます。
例
上記の例では、すべての検索エンジンがディレクトリ。ただしファイル/media/terms-and-conditions.pdfを除く。
重要:Allowおよび
ディレクティブを一緒に使用すると、ディレクティブが競合する可能性があるため、ワイルドカードを使用しないでください。
ディレクティブの競合の例
検索エンジンはURLの処理方法を認識しません。アクセスが許可されているかどうかは不明です。ディレクティブがGoogleに明確でない場合、最も制限の少ないディレクティブが使用されます。この場合、実際には
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txtは、私が最もよく見かける機能の1つであり、正しく実装されていないため、ブロックしたいものをブロックしていないか、予想以上にブロックしていて、Webサイトに悪影響を及ぼしています。 Robots.txtは非常に強力なツールですが、正しく設定されていないことがよくあります。
ワイルドカードの使用*
ワイルドカードは、user-agentの定義に使用できるだけでなく、次の目的にも使用できます。一致するURL。ワイルドカードは、Google、Bing、Yahoo、Askでサポートされています。
例
上記の例では、すべての検索エンジンが疑問符を含むURLへのアクセスを許可されていません(?)。

開発者または、サイト所有者は、robots.txtファイルであらゆる種類の正規表現を利用できると考えているようですが、実際に有効なパターンマッチングはごく限られています。たとえば、ワイルドカード(
*)。 .htaccessファイルとrobots.txtファイルの間には時々混乱があるようです。
URLの終わりを使用$
URLの終わりを示すには、ドル記号($)pathの最後。
例
上記の例では、検索エンジンは.phpで終わるすべてのURLにアクセスすることを許可されていません。 。パラメータ付きのURL、例: .phpの後にURLが終了しないため、は許可されません。
サイトマップをロボットに追加します。 txt
robots.txtファイルは、検索エンジンにクロールしないページを指示するために考案されましたが、robots.txtファイルを使用して検索エンジンにXMLサイトマップを指定することもできます。これは、Google、Bing、Yahoo、Askでサポートされています。
XMLサイトマップは絶対URLとして参照する必要があります。 URLはrobots.txtファイルと同じホスト上にある必要はありません。
robots.txtファイルでXMLサイトマップを参照することは、常に行うことをお勧めするベストプラクティスの1つです。 Google SearchConsoleまたはBingWebmasterToolsでXMLサイトマップを既に送信している可能性があります。そこにはもっと多くの検索エンジンがあることを忘れないでください。
robots.txtファイルで複数のXMLサイトマップを参照できることに注意してください。
例
複数robots.txtファイルで定義されているXMLサイトマップ:
ロボットで定義された単一のXMLサイトマップ。txtファイル:
上記の例は、すべての検索エンジンにディレクトリ/wp-admin/にアクセスしないように指示し、XMLサイトマップは
Comments are preceded by a #にあります。行の先頭または同じ行のディレクティブの後に配置します。 #以降はすべて無視されます。これらのコメントは人間のみを対象としています。
例1
例2
上記の例は同じメッセージを伝えます。
robots.txtのクロール遅延
Crawl-delayディレクティブは、リクエストが多すぎるサーバーの過負荷を防ぐために使用される非公式のディレクティブです。検索エンジンがサーバーに過負荷をかける可能性がある場合、robots.txtファイルにCrawl-delayを追加することは一時的な修正にすぎません。実際のところ、ウェブサイトが貧弱なホスティング環境で実行されているか、ウェブサイトが正しく構成されていないため、できるだけ早く修正する必要があります。
検索エンジンがCrawl-delayを処理する方法は異なります。以下では、主要な検索エンジンがそれをどのように処理するかを説明します。
クロール遅延とGoogle
GoogleのクローラーであるGooglebotは、
ディレクティブなので、Googleのクロール遅延の定義に煩わされることはありません。
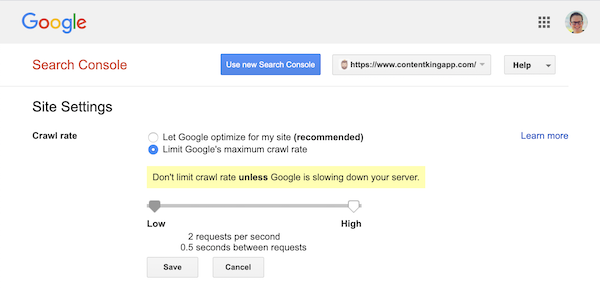
ただし、Googleはクロールレート(または必要に応じて「リクエストレート」)の定義をサポートしています。 )Google SearchConsoleで。
- 古いGoogleSearchConsoleにログオンします。
- Webサイトを選択します。のクロール速度を定義したい。
- 微調整できる設定は
Crawl rateのみで、スライダーを使用して優先クロール速度を設定できます。デフォルトではクロール速度は「Googleに自分のサイトを最適化させる(推奨)」に設定されています。
Google SearchConsoleでは次のように表示されます。
クロール遅延とBing、YahooとYandex
Bing、YahooとYandexすべて
ウェブサイトのクロールを抑制するディレクティブ。ただし、クロール遅延の解釈は少し異なるため、必ずドキュメントを確認してください。
- BingとYahoo
- Yandex
Crawl-delayディレクティブは、DisallowまたはAllowディレクティブの直後に配置する必要があります。
例:
Crawl-delayとBaidu
Baiduはcrawl-delayディレクティブをサポートしていませんが、Baiduウェブマスターツールアカウントをに登録することは可能ですGoogle Search Consoleと同様に、クロールの頻度を制御できます。
robots.txtファイルを使用する場合
常にrobots.txtファイルを使用することをお勧めします。持っていてもまったく害はありません。検索エンジンがウェブサイトを最適にクロールする方法を指示するのに最適な場所です。

robots.txtは、サイトの特定の領域やドキュメントがクロールされてインデックスに登録されないようにするのに役立ちます。例としては、ステージングサイトやPDFなどがあります。検索エンジンでインデックスを作成する必要があるものを慎重に計画し、robots.txtを介してアクセスできなくなったコンテンツが、ウェブサイトの他の領域からリンクされている場合でも、検索エンジンのクローラーによって検出される可能性があることに注意してください。
Robots.txtのベストプラクティス
robots.txtのベストプラクティスは次のように分類されます。
- 場所とファイル名
- 優先順位
- ロボットごとに1つのディレクティブグループのみ
- できるだけ具体的に
- すべてのロボットのディレクティブを含め、特定のロボットのディレクティブも含めます
- 各(サブ)ドメインのRobots.txtファイル。
- 矛盾するガイドライン:robots.txtとGoogle検索コンソール
- robots.txtファイルを監視する
- robots.txtでnoindexを使用しないでください
- robots.txtファイルでUTF-8BOMを防止する
場所とファイル名
robots.txtファイルは常にthに配置する必要がありますe(ホストの最上位ディレクトリにある)Webサイトのrootで、ファイル名robots.txtを付けます。例:。 robots.txtファイルのURLは、他のURLと同様に、大文字と小文字が区別されることに注意してください。
robots.txtファイルがデフォルトの場所に見つからない場合、検索エンジンはディレクティブがないと見なし、ウェブサイトをクロールします。
優先順位
検索エンジンはrobots.txtファイルを異なる方法で処理することに注意することが重要です。デフォルトでは、最初に一致するディレクティブが常に優先されます。
ただし、GoogleとBingでは特異性が優先されます。例:Allowディレクティブは、文字の長さが長い場合、Disallowディレクティブに優先します。
例
上記の例では、GoogleやBingを含むすべての検索エンジンは、サブディレクトリ/about/company/を除いて、/about/ディレクトリへのアクセスを許可されていません。
例
上記の例では、GoogleとBingを除くすべての検索エンジンで、/about/ディレクトリへのアクセスが許可されていません。これには、ディレクトリ/about/company/が含まれます。
Allowディレクティブはより長いため、GoogleとBingはアクセスを許可されます。 Disallowディレクティブ。
ロボットごとに1つのディレクティブグループのみ
検索エンジンごとに定義できるディレクティブのグループは1つだけです。 1つの検索エンジンに複数のディレクティブグループがあると、混乱します。
できるだけ具体的に
Disallowディレクティブは、部分一致でトリガーされます。上手。 Disallowディレクティブを定義するときは、ファイルへのアクセスを意図せず禁止しないように、できるだけ具体的にしてください。
例:
上記の例では、検索エンジンは以下にアクセスできません。
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
すべてのロボットのディレクティブで、特定のロボットのディレクティブも含まれます
ロボットの場合ディレクティブの1つのグループのみが有効です。すべてのロボットを対象とした指令の後に特定のロボットを対象とした指令が続く場合、これらの特定の指令のみが考慮されます。特定のロボットがすべてのロボットのディレクティブにも従うようにするには、特定のロボットに対してこれらのディレクティブを繰り返す必要があります。
これを明確にする例を見てみましょう。
例
googlebotに/secret/と/not-launched-yet/にアクセスさせたくない場合は、googlebot具体的には:
robots.txtファイルは公開されていることに注意してください。そこにあるWebサイトのセクションを禁止すると、悪意のある人々による攻撃ベクトルとして使用される可能性があります。

Robots.txtは危険な場合があります。検索エンジンに見られたくない場所を伝えるだけでなく、汚い秘密を隠す場所を人々に伝えます。
各(サブ)ドメインのRobots.txtファイル
Robots.txtディレクティブのみファイルがホストされている(サブ)ドメインに適用します。
例
は、ただしまたは
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / は対象外
このため、robots.txtの変更の追跡とアラートを作成しました。
私たちは常にそれを確認しています:robots.txtファイルはデジタルマーケティングの知識がなくても変更されますチーム。その人にならないでください。 robots.txtファイルの監視を開始すると、変更時にアラートが受信されるようになりました!
robots.txtでnoindexを使用しないでください
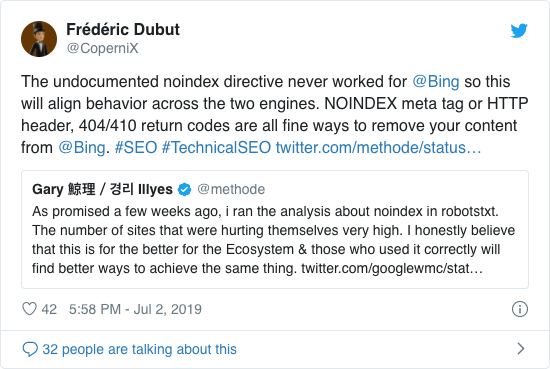
何年もの間、Googleは非公式のnoindexディレクティブの使用を公然と推奨していました。ただし、2019年9月1日の時点で、Googleは完全にサポートを停止しました。
このツイートでFrédéricDubutが確認したように、非公式のnoindexディレクティブはBingでは機能しませんでした:
ページにインデックスを付けるべきではないことを検索エンジンに通知する最良の方法は、メタロボットタグまたはX-Robots-Tagを使用することです。 。
robots.txtファイルでUTF-8BOMを防止する
BOMはバイト順マークを表し、先頭に表示されない文字です。テキストファイルのUnicodeエンコーディングを示すために使用されるファイル。
Googleは、robots.txtファイルの先頭にあるオプションのUnicodeバイト順マークを無視すると述べていますが、「UTF-8 BOM」は、の解釈に問題が発生することがわかっているため、防止することをお勧めします。検索エンジンによるrobots.txtファイル。
Googleはこれに対処できると言っていますが、UTF-8BOMを防ぐ2つの理由は次のとおりです。
- 検索エンジンへのクロールに関する設定について曖昧さを残したくない。
- 他にも検索エンジンがあり、Googleが主張するほど寛容ではない可能性があります。
Robots.txtの例
この章では、robots.txtファイルのさまざまな例について説明します。
- すべてのロボットにすべてへのアクセスを許可する
- すべてのロボットにすべてへのアクセスを許可しない
- すべてのGoogleボットにアクセス権がない
- Googlebotニュースを除くすべてのGoogleボットにアクセス権がない
- GooglebotとSlurpにはアクセス権がありません
- すべてのロボットが2つにアクセスできるわけではありませんディレクトリ
- すべてのロボットが1つの特定のファイルにアクセスできるわけではありません
- Googlebotは/ admin /にアクセスできず、Slurpは/ private /にアクセスできません
- WordPressのRobots.txtファイル
- MagentoのRobots.txtファイル
すべてのロボットにすべてへのアクセスを許可する
複数の方法があります検索エンジンにすべてのファイルにアクセスできることを伝えるには:
または、robots.txtファイルが空であるか、robots.txtがまったくない。
すべてのロボットがすべてにアクセスすることを禁止する
例以下のrobots.txtは、すべての検索エンジンにサイト全体にアクセスしないように指示しています。
1つの余分な文字だけですべての違いを生むことができることに注意してください。
すべてのGoogleボットがアクセスできるわけではありません
Googlebotを禁止する場合、これはすべてのGooglebotに適用されることに注意してください。これには、たとえばニュース(googlebot-news)と画像(googlebot-images)を検索しているGoogleロボットが含まれます。
すべてGooglebotニュースを除くGoogleボットはアクセスできません
GooglebotとSlurpにはアクセス権がありません
すべてのロボットが2つのディレクトリにアクセスできるわけではありません
すべてのロボットが1つの特定のファイルにアクセスできるわけではありません
Googlebotは/にアクセスできませんadmin /およびSlurpは/ private /
Robots.txt WordPress用のファイル
以下のrobots.txtファイルは、次のことを前提として、WordPress用に特別に最適化されています。
- 管理セクションをクロールしたくない。
- 内部検索結果ページをクロールさせたくない。
- タグと作成者ページをクロールさせたくない。
- あなたは404ページをクロールする必要があります。
このrobots.txtファイルはほとんどの場合に機能しますが、常に調整してテストし、自分に適用されることを確認する必要があります。正確な状況。
Magento用のRobots.txtファイル
以下のrobots.txtファイルは、Magento用に特別に最適化されており、内部検索結果、ログインページ、セッションID、フィルタリングされた結果を作成します。 price、color、material、sizeクローラーがアクセスできない基準。
このrobots.txtファイルは、ほとんどのMagentoストアで機能しますが、常に調整してテストし、正確な状況に当てはまるかどうかを確認する必要があります。
これらのタイプの検索URLは無限で無限のスペースであるため、どのサイトでもrobots.txtの内部検索結果をブロックすることを常に検討しています。 Googlebotがクローラートラップに入る可能性はたくさんあります。
robots.txtファイルの制限は何ですか?
Robots.txtファイルにはディレクティブが含まれています
robots.txtは検索で十分に尊重されていますがエンジン、それはまだ指令であり、義務ではありません。
検索結果に引き続き表示されるページ
ロボットが原因で検索エンジンがアクセスできないページ。txtですが、クロールされたページからリンクされている場合は、それらへのリンクが検索結果に表示される可能性があります。これがどのように見えるかの例:

Google Search ConsoleのURL削除ツールを使用して、これらのURLをGoogleから削除することができます。これらのURLは一時的に「非表示」になるだけであることに注意してください。これらのURLをGoogleの結果ページに表示しないようにするには、180日ごとにURLを非表示にするリクエストを送信する必要があります。

robots.txtを使用して、望ましくない、有害である可能性のあるアフィリエイトバックリンクをブロックします。必然的に失敗するため、検索エンジンによるコンテンツのインデックス作成を防ぐためにrobots.txtを使用しないでください。代わりに、必要に応じてrobotsディレクティブnoindexを適用してください。
Robots.txtファイルは最大24時間キャッシュされます
Googleはロボットを示しています.txtファイルは通常最大24時間キャッシュされます。robots.txtファイルに変更を加える場合は、これを考慮することが重要です。
他の検索エンジンがrobots.txtのキャッシュをどのように処理するかは不明です。 、ただし、一般的には、robots.txtファイルをavにキャッシュしないようにするのが最善です。変更を取得できるようになるまでに必要以上に時間がかかるoid検索エンジン。
Robots.txtファイルサイズ
robots.txtファイルの場合Googleは現在、500キロバイトのファイルサイズ制限をサポートしています。 (512キロバイト)。この最大ファイルサイズを超えるコンテンツは無視できます。
他の検索エンジンにrobots.txtファイルの最大ファイルサイズがあるかどうかは不明です。
robots.txtに関するよくある質問
🤖robots.txtの例はどのように見えますか?
これがrobots.txtのコンテンツの例です:ユーザーエージェント:*許可しない:。これにより、すべてのクローラーがすべてにアクセスできるようになります。
⛔robots.txtですべてを禁止する機能
robots.txtを「すべて禁止」に設定すると、次のようになります。基本的に、すべてのクローラーに立ち入り禁止を指示します。Googleを含むクローラーはサイトへのアクセスを許可されません。つまり、サイトをクロール、インデックス登録、ランク付けすることができなくなります。これにより、オーガニックトラフィックが大幅に減少します。
✅robots.txtですべてを許可する機能
robots.txtを「すべて許可」に設定すると、すべてのクローラーにサイト上のすべてのURLにアクセスできるように指示します。エンゲージメントのルールはありません。これは、robots.txtが空であるか、robots.txtがまったくないことと同じであることに注意してください。
🤔SEOにとってrobots.txtはどのくらい重要ですか?
In一般に、robots.txtファイルはSEOの目的にとって非常に重要です。大規模なウェブサイトの場合、robots.txtは、アクセスしないコンテンツについて検索エンジンに非常に明確な指示を与えるために不可欠です。