ROW_NUMBERウィンドウ関数には、明らかなランキングのニーズをはるかに超えた、多数の実用的なアプリケーションがあります。ほとんどの場合、行番号を計算するときは、ある順序に基づいてそれらを計算する必要があり、関数のウィンドウ順序句で目的の順序指定を指定します。ただし、特定の順序で行番号を計算する必要がある場合があります。言い換えれば、非決定論的な順序に基づいています。これは、クエリ結果全体、またはパーティション内で発生する可能性があります。たとえば、結果行への一意の値の割り当て、データの重複排除、グループごとの任意の行の返送などがあります。
非決定論的な順序に基づいて行番号を割り当てる必要があることは、ランダムな順序に基づいて行番号を割り当てる必要があることとは異なることに注意してください。前者の場合、割り当てられる順序や、クエリを繰り返し実行しても同じ行番号が同じ行に割り当てられるかどうかは関係ありません。後者の場合、繰り返し実行すると、どの行にどの行番号が割り当てられるかが変わり続けることが予想されます。この記事では、非決定的な順序で行番号を計算するためのさまざまな手法について説明します。信頼性が高く、最適な手法を見つけることが期待されています。
定数畳み込みに関するヒント、実行時の定数テクニック、そして常に優れた情報源であるPaulWhiteに特に感謝します。
順序が重要な場合
行番号の順序が重要な場合から始めます。
例ではT1というテーブルを使用します。次のコードを使用して、このテーブルを作成し、サンプルデータを入力します。
次のクエリを検討します(クエリ1と呼びます):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
ここでは、列データ列の順序で、列grpで識別される各グループ内に行番号を割り当てる必要があります。システムでこのクエリを実行すると、次の出力が得られました。
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
ここでは、行番号が部分的に決定論的および部分的に非決定論的な順序で割り当てられています。これが意味するのは、同じパーティション内で、datacol値が大きい行がより大きな行番号値を取得するという保証があるということです。ただし、datacolはgrpパーティション内で一意ではないため、同じgrpおよびdatacol値を持つ行間での行番号の割り当ての順序は非決定的です。これは、ID値が2と11の行の場合です。どちらもgrp値Aとdatacol値50を持っています。システムでこのクエリを初めて実行したとき、ID2の行は行番号2を取得しました。 ID 11の行は行番号3を取得しました。これがSQLServerで実際に発生する可能性を気にしないでください。クエリを再度実行すると、理論的には、ID 2の行に行番号3を割り当て、ID11の行に行番号2を割り当てることができます。
行番号に基づいて割り当てる必要がある場合完全に決定論的な順序で、基になるデータが変更されない限り、クエリの実行全体で繰り返し可能な結果を保証するために、ウィンドウのパーティション分割句と順序付け句の要素の組み合わせを一意にする必要があります。この場合、タイブレーカーとして列IDをウィンドウ順序句に追加することでこれを実現できます。その場合、OVER句は次のようになります。
OVER (PARTITION BY grp ORDER BY datacol, id)
いずれにせよ、クエリ1のように意味のある順序指定に基づいて行番号を計算する場合、SQLServerはウィンドウのパーティション分割要素と順序付け要素の組み合わせによって順序付けられた行。これは、インデックスから事前に順序付けられたデータをプルするか、データを並べ替えることによって実現できます。現時点では、クエリ1のROW_NUMBER計算をサポートするインデックスがT1にないため、SQLServerはデータの並べ替えを選択する必要があります。これは、図1に示すクエリ1の計画で確認できます。
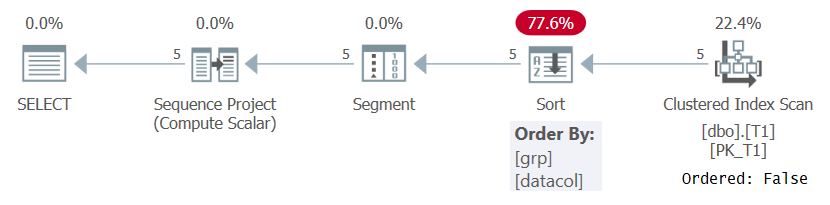 図1:サポートインデックスのないクエリ1の計画
図1:サポートインデックスのないクエリ1の計画
プランがOrdered:Falseプロパティを使用してクラスター化インデックスからデータをスキャンすることに注意してください。これは、スキャンがインデックスキー順に並べられた行を返す必要がないことを意味します。クラスター化インデックスがここで使用されているのは、キーの順序ではなく、クエリをカバーしているからです。次に、プランは並べ替えを適用し、追加のコスト、N Log Nスケーリング、および応答時間の遅延をもたらします。セグメント演算子は、行がパーティションの最初であるかどうかを示すフラグを生成します。最後に、Sequence Projectオペレーターは、各パーティションに1から始まる行番号を割り当てます。
並べ替えの必要性を回避したい場合は、パーティション化要素と順序付け要素に基づくキーリストと、カバー要素に基づくインクルードリストを使用してカバーインデックスを作成できます。私はこのインデックスをPOCインデックス(パーティション分割、順序付け、カバー用)と考えるのが好きです。クエリをサポートするPOCの定義は次のとおりです。
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
クエリ1を再度実行します:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
この実行の計画を図2に示します。
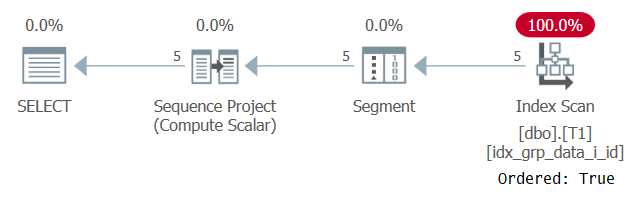 図2:POCインデックスを使用したクエリ1の計画
図2:POCインデックスを使用したクエリ1の計画
今回は、プランがOrdered:Trueプロパティを使用してPOCインデックスをスキャンすることに注意してください。これは、スキャンにより、行がインデックスキーの順序で返されることが保証されることを意味します。ウィンドウ関数が必要とするように、データはインデックスから事前に並べ替えられてプルされるため、明示的な並べ替えは必要ありません。この計画のスケーリングは線形であり、応答時間は良好です。
順序が重要でない場合
完全に非決定的な行番号を割り当てる必要がある場合は、少し注意が必要です。このような場合に実行したいのは、ウィンドウの順序句を指定せずにROW_NUMBER関数を使用することです。まず、SQL標準でこれが許可されているかどうかを確認します。ウィンドウの構文規則を定義する標準の関連部分を次に示します。関数:
項目6に関数< ntile function >、リードまたはラグ関数>、<ランク関数タイプ>またはROW_NUMBERの次に、項目6aは、関数< ntile function >、<について述べています。リードまたはラグ関数>、RANKまたはDENSE_RANKウィンドウ順序句はb eプレゼント。 ROW_NUMBERにウィンドウ順序句が必要かどうかを示す明確な表現はありませんが、項目6での関数の言及と、6aでの省略は、この句がこの関数のオプションであることを意味している可能性があります。 RANKやDENSE_RANKのような関数がウィンドウの順序句を必要とする理由は明らかです。これらの関数はタイの処理に特化しており、タイは順序指定がある場合にのみ存在するためです。ただし、ROW_NUMBER関数がオプションのウィンドウ順序句からどのように役立つかは確かにわかります。
それでは、試してみて、SQLServerでウィンドウ順序なしで行番号を計算してみましょう。
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
この試行により、次のエラーが発生します。
関数 “ROW_NUMBER” ORDERBYを含むOVER句が必要です。
実際、SQL ServerのROW_NUMBER関数のドキュメントを確認すると、次のテキストが表示されます。
ORDER BY句は、指定されたパーティション内で行に一意のROW_NUMBERが割り当てられる順序を決定します。これは必須です。」
したがって、SQLServerのROW_NUMBER関数には明らかにウィンドウの順序句が必須です。ちなみに、これはOracleにも当てはまります。
理由がよくわからないと言わざるを得ません。この要件の背後にあります。クエリ1のように、部分的に非決定的な順序に基づいて行番号を定義できることを忘れないでください。では、非決定性を完全に許可しないのはなぜですか。おそらく、私が考えていない理由がいくつかあります。そのような理由が考えられる場合は、共有してください。
とにかく、ウィンドウの順序句が必須であるため、順序を気にしない場合は、次のいずれかを指定できます。注文。このアプローチの問題は、クエリされたテーブルからいくつかの列で注文した場合、不必要なパフォーマンスの低下を伴う可能性があることです。サポートするインデックスが設定されていない場合は、明示的な並べ替えの料金を支払う必要があります。サポートするインデックスが設定されている場合、ストレージエンジンをインデックス順序スキャン戦略に制限します(インデックスリンクリストに従います)。インデックス順序スキャンと割り当て順序スキャン(IAMページに基づく)のどちらを選択するかで順序が重要でない場合に通常あるように、柔軟性を高めることはできません。
試してみる価値のあるアイデアの1つウィンドウの順序句で1などの定数を指定することです。サポートされている場合は、オプティマイザーがすべての行の値が同じであることを認識できるほどスマートであることが望まれます。したがって、実際の順序の関連性はなく、したがって、並べ替えやインデックスの順序スキャンを強制する必要はありません。このアプローチを試みるクエリは次のとおりです。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
残念ながら、SQLServerはこのソリューションをサポートしていません。次のエラーが生成されます。
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句式として整数インデックスをサポートしていません。
明らかに、SQL Serverは、ウィンドウのorder句で整数定数を使用している場合、プレゼンテーションのORDERで整数を指定する場合のように、SELECTリスト内の要素の順序位置を表すと想定しています。 BY句。その場合、試す価値のある別のオプションは、次のように整数以外の定数を指定することです。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
このソリューションもサポートされていないことが判明しました。 SQLServerは次のエラーを生成します。
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句式として定数をサポートしていません。
どうやら、ウィンドウの順序句はいかなる種類の定数もサポートしていません。
これまで、SQLServerでのROW_NUMBER関数のウィンドウの順序の関連性について次のことを学びました。
- ORDERBYが必要です。
- SQL Serverは、SELECTで順序位置を指定しようとしていると判断するため、整数定数で並べ替えることはできません。
- 並べ替えることはできません。あらゆる種類の定数。
結論として、定数ではない式で並べ替える必要があります。もちろん、クエリされたテーブルの列リストで並べ替えることができます。しかし、私たちは、オプティマイザーが順序の関連性がないことを認識できる効率的なソリューションを見つけることを目指しています。
定数フォールディング
これまでの結論は、で定数を使用することはできないということです。インクルードROW_NUMBERのウィンドウ順序句ですが、次のクエリのように、定数に基づく式についてはどうでしょうか。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
ただし、この試みは定数と呼ばれるプロセスの犠牲になります折りたたみ。通常、クエリのパフォーマンスにプラスの影響を与えます。この手法の背後にある考え方は、クエリ処理の初期段階で、定数に基づく式を結果定数にフォールディングすることにより、クエリのパフォーマンスを向上させることです。定数畳み込みが可能な式の詳細については、こちらをご覧ください。式1+ 0は1に折りたたまれ、定数1を直接指定した場合とまったく同じエラーが発生します。
ウィンドウ関数、集計およびNEXTVALUE FOR関数は、ORDERBY句式として整数インデックスをサポートしていません。
次のように、2つの文字列リテラルを連結しようとすると、同様の状況に直面します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
リテラル「NoOrder」を直接指定した場合と同じエラーが発生します:
Windowed関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句の式として定数をサポートしていません。
Bizarro world –エラーを防ぐエラー
人生は驚きに満ちています…
定数畳み込みを妨げる1つのことは、式が通常エラーになる場合です。たとえば、式2147483646 + 1は、有効なINT型の値になるため、定数畳み込みにすることができます。その結果、次のクエリを実行しようとして失敗します:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
ウィンドウ関数、集計、および次の値FOR関数は、ORDERBY句の式として整数インデックスをサポートしていません。
ただし、このような試行ではINTオーバーフローエラーが発生するため、式2147483647 +1を定数畳み込むことはできません。注文への影響は非常に興味深いものです。次のクエリを試してください(これをクエリ2と呼びます):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
奇妙なことに、このクエリは正常に実行されます。何が起こるかというと、一方でSQL Serverは定数畳み込みを適用できないため、順序は単一の定数ではない式に基づいています。一方、オプティマイザは、順序付けの値がすべての行で同じであると判断するため、順序付け式を完全に無視します。これは、図3に示すように、このクエリの計画を調べるときに確認されます。
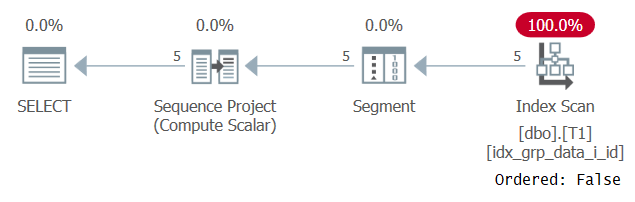 図3:クエリ2の計画
図3:クエリ2の計画
観察プランがOrdered:Falseプロパティを使用してカバーするインデックスをスキャンすること。これはまさに私たちのパフォーマンス目標でした。
同様の方法で、次のクエリは定数畳み込みの試行が成功するため、失敗します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句式として整数インデックスをサポートしていません。
次のクエリでは、定数畳み込みの試行が失敗したため、成功し、図3で前述したプランが生成されます。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
以下クエリには定数畳み込みの試行が成功する必要があり(VARCHARリテラル「1」は暗黙的にINT 1に変換され、次に1 + 1は2に折りたたまれます)、したがって失敗します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句式として整数インデックスをサポートしていません。
次のクエリには、定数畳み込みの試行に失敗したため(「A」をINTに変換できません)、成功し、図3で前述したプランが生成されます。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
正直なところ、この奇妙な手法は当初のパフォーマンス目標を達成していますが、安全だとは言えないため、信頼するのはあまり快適ではありません。
関数に基づく実行時定数
非決定論的な順序で行番号を計算するための優れたソリューションの検索を続けると、最後の風変わりなソリューションよりも安全と思われるいくつかの手法があります。関数に基づくランタイム定数の使用、定数に基づくサブクエリの使用、定数に基づいて変数を使用するエイリアス列。
T-SQLのバグ、落とし穴、ベストプラクティス(決定論)で説明しているように、T-SQLのほとんどの関数は、行ごとではなく、クエリ内の参照ごとに1回だけ評価されます。これは、GETDATEやRANDなどのほとんどの非決定論的関数にも当てはまります。このルールには、行ごとに1回評価される関数NEWIDやCRYPT_GEN_RANDOMなどの例外はほとんどありません。 GETDATE、@@ SPIDなどのほとんどの関数は、クエリの開始時に1回評価され、それらの値は実行時定数と見なされます。このような関数への参照は定数畳み込みになりません。これらの特性により、関数に基づく実行時定数がウィンドウ順序要素として適切に選択されます。実際、T-SQLはそれをサポートしているようです。同時に、オプティマイザーは、実際には順序の関連性がないことを認識し、不必要なパフォーマンスのペナルティを回避します。
GETDATE関数を使用した例を次に示します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
このクエリは、前に図3に示したものと同じプランを取得します。
@@ SPID関数を使用した別の例(現在のセッションIDを返す):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
関数PIはどうですか?次のクエリを試してください:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
これは次のエラーで失敗します:
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句の式として定数をサポートしていません。
GETDATEや@@ SPIDなどの関数は、プランの実行ごとに1回再評価されるため、取得できません。定数畳み込み。 PIは常に同じ定数を表すため、定数畳み込みが行われます。
前述のように、NEWIDやCRYPT_GEN_RANDOMなど、行ごとに1回評価される関数はほとんどありません。これにより、ランダムな順序と混同しないように、非決定的な順序が必要な場合は、ウィンドウの順序要素として不適切な選択になります。なぜ不必要なソートペナルティを支払うのですか?
NEWID関数を使用した例を次に示します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
このクエリの計画を図4に示し、SQLServerが明示的に追加したことを確認します関数の結果に基づいて並べ替えます。
 図4:クエリ3の計画
図4:クエリ3の計画
行番号を割り当てる場合ランダムな順序で、必ず、それがあなたが使いたいテクニックです。ソートコストが発生することに注意する必要があります。
サブクエリの使用
ウィンドウの順序式として定数に基づくサブクエリを使用することもできます(例:ORDER BY (SELECT “注文なし”))。また、このソリューションでは、SQL Serverのオプティマイザーは、順序の関連性がないことを認識しているため、不要な並べ替えを課したり、ストレージエンジンの選択を順序を保証する必要のあるものに制限したりしません。例として次のクエリを実行してみてください:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
図3で前述したのと同じプランが得られます。
大きなメリットの1つこのテクニックの特徴は、あなた自身の個人的なタッチを加えることができるということです。NULLが本当に好きかもしれません:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
特定の番号が本当に好きかもしれません:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
誰かにメッセージを送信したい場合があります:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
要点はわかります。
実行可能ですが、厄介です
うまくいくテクニックがいくつかありますが、少し厄介です。 1つは、定数に基づいて式の列エイリアスを定義し、その列エイリアスをウィンドウの順序付け要素として使用することです。これは、テーブル式を使用するか、CROSSAPPLY演算子とテーブル値コンストラクターを使用して行うことができます。後者の例を次に示します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
図3で前に示したのと同じ計画を取得します。
別のオプションは、変数を使用することです。ウィンドウ順序要素として:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
このクエリは、図3で前述したプランも取得します。
独自のUDFを使用するとどうなりますか?
定数を返す独自のUDFを使用することは、非決定的な順序が必要な場合のウィンドウ順序要素として適切であると思われるかもしれませんが、そうではありません。例として、次のUDF定義について考えてみます。
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
次のように、ウィンドウの順序付け句としてUDFを使用してみてください(これをクエリ4と呼びます)。
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
SQL Server 2019(または並列互換性レベル< 150)より前では、ユーザー定義関数は行ごとに評価されます。定数を返しても、インライン化されません。したがって、一方ではそのようなUDFをウィンドウ順序要素として使用できますが、他方ではこれによりソートペナルティが発生します。これは、図5に示すように、このクエリの計画を調べることで確認できます。
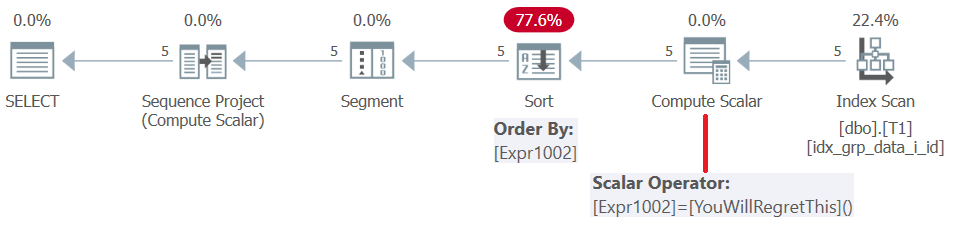 図5:クエリ4の計画
図5:クエリ4の計画
SQL Server 2019以降、互換性レベル> = 150で、このようなユーザー定義関数はインライン化されます。これはほとんどの場合素晴らしいことですが、この場合はエラーが発生します:
ウィンドウ関数、集計、およびNEXT VALUE FOR関数は、ORDERBY句式として定数をサポートしていません。
したがって、ウィンドウの順序付け要素としての定数は、使用しているSQL Serverのバージョンとデータベースの互換性レベルに応じて、並べ替えまたはエラーを強制します。要するに、これを行わないでください。
非決定的な順序で分割された行番号
非決定的な順序に基づく分割された行番号の一般的な使用例は、グループごとに任意の行を返すことです。定義上、このシナリオにはパーティショニング要素が存在することを考えると、このような場合の安全な手法は、ウィンドウのパーティショニング要素をウィンドウの順序付け要素としても使用することであると考えるでしょう。最初のステップとして、次のように行番号を計算します。
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
このクエリの計画を図6に示します。
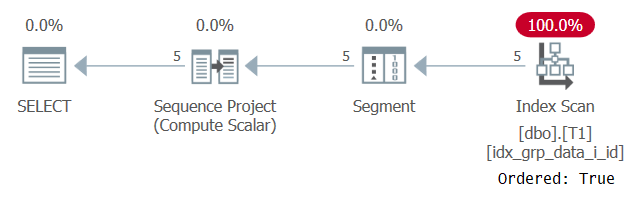 図6:クエリ5の計画
図6:クエリ5の計画
サポートインデックスがOrdered:Trueプロパティでスキャンされる理由は、SQLServerが各パーティションの行を次のように処理する必要があるためです。単一ユニット。これは、フィルタリング前のケースです。パーティションごとに1つの行のみをフィルタリングする場合、オプションとして順序ベースとハッシュベースの両方のアルゴリズムがあります。
2番目のステップは、行番号の計算を含むクエリをテーブル式に配置することです。外部クエリは、次のように、各パーティションの行番号1の行をフィルタリングします。
理論的にはこの手法は安全であると考えられますが、Paul whiteは、このメソッドを使用して属性を取得できることを示すバグを発見しましたパーティションごとに返される結果行の異なるソース行。関数に基づく実行時定数または定数に基づくサブクエリを順序付け要素として使用することは、このシナリオでも安全であると思われるため、代わりに次のようなソリューションを使用するようにしてください。
誰もいない私の許可なしにこの方法で合格する
非決定論的な順序に基づいて行番号を計算しようとすることは一般的なニーズです。 T-SQLが単にROW_NUMBER関数のウィンドウ順序句をオプションにしたとしたら良かったのですが、そうではありません。そうでない場合は、少なくとも順序付け要素として定数を使用できるようにしておけばよかったのですが、それもサポートされているオプションではありません。しかし、定数に基づくサブクエリまたは関数に基づくランタイム定数の形式でうまく質問すると、SQLServerはそれを許可します。 これらは私が最も快適な2つのオプションです。 うまくいくように見える風変わりな誤った表現にはあまり満足していないので、このオプションはお勧めできません。