ROW_NUMBER 창 함수에는 명백한 순위 요구 사항을 훨씬 뛰어 넘는 수많은 실용적인 응용 프로그램이 있습니다. 대부분의 경우 행 번호를 계산할 때 몇 가지 순서에 따라 계산해야하며 함수의 창 순서 절에 원하는 순서 지정을 제공해야합니다. 그러나 특별한 순서없이 행 번호를 계산해야하는 경우가 있습니다. 즉, 비 결정적 순서를 기반으로합니다. 이는 전체 쿼리 결과 또는 파티션 내에서 발생할 수 있습니다. 예를 들어 결과 행에 고유 한 값 할당, 데이터 중복 제거, 그룹당 행 반환 등이 있습니다.
비 결정적 순서를 기준으로 행 번호를 할당해야하는 것은 임의의 순서를 기준으로 할당해야하는 것과 다릅니다. 전자의 경우 할당 된 순서와 쿼리의 반복 실행이 동일한 행에 동일한 행 번호를 계속 할당하는지 여부는 신경 쓰지 않습니다. 후자의 경우 반복 실행으로 인해 어떤 행에 어떤 행 번호가 할당되는지 계속 변경 될 것으로 예상됩니다. 이 기사에서는 비 결정적 순서로 행 번호를 계산하는 다양한 기술을 살펴 봅니다. 희망은 신뢰할 수 있고 최적 인 기술을 찾는 것입니다.
상수 폴딩에 관한 팁, 런타임 상수 기술 및 항상 훌륭한 정보 소스가되어 준 Paul White에게 특별히 감사드립니다!
주문이 중요한 경우
행 번호 순서가 중요한 경우부터 시작하겠습니다.
예에서는 T1이라는 테이블을 사용하겠습니다. 다음 코드를 사용하여이 테이블을 만들고 샘플 데이터로 채 웁니다.
다음 쿼리를 고려합니다 (쿼리 1이라고 함).
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
여기서는 열 datacol로 정렬 된 열 grp로 식별되는 각 그룹 내에서 행 번호를 할당하려고합니다. 내 시스템에서이 쿼리를 실행했을 때 다음과 같은 결과가 나왔습니다.
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
여기서 행 번호는 부분적으로 결정적이고 부분적으로 비 결정적인 순서로 할당됩니다. 이것이 의미하는 바는 동일한 파티션 내에서 더 큰 datacol 값을 가진 행이 더 큰 행 번호 값을 갖게된다는 보장이 있다는 것입니다. 그러나 datacol은 grp 파티션 내에서 고유하지 않으므로 grp 및 datacol 값이 동일한 행간에 행 번호를 할당하는 순서는 결정적이지 않습니다. 이는 id 값이 2와 11 인 행의 경우입니다. 둘 다 grp 값 A와 datacol 값 50을 갖습니다. 시스템에서이 쿼리를 처음 실행했을 때 id 2 인 행은 행 번호 2를 얻었고 ID가 11 인 행에는 행 번호 3이 있습니다. SQL Server에서 실제로 이런 일이 발생할 가능성은 신경 쓰지 마십시오. 쿼리를 다시 실행하면 이론적으로 ID가 2 인 행에 행 번호 3이 할당되고 ID가 11 인 행에 행 번호 2가 할당 될 수 있습니다.
기반으로 행 번호를 할당해야하는 경우 완전히 결정적인 순서에 따라 기본 데이터가 변경되지 않는 한 쿼리 실행 전체에서 반복 가능한 결과를 보장하려면 창 분할 및 순서 지정 절의 요소 조합이 고유해야합니다. 이는 우리의 경우 열 ID를 창 순서 절에 타이 브레이커로 추가하여 달성 할 수 있습니다. OVER 절은 다음과 같습니다.
OVER (PARTITION BY grp ORDER BY datacol, id)
어쨌든 쿼리 1과 같이 의미있는 순서 지정 사양을 기반으로 행 번호를 계산할 때 SQL Server는 창 분할 및 순서 지정 요소의 조합에 따라 정렬 된 행. 이는 인덱스에서 사전 주문 된 데이터를 가져 오거나 데이터를 정렬하여 수행 할 수 있습니다. 현재 T1에는 쿼리 1의 ROW_NUMBER 계산을 지원하는 인덱스가 없으므로 SQL Server는 데이터 정렬을 선택해야합니다. 이는 그림 1의 쿼리 1 계획에서 확인할 수 있습니다.
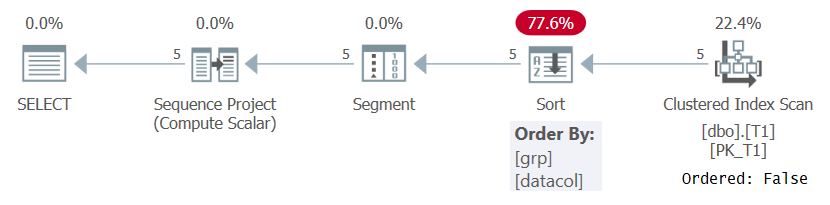 그림 1 : 지원 색인이없는 쿼리 1 계획
그림 1 : 지원 색인이없는 쿼리 1 계획
계획이 Ordered : False 속성을 사용하여 클러스터형 인덱스의 데이터를 검색합니다. 즉, 스캔에서 인덱스 키로 정렬 된 행을 반환 할 필요가 없습니다. 여기에서 클러스터형 인덱스가 사용되는 이유는 키 순서 때문이 아니라 쿼리를 다루기 때문입니다. 그런 다음 계획은 정렬을 적용하여 추가 비용, N Log N 스케일링 및 지연된 응답 시간을 초래합니다. Segment 연산자는 행이 파티션의 첫 번째 행인지 여부를 나타내는 플래그를 생성합니다. 마지막으로 시퀀스 프로젝트 연산자는 각 파티션에서 1로 시작하는 행 번호를 할당합니다.
정렬의 필요성을 피하려면 분할 및 정렬 요소를 기반으로하는 키 목록과 커버링 요소를 기반으로하는 포함 목록을 사용하여 커버링 인덱스를 준비 할 수 있습니다.저는이 인덱스를 POC 인덱스 (파티션, 순서 및 커버링)로 생각하고 싶습니다. 다음은 쿼리를 지원하는 POC의 정의입니다.
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
쿼리 1 다시 실행 :
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
이 실행 계획은 그림 2에 나와 있습니다.
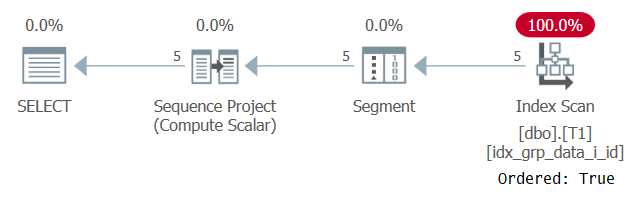 그림 2 : POC 색인이있는 쿼리 1 계획
그림 2 : POC 색인이있는 쿼리 1 계획
이번에는 계획이 Ordered : True 속성을 사용하여 POC 인덱스를 스캔하는지 확인합니다. 이는 스캔이 행이 인덱스 키 순서로 리턴됨을 보장 함을 의미합니다. 윈도우 함수가 필요로하는 것처럼 인덱스에서 데이터를 미리 정렬하기 때문에 명시 적으로 정렬 할 필요가 없습니다. 이 계획의 확장은 선형 적이며 응답 시간이 좋습니다.
순서가 중요하지 않은 경우
완전히 비 결정적인 행 번호를 할당해야 할 때 상황이 약간 까다로워집니다. 이런 경우에 당연히하고 싶은 것은 window order 절을 지정하지 않고 ROW_NUMBER 함수를 사용하는 것입니다. 먼저 SQL 표준이이를 허용하는지 확인합시다. 다음은 window에 대한 구문 규칙을 정의하는 표준의 관련 부분입니다. 함수 :
항목 6에 < ntile 함수 >, lead 또는 lag 함수 >, < 순위 함수 유형 > 또는 ROW_NUMBER, 항목 6a에 < ntile 함수 >, <가 표시됩니다. 리드 또는 지연 함수 >, RANK 또는 DENSE_RANK 창 순서 절은 b e 존재합니다. ROW_NUMBER에 창 순서 절이 필요한지 여부를 명시하는 명시적인 언어는 없지만 항목 6의 함수에 대한 언급과 6a의 생략은 해당 절이이 함수에 대해 선택 사항임을 의미 할 수 있습니다. RANK 및 DENSE_RANK와 같은 함수에 창 순서 절이 필요한 이유는 매우 분명합니다. 이러한 함수는 타이 처리에 특화되어 있고 타이는 주문 사양이있을 때만 존재하기 때문입니다. 그러나 ROW_NUMBER 함수가 선택적인 창 순서 절에서 어떤 이점을 얻을 수 있는지 확실히 알 수 있습니다.
그러므로 SQL Server에서 창 순서없이 행 번호를 계산해 보겠습니다.
p>
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
이 시도로 인해 다음 오류가 발생합니다.
The function “ROW_NUMBER” ORDER BY와 함께 OVER 절이 있어야합니다.
실제로 SQL Server의 ROW_NUMBER 함수 문서를 확인하면 다음 텍스트를 찾을 수 있습니다.
The ORDER BY 절은 지정된 파티션 내에서 행에 고유 한 ROW_NUMBER가 할당되는 순서를 결정합니다. 필수입니다.”
따라서 SQL Server의 ROW_NUMBER 함수에는 창 순서 절이 필수입니다. . 그건 그렇고, 오라클에서도 마찬가지입니다.
이유를 이해하고 있는지 잘 모르겠습니다. 이 요구 사항 뒤에 있습니다. 쿼리 1과 같이 부분적으로 비 결정적 순서를 기반으로 행 번호를 정의 할 수 있다는 점을 기억하십시오. 그렇다면 비결정론을 완전히 허용하지 않는 이유는 무엇입니까? 내가 생각하지 않는 이유가있을 것입니다. 그런 이유를 생각할 수 있다면 공유해주세요.
어쨌든 주문에 신경 쓰지 않는다면 창 주문 절은 필수이므로 어떤 것을 지정할 수 있습니다. 주문. 이 접근 방식의 문제점은 쿼리 된 테이블에서 일부 열을 기준으로 정렬하면 불필요한 성능 저하가 발생할 수 있다는 것입니다. 지원 색인이없는 경우 명시 적 정렬 비용을 지불해야합니다. 지원하는 인덱스가있는 경우 스토리지 엔진을 인덱스 순서 검색 전략 (인덱스 연결 목록에 따라)으로 제한합니다. 인덱스 순서 스캔과 할당 순서 스캔 (IAM 페이지 기반) 중에서 선택하는 데 순서가 중요하지 않을 때 일반적으로 사용하는 것처럼 더 많은 유연성을 허용하지 않습니다.
시도 할 가치가있는 한 가지 아이디어입니다. 창 순서 절에서 1과 같은 상수를 지정하는 것입니다. 지원되는 경우 옵티마이 저가 모든 행이 동일한 값을 가지고 있다는 것을 인식 할 수있을만큼 스마트하기를 바랍니다. 따라서 실제 순서 관련성이 없으므로 정렬 또는 인덱스 순서 스캔을 강제 할 필요가 없습니다. 이 접근 방식을 시도하는 쿼리는 다음과 같습니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
안타깝게도 SQL Server는이 솔루션을 지원하지 않습니다. 다음 오류가 생성됩니다.
창 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 식으로 정수 인덱스를 지원하지 않습니다.
분명히 SQL Server는 window order 절에서 정수 상수를 사용하는 경우 프레젠테이션 ORDER에서 정수를 지정할 때와 같이 SELECT 목록에있는 요소의 서수 위치를 나타낸다고 가정합니다. BY 절. 이 경우 시도해 볼 가치가있는 또 다른 옵션은 다음과 같이 정수가 아닌 상수를 지정하는 것입니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
이 솔루션도 지원되지 않음을 확인했습니다. SQL Server는 다음 오류를 생성합니다.
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 식으로 상수를 지원하지 않습니다.
분명히 창 순서 절은 어떤 종류의 상수도 지원하지 않습니다.
지금까지 SQL Server에서 ROW_NUMBER 함수의 창 순서 관련성에 대해 다음을 배웠습니다.
- ORDER BY가 필요합니다.
- SQL Server가 “SELECT에서 서수 위치를 지정하려고한다고 생각하므로 정수 상수로 정렬 할 수 없습니다.
- 순서 할 수 없음 모든 종류의 상수.
결론은 상수가 아닌 표현식으로 정렬해야한다는 것입니다. 분명히 쿼리 된 테이블에서 열 목록으로 정렬 할 수 있습니다. 그러나 우리는 최적화 프로그램이 순서 관련성이 없다는 것을 인식 할 수있는 효율적인 솔루션을 찾고 있습니다.
상수 폴딩
지금까지 결론은 상수를 사용할 수 없다는 것입니다. 그만큼 ROW_NUMBER의 창 순서 절이지만 다음 쿼리에서와 같이 상수를 기반으로하는 표현식은 어떻습니까?
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
그러나이 시도는 상수라고하는 프로세스의 희생양이됩니다. 일반적으로 쿼리 성능에 긍정적 인 영향을 미치는 접기입니다. 이 기술의 기본 개념은 쿼리 처리 초기 단계에서 상수를 기반으로하는 일부 식을 결과 상수로 접어 쿼리 성능을 향상시키는 것입니다. 여기에서 어떤 종류의 표현을 지속적으로 접을 수 있는지에 대한 자세한 내용을 확인할 수 있습니다. 식 1 + 0은 1로 접혀서 상수 1을 직접 지정할 때와 동일한 오류가 발생합니다.
Windowed functions, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 표현식으로 정수 인덱스를 지원하지 않습니다.
두 문자열 리터럴을 연결하려고 할 때 다음과 같은 유사한 상황이 발생합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
‘No Order’리터럴을 직접 지정할 때와 동일한 오류가 발생합니다.
Windowed 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 표현식으로 상수를 지원하지 않습니다.
Bizarro 세상 – 오류를 방지하는 오류
삶은 놀라움으로 가득 차 있습니다…
상수 접기를 방지하는 한 가지는 표현식이 일반적으로 오류를 발생시키는 경우입니다. 예를 들어 2147483646 + 1 표현식은 유효한 INT 유형 값을 생성하므로 상수로 접을 수 있습니다. 결과적으로 다음 쿼리 실행 시도가 실패합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 식으로 정수 인덱스를 지원하지 않습니다.
그러나 식 2147483647 + 1은 INT 오버플로 오류가 발생했기 때문에 상수로 접을 수 없습니다. 주문에 대한 의미는 매우 흥미 롭습니다. 다음 쿼리를 시도해보십시오 (이 쿼리를 쿼리 2라고 함).
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
이상하게도이 쿼리는 성공적으로 실행됩니다! 한편으로 SQL Server는 상수 접기를 적용하지 못하므로 순서가 단일 상수가 아닌 식을 기반으로합니다. 반면 옵티마이 저는 정렬 값이 모든 행에 대해 동일하다고 인식하므로 정렬 표현식을 모두 무시합니다. 이는 그림 3과 같이이 쿼리에 대한 계획을 검토 할 때 확인됩니다.
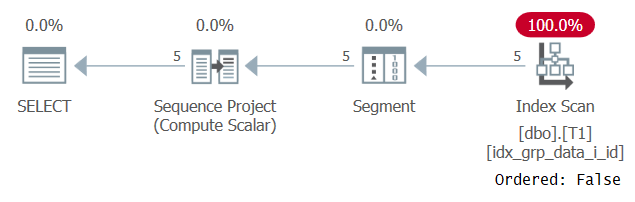 그림 3 : 쿼리 2에 대한 계획
그림 3 : 쿼리 2에 대한 계획
관찰 계획은 Ordered : False 속성으로 일부 커버링 인덱스를 스캔합니다. 이것이 바로 우리의 성능 목표였습니다.
비슷한 방식으로 다음 쿼리는 성공적인 연속 접기 시도를 포함하므로 실패합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 식으로 정수 인덱스를 지원하지 않습니다.
다음 쿼리는 실패한 상수 접기 시도를 포함하므로 성공하여 그림 3의 앞부분에 표시된 계획을 생성합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
다음 쿼리는 성공적인 상수 폴딩 시도를 포함합니다 (VARCHAR 리터럴 “1”은 암시 적으로 INT 1로 변환 된 다음 1 + 1이 2로 폴딩 됨). 따라서 실패합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 표현식으로 정수 인덱스를 지원하지 않습니다.
다음 쿼리는 상수 폴딩 시도가 실패하여 ( “A”를 INT로 변환 할 수 없음) 성공하여 그림 3의 앞부분에 표시된 계획이 생성됩니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
솔직히 말해서이 기괴한 기술이 우리의 원래 성능 목표를 달성 했음에도 불구하고 안전하다고 생각할 수는 없어서 그다지 의지 할 수 없습니다.
함수 기반 런타임 상수
비 결정적 순서로 행 번호를 계산하기위한 좋은 솔루션을 계속 검색하면 마지막 기발한 솔루션보다 안전 해 보이는 몇 가지 기술이 있습니다. 함수 기반 런타임 상수 사용, 상수 기반 하위 쿼리 사용, 상수를 기반으로하고 변수를 사용하는 별칭 열.
T-SQL 버그, 함정 및 모범 사례 (결정 성)에서 설명했듯이 T-SQL의 대부분의 함수는 행당 한 번이 아니라 쿼리의 참조 당 한 번만 평가됩니다. 이것은 GETDATE 및 RAND와 같은 대부분의 비 결정적 함수에서도 마찬가지입니다. 이 규칙에는 행당 한 번 평가되는 NEWID 및 CRYPT_GEN_RANDOM 함수와 같은 예외가 거의 없습니다. GETDATE, @@ SPID 및 기타 많은 함수와 같은 대부분의 함수는 쿼리 시작시 한 번 평가되며 해당 값은 런타임 상수로 간주됩니다. 이러한 함수에 대한 참조는 지속적으로 접히지 않습니다. 이러한 특성은 함수를 기반으로하는 런타임 상수를 창 순서 지정 요소로 좋은 선택으로 만들고 실제로 T-SQL이이를 지원하는 것으로 보입니다. 동시에 옵티마이 저는 실제로는 순서 관련성이 없다는 것을 인식하여 불필요한 성능 저하를 방지합니다.
다음은 GETDATE 함수를 사용한 예입니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
이 쿼리는 이전에 그림 3에 표시된 것과 동일한 계획을 가져옵니다.
다음은 @@ SPID 함수를 사용하는 또 다른 예입니다 (현재 세션 ID 반환).
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
함수 PI는 어떻습니까? 다음 쿼리를 시도하십시오.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
다음 오류와 함께 실패합니다.
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 식으로 상수를 지원하지 않습니다.
GETDATE 및 @@ SPID와 같은 함수는 계획이 실행될 때마다 한 번씩 재평가되므로 얻을 수 없습니다. 일정한 접힌. PI는 항상 동일한 상수를 나타내므로 상수가 접 힙니다.
앞서 언급했듯이 NEWID 및 CRYPT_GEN_RANDOM과 같이 행당 한 번 평가되는 함수는 거의 없습니다. 따라서 임의의 순서와 혼동하지 않도록 비 결정적 순서가 필요한 경우 창 순서 지정 요소로 잘못된 선택이됩니다. 불필요한 정렬 페널티를 지불하는 이유는 무엇입니까?
다음은 NEWID 함수를 사용한 예입니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
이 쿼리에 대한 계획은 그림 4에 나와 있으며 SQL Server가 명시 적으로 추가되었음을 확인합니다. 함수 결과를 기준으로 정렬합니다.
 그림 4 : 쿼리 3 계획
그림 4 : 쿼리 3 계획
행 번호를 할당하려는 경우 반드시 임의의 순서로 사용하고 싶은 기술입니다. 정렬 비용이 발생한다는 점만 인식하면됩니다.
하위 쿼리 사용
상수를 기반으로하는 하위 쿼리를 창 순서 표현식으로 사용할 수도 있습니다 (예 : ORDER BY ( “주문 없음”선택)). 또한이 솔루션을 통해 SQL Server의 옵티마이 저는 순서 관련성이 없음을 인식하므로 불필요한 정렬을 부과하거나 스토리지 엔진의 선택을 순서를 보장해야하는 항목으로 제한하지 않습니다. 다음 쿼리를 예로 실행 해보세요.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
앞의 그림 3에 표시된 것과 동일한 계획이 있습니다.
대단한 이점 중 하나 이 기술은 자신 만의 개성을 더할 수 있다는 것입니다.NULL을 정말 좋아할 수도 있습니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
정말 특정 숫자가 마음에들 수도 있습니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
누군가에게 메시지를 보내고 싶을 수도 있습니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
요점을 알 수 있습니다.
가능하지만 어색함
작동하는 몇 가지 기술이 있지만 약간 어색합니다. 하나는 상수를 기반으로 표현식에 대한 열 별칭을 정의한 다음 해당 열 별칭을 창 순서 요소로 사용하는 것입니다. 테이블 표현식을 사용하거나 CROSS APPLY 연산자와 테이블 값 생성자를 사용하여이 작업을 수행 할 수 있습니다. 후자의 예는 다음과 같습니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
그림 3에 표시된 것과 동일한 계획이 있습니다.
다른 옵션은 변수를 사용하는 것입니다. 창 순서 지정 요소 :
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
이 쿼리는 또한 그림 3의 앞부분에 표시된 계획을 가져옵니다.
내 자체 UDF를 사용하는 경우 ?
비 결정적 순서를 원할 때 상수를 반환하는 고유 한 UDF를 창 순서 지정 요소로 사용하는 것이 좋은 선택이라고 생각할 수 있지만 그렇지 않습니다. 다음 UDF 정의를 예로 고려하십시오.
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
다음과 같이 UDF를 창 순서 지정 절로 사용해보십시오 (이것을 Query 4라고합니다).
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
SQL Server 2019 (또는 병렬 호환성 수준 < 150) 이전에는 사용자 정의 함수가 행별로 평가됩니다. . 상수를 반환하더라도 인라인되지 않습니다. 따라서 한편으로는 이러한 UDF를 창 순서 지정 요소로 사용할 수 있지만 다른 한편으로는 정렬 패널티가 발생합니다. 이는 그림 5와 같이이 쿼리에 대한 계획을 검토하여 확인됩니다.
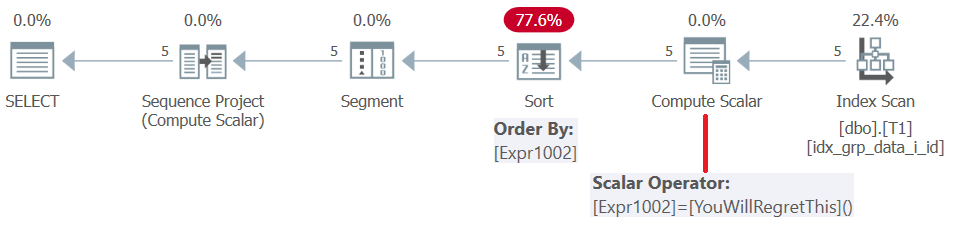 그림 5 : 쿼리 4에 대한 계획
그림 5 : 쿼리 4에 대한 계획
SQL Server 2019부터 호환성 수준 > = 150에서 이러한 사용자 정의 함수는 인라인됩니다. 이는 대부분 좋은 일이지만 우리의 경우에는 오류가 발생합니다.
윈도우 함수, 집계 및 NEXT VALUE FOR 함수는 ORDER BY 절 표현식으로 상수를 지원하지 않습니다.
따라서 UDF를 기반으로 창 순서 지정 요소 인 상수는 사용중인 SQL Server 버전과 데이터베이스 호환성 수준에 따라 정렬 또는 오류를 발생시킵니다. 간단히 말해이 작업을 수행하지 마십시오.
비 결정적 순서로 분할 된 행 번호
비 결정적 순서를 기반으로 분할 된 행 번호의 일반적인 사용 사례는 그룹당 모든 행을 반환하는 것입니다. 정의에 따라 분할 요소가이 시나리오에 존재한다는 점을 감안할 때, 이러한 경우에 안전한 기술은 창 분할 요소를 창 순서 요소로도 사용하는 것입니다. 첫 번째 단계로 다음과 같이 행 번호를 계산합니다.
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
이 쿼리의 계획은 그림 6에 나와 있습니다.
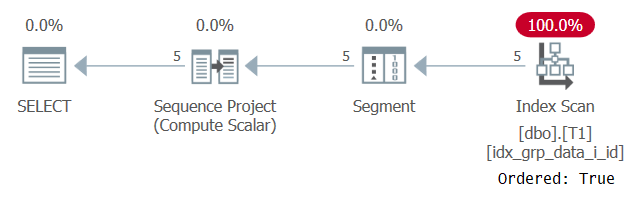 그림 6 : 쿼리 5 계획
그림 6 : 쿼리 5 계획
지원 인덱스가 Ordered : True 속성으로 스캔되는 이유는 SQL Server가 각 파티션의 행을 단일 단위. 필터링 전의 경우입니다. 파티션 당 하나의 행만 필터링하면 순서 기반 및 해시 기반 알고리즘이 모두 옵션으로 제공됩니다.
두 번째 단계는 행 번호 계산이 포함 된 쿼리를 테이블 표현식에 배치하는 것입니다. 외부 쿼리는 각 파티션에서 행 번호가 1 인 행을 다음과 같이 필터링합니다.
이론적으로이 기술은 안전해야하지만 Paul White는이 방법을 사용하여 속성을 가져올 수 있음을 보여주는 버그를 발견했습니다. 반환 된 결과 행의 파티션 당 다른 소스 행. 함수를 기반으로하는 런타임 상수 또는 상수를 기반으로하는 하위 쿼리를 순서 지정 요소로 사용하는 것이이 시나리오에서도 안전 해 보이므로 대신 다음과 같은 솔루션을 사용해야합니다.
아무도 내 허락없이이 방법을 통과 할 것입니다
비 결정적 순서를 기반으로 행 번호를 계산하는 것이 일반적인 요구 사항입니다. T-SQL이 단순히 ROW_NUMBER 함수에 대한 창 순서 절을 선택 사항으로 만들었 으면 좋았을 텐데 그렇지 않습니다. 그렇지 않다면 적어도 순서 요소로 상수를 사용할 수 있다면 좋았을 것입니다.하지만 지원되는 옵션도 아닙니다.그러나 상수를 기반으로하는 하위 쿼리 또는 함수를 기반으로하는 런타임 상수의 형태로 친절하게 요청하면 SQL Server에서이를 허용합니다. 이것이 제가 가장 편하게 생각하는 두 가지 옵션입니다. 작동하는 것 같은 기발한 잘못된 표현이 마음에 들지 않아서이 옵션을 추천 할 수 없습니다.