Det er ingen hemmelighet. Vi lever offisielt i big data-tiden. Nesten alle bedrifter – spesielt store bedrifter – samler inn, lagrer og analyserer data til fordel for vekst. I de fleste daglige forretningsdriftene er administrering av data en norm ved hjelp av verktøy som:
- Databaser
- Automatiseringssystemer
- CRM-plattformer
Hvis du har jobbet i et hvilket som helst selskap i noen tid, har du sannsynligvis møtt begrepet Data Normalization. En god praksis for håndtering og bruk av lagret informasjon, datanormalisering er en prosess som vil bidra til å forbedre suksessen i et helt selskap.
Her er alt du trenger å vite om datanormalisering sammen med noen tips om hvordan du kan forbedre dataene dine effektivt.
Hva er datanormalisering?
Datanormalisering regnes generelt som utviklingen av rene data. Dykking dypere er imidlertid betydningen eller målet med datanormalisering dobbelt:
- Datanormalisering er organisasjonen av data som skal virke like i alle poster og felt.
- Det øker samholdet av inngangstyper som fører til rensing, leadgenerering, segmentering og data av høyere kvalitet.
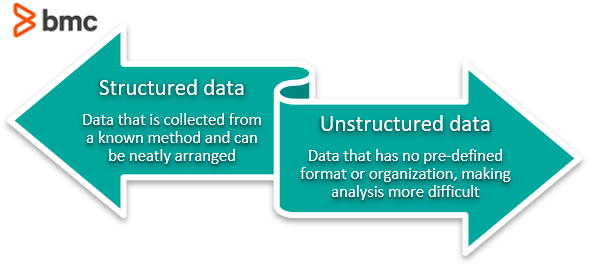
Enkelt sagt inkluderer denne prosessen eliminering av ustrukturerte data og redundans (duplikater) for å sikre logiske data Oppbevaring. Når datanormalisering er gjort riktig, vil du ende opp med standardisert informasjon. For eksempel gjelder denne prosessen hvordan URL-er, kontaktnavn, gateadresser, telefonnumre og til og med koder blir registrert. Disse standardiserte informasjonsfeltene kan deretter grupperes og leses raskt.
Hvem trenger datanormalisering?
Hver bedrift som ønsker å drive vellykket og vokse, må regelmessig utføre datanormalisering. Det er en av de viktigste tingene du kan gjøre for å bli kvitt feil som gjør løpende informasjonsanalyse komplisert og vanskelig. Slike feil sniker seg ofte når du endrer, legger til eller fjerner systeminformasjon. Når datainntastingsfeil fjernes, vil en organisasjon sitte igjen med et velfungerende system som er fullt av brukbare, fordelaktige data.
Med normalisering kan en organisasjon utnytte dataene så godt som å investere i datainnsamling på et større, mer effektivt nivå. Å se på data for å forbedre hvordan et selskap drives, blir en mindre utfordrende oppgave, spesielt når man kryssetter undersøkelser. For de som regelmessig konsoliderer og spørrer om data fra programvare-som-tjenesteapplikasjoner, så vel som for de som samler inn data fra en rekke kilder som sosiale medier, digitale nettsteder med mer, blir datanormalisering en uvurderlig prosess som sparer tid, plass og penger.
Slik fungerer datanormalisering
Nå er øyeblikket å merke seg at, avhengig av din spesifikke type data, vil normaliseringen din se annerledes ut.
På det mest grunnleggende er normalisering ganske enkelt å lage et standardformat for alle data i et selskap:
- Miss EMILY vil bli skrevet i fru Emily
- 8023097864 vil være skrevet 802-309-7864
- 24 canillas RD vil bli skrevet 24 Canillas Road
- GoogleBiz vil bli skrevet Google Biz, Inc.
- VP marketing vil bli skrevet Visepresident for markedsføring
Utover grunnleggende formatering, er eksperter enige om at det er fem generelle regler eller «normale former» for å utføre datanormalisering. Hver regel fokuserer på å sette e ntity typer i antall kategorier avhengig av kompleksitetsnivå. Anses å være retningslinjer for normalisering, er det tilfeller når variasjoner fra skjemaet må finne sted. Når det gjelder variasjoner, er det viktig å vurdere konsekvenser og uregelmessigheter.
Av hensyn til kompleksiteten, i denne artikkelen, blir de første og tre vanligste formene diskutert på toppnivå, og alle data er vurderes i tabellformat.
First Normal Form (1NF)
Den mest grunnleggende formen for datanormalisering er 1NFm, som sikrer at det ikke er noen gjentatte oppføringer i en gruppe. For å bli betraktet som 1NF, må hver oppføring bare ha en enkelt verdi for hver celle, og hver post må være unik.
For eksempel registrerer du navn, adresse, kjønn på en person og hvis de kjøpte cookies.
Second Normal Form (2NF)
Igjen arbeider vi for å sikre at gjentatte oppføringer ikke er, for å være i 2NF-regelen, må dataene først gjelde alle 1NF-kravene. Etter det må data bare ha en primærnøkkel. For å skille data for å bare ha en primærnøkkel, bør alle delmengder av data som kan plasseres i flere rader plasseres i separate tabeller. Deretter kan relasjoner opprettes gjennom nye utenlandske nøkkelmerker.
For eksempel registrerer du navnet, adressen, kjønnet til en person, hvis de kjøpte informasjonskapsler, samt informasjonskapsel typene. Cookietypene plasseres i en annen tabell med en tilsvarende utenlandsk nøkkel til hver persons navn.
Tredje normalform (3NF)
For at data skal være i denne regelen, må de først oppfylle alle 2NF-kravene. Etter det må data i en tabell bare være avhengig av primærnøkkelen. Hvis primærnøkkelen endres, må alle data som påvirkes settes i en ny tabell.
For eksempel registrerer du navnet på, adressen og kjønnet til en person, men går tilbake og endrer navnet av en person. Når du gjør dette, kan kjønnet også endre seg. For å unngå dette får kjønn i 3NF en fremmed nøkkel og en ny tabell for å lagre kjønn.
Når du begynner å forstå normaliseringsskjemaene bedre, vil reglene bli tydeligere mens du skiller dataene dine i tabeller og nivåer blir uanstrengt. Disse tabellene vil da gjøre det enkelt for alle i en organisasjon å samle informasjon og sikre at de samler inn riktige data som ikke dupliseres.
Fordelene med datanormalisering
Som nevnt ovenfor, er det mest viktig del av datanormalisering er bedre analyse som fører til vekst; Imidlertid er det noen flere utrolige fordeler med denne prosessen:
Mer plass
Med databaser fylt med informasjon, frigjør organisering og eliminering av duplikater mye nødvendig gigabyte og terabyteplass. Når et system er lastet med unødvendige ting, reduseres prosesseringsytelsen. Etter at du har rengjort digitalt minne, vil systemene dine kjøre raskere og lastes raskere, noe som betyr at dataanalyse gjøres med en mer effektiv hastighet.
Raskere svar på spørsmål
Snakker om raskere prosesser, etter at normalisering blir en enkel oppgave, kan du organisere dataene dine uten å måtte endre dem ytterligere. Dette hjelper forskjellige team i et selskap å spare verdifull tid i stedet for å prøve å oversette sprø data som ikke er lagret ordentlig.
Bedre segmentering
En av de beste måtene å utvide en bedrift på. er å sikre blysegmentering. Med datanormalisering kan grupper raskt deles inn i kategorier basert på titler, bransjer – du heter det. Å lage lister basert på hva som er verdifullt for en bestemt kundeemne, er en prosess som ikke lenger forårsaker hodepine.
Datanormalisering er ikke et alternativ
Da data blir mer verdifulle for alle typer måten det er organisert i masseegenskaper på, kan ikke overses.
Fra å sikre levering av e-post til forebygging av feiloppringinger og bedre analyse av grupper uten bekymring for duplikater, er det lett å se at når data normalisering utføres riktig, resulterer det i bedre generell forretningsfunksjon. Tenk deg hvis du legger igjen dataene dine i uorden og savner viktige vekstmuligheter på grunn av at et nettsted ikke lastes inn eller at notater ikke kommer til en VP. Ingenting av det høres ut som suksess eller vekst.
Å velge å normalisere data er noe av det viktigste du kan gjøre for organisasjonen din i dag.