Vinduet ROW_NUMBER har mange praktiske anvendelser, langt utover bare de åpenbare rangeringsbehovene. Når du beregner radnumre, må du beregne dem basert på en rekkefølge, og du oppgir ønsket bestillingsspesifikasjon i funksjonens vindusordningsparagraf. Imidlertid er det tilfeller der du trenger å beregne radnumre i ingen bestemt rekkefølge; med andre ord basert på ikke-bestemmende rekkefølge. Dette kan være på tvers av hele søkeresultatet, eller innenfor partisjoner. Eksempler inkluderer tildeling av unike verdier til resultatrader, deduplisering av data og retur av en rad per gruppe.
Merk at behovet for å tildele radnumre basert på ikke-bestemt rekkefølge er annerledes enn å måtte tilordne dem basert på tilfeldig rekkefølge. Med førstnevnte bryr du deg bare ikke i hvilken rekkefølge de er tildelt, og om gjentatte henrettelser av spørringen fortsetter å tilordne de samme radnumrene til de samme radene eller ikke. Med sistnevnte forventer du at gjentatte henrettelser fortsetter å endre hvilke rader som blir tildelt hvilke radnumre. Denne artikkelen utforsker forskjellige teknikker for beregning av radnumre i ikke-bestemt rekkefølge. Håpet er å finne en teknikk som er både pålitelig og optimal.
Spesiell takk til Paul White for tipset om konstant folding, for kjøretids konstant teknikk, og for alltid å være en god kilde til informasjon!
Når ordre betyr noe
Jeg begynner med tilfeller der rekkefølgen på radnummeret betyr noe.
Jeg bruker en tabell som heter T1 i eksemplene mine. Bruk følgende kode for å opprette denne tabellen og fylle den med eksempeldata:
Vurder følgende spørsmål (vi vil kalle det Spørring 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Her vil du at radnumre skal tildeles i hver gruppe identifisert av kolonne-grp, ordnet av kolonnens datakol. Da jeg kjørte dette spørsmålet på systemet mitt, fikk jeg følgende utdata:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Radnummer tildeles her i en delvis deterministisk og delvis ikke-deterministisk rekkefølge. Det jeg mener med dette er at du har en forsikring om at innenfor den samme partisjonen vil en rad med større datacol-verdi få en større radnummerverdi. Imidlertid, siden datacol ikke er unikt i grp-partisjonen, er rekkefølgen for tildeling av radnumre mellom rader med samme grp- og datacol-verdier ikke bestemt. Slik er tilfellet med radene med id-verdiene 2 og 11. Begge har grp-verdien A og datacol-verdien 50. Da jeg utførte dette spørsmålet på systemet mitt for første gang, fikk raden med id 2 rad nummer 2 og rad med id 11 fikk rad nummer 3. Husk sannsynligheten for at dette skjer i praksis i SQL Server; hvis jeg kjører spørringen igjen, teoretisk sett, kan raden med id 2 tildeles rad nummer 3 og raden med id 11 kan tildeles rad nummer 2.
Hvis du trenger å tildele radnumre basert i en helt deterministisk rekkefølge, som garanterer repeterbare resultater på tvers av kjøringer av spørringen så lenge de underliggende dataene ikke endres, trenger du kombinasjonen av elementer i vinduets partisjonering og bestillingsklausuler for å være unik. Dette kan oppnås i vårt tilfelle ved å legge til kolonne-ID-en i vindusordningsklausulen som en tiebreaker. OVER-klausulen ville da være:
OVER (PARTITION BY grp ORDER BY datacol, id)
I hvert fall når du beregner radnumre basert på noen meningsfylt bestillingsspesifikasjoner som i spørring 1, må SQL Server behandle rader ordnet etter kombinasjonen av vinduspartisjonering og bestillingselementer. Dette kan oppnås ved å enten trekke dataene som er forhåndsbestilt fra en indeks, eller ved å sortere dataene. For øyeblikket er det ingen indeks på T1 som støtter ROW_NUMBER-beregningen i spørring 1, så SQL Server må velge å sortere dataene. Dette kan sees i planen for spørring 1 vist i figur 1.
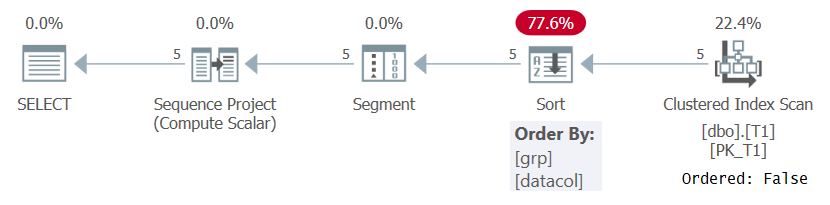 Figur 1: Plan for spørring 1 uten en støtteindeks
Figur 1: Plan for spørring 1 uten en støtteindeks
Legg merke til at planen skanner dataene fra den klyngede indeksen med en ordnet: falsk eiendom. Dette betyr at skanningen ikke trenger å returnere radene som er bestilt av indeksnøkkelen. Dette er tilfelle siden den klyngede indeksen brukes her bare fordi den tilfeldigvis dekker spørringen og ikke på grunn av nøkkelrekkefølgen. Planen bruker deretter en sortering, noe som resulterer i ekstra kostnad, N Log N-skalering og forsinket responstid. Segmentoperatøren produserer et flagg som indikerer om raden er den første i partisjonen eller ikke. Til slutt tilordner sekvensprosjektoperatøren radnumre som begynner med 1 i hver partisjon.
Hvis du vil unngå behovet for sortering, kan du utarbeide en dekningsindeks med en nøkkeliste som er basert på partisjonerings- og bestillingselementene, og en inkluderingsliste som er basert på dekkingselementene.Jeg liker å tenke på denne indeksen som en POC-indeks (for partisjonering, bestilling og tildekking). Her er definisjonen av POC som støtter forespørselen vår:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Kjør spørring 1 igjen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Planen for denne utførelsen er vist i figur 2.
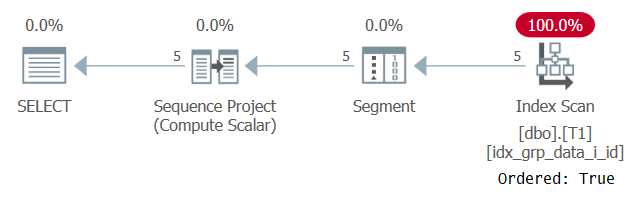 Figur 2: Plan for spørring 1 med en POC-indeks
Figur 2: Plan for spørring 1 med en POC-indeks
Vær oppmerksom på at denne gangen skanner planen POC-indeksen med en ordnet: sann eiendom. Dette betyr at skanningen garanterer at radene returneres i indeksnøkkelrekkefølge. Siden dataene blir hentet forhåndsbestilt fra indeksen slik vinduefunksjonen trenger, er det ikke behov for eksplisitt sortering. Skalering av denne planen er lineær og responstiden er god.
Når orden ikke betyr noe
Ting blir litt vanskelige når du trenger å tildele radnumre med en helt ikke-bestemmende rekkefølge. Den naturlige tingen å ønske å gjøre i et slikt tilfelle er å bruke ROW_NUMBER-funksjonen uten å spesifisere en vindusordningsklausul. La oss først sjekke om SQL-standarden tillater dette. Her er den relevante delen av standarden som definerer syntaksreglene for vindu funksjoner:
Legg merke til at element 6 viser funksjonene < ntile function >, < bly- eller forsinkelsesfunksjon >, < rangfunksjonstype > eller ROW_NUMBER, og deretter sier punkt 6a at for funksjonene < ntile function >, < bly- eller forsinkelsesfunksjon >, RANK eller DENSE_RANK skal vindusordningsklausulen b e present. Det er ikke noe eksplisitt språk som sier om ROW_NUMBER krever en vindusordneklausul eller ikke, men omtale av funksjonen i element 6 og utelatelse i 6a kan innebære at klausulen er valgfri for denne funksjonen. Det er ganske åpenbart hvorfor funksjoner som RANK og DENSE_RANK vil kreve en vindusordreklausul, siden disse funksjonene spesialiserer seg i håndtering av bånd, og bånd bare eksisterer når det er bestillingsspesifikasjon. Imidlertid kan du absolutt se hvordan ROW_NUMBER-funksjonen kan ha nytte av en valgfri vindusordneklausul.
Så la oss prøve, og prøve å beregne radnumre uten vindusbestilling i SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Dette forsøket resulterer i følgende feil:
Funksjonen «ROW_NUMBER» må ha en OVER-klausul med ORDER BY.
Hvis du sjekker SQL Servers dokumentasjon av ROW_NUMBER-funksjonen, finner du følgende tekst:
ORDER BY-ledd bestemmer sekvensen der radene tildeles sin unike ROW_NUMBER innenfor en spesifisert partisjon. Det er nødvendig. ”
Så tilsynelatende er vindusordningsparagrafen obligatorisk for ROW_NUMBER-funksjonen i SQL Server Dette er forresten også i Oracle.
Jeg må si at jeg ikke er sikker på at jeg forstår årsaken ng bak dette kravet. Husk at du tillater å definere radnumre basert på en delvis ikke-deterministisk rekkefølge, som i spørsmål 1. Så hvorfor ikke tillate ikke-bestemmelse hele veien? Kanskje det er en eller annen grunn som jeg ikke tenker på. Hvis du kan tenke deg en slik grunn, vennligst del.
I alle fall kan du argumentere for at hvis du ikke bryr deg om bestilling, gitt at vindusbestillingsparagrafen er obligatorisk, kan du angi hvilken som helst rekkefølge. Problemet med denne tilnærmingen er at hvis du bestiller etter en kolonne fra de forespurte tabellene, kan dette medføre unødvendig ytelsesstraff. Når det ikke er noen støtteindeks på plass, betaler du for eksplisitt sortering. Når det er en støtteindeks på plass, begrenser du lagringsmotoren til en skanestrategi for indeksordre (etter den indekselinkede listen). Du tillater det ikke mer fleksibilitet som det vanligvis har når ordren ikke betyr noe når du velger mellom en skanning av indeksordre og en skanning av tildelingsordre (basert på IAM-sider).
En idé det er verdt å prøve er å spesifisere en konstant, som 1, i vindusrekkefølgen. Hvis det støttes, håper du at optimalisereren er smart nok til å innse at alle radene har samme verdi, så det er ingen reell ordrerelevans og derfor ikke behov for å tvinge en sortering eller en indeksbestillingsskanning. Her er et spørsmål som prøver denne tilnærmingen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
SQL Server støtter dessverre ikke denne løsningen. Den genererer følgende feil:
Funksjoner med vindu, aggregater og NESTE VERDI FOR funksjoner støtter ikke heltallindekser som ORDER BY-ledduttrykk.
Tilsynelatende antar SQL Server at hvis du bruker en heltallskonstant i vindusrekkefølgen, representerer den en ordinær posisjon av et element i SELECT-listen, som når du spesifiserer et heltall i presentasjonen BESTILL BY-klausul. Hvis det er tilfelle, er et annet alternativ det er verdt å prøve å spesifisere en ikke-tallkonstant, slik:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Viser seg at denne løsningen ikke støttes også. SQL Server genererer følgende feil:
Vinduefunksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke konstanter som ORDER BY-ledduttrykk.
Tilsynelatende støtter ikke vindusbestillingsparagrafen noen form for konstant.
Så langt har vi lært følgende om ROW_NUMBER-funksjonens vindusbestillingsrelevans i SQL Server:
- ORDER BY kreves.
- Kan ikke bestille etter et heltallskonstant siden SQL Server mener du prøver å spesifisere en ordinær posisjon i SELECT.
- Kan ikke bestille etter noen form for konstant.
Konklusjonen er at du skal bestille etter uttrykk som ikke er konstanter. Åpenbart kan du bestille etter en kolonneliste fra de forespurte tabellene. Men vi er på jakt etter å finne en effektiv løsning der optimalisereren kan innse at det ikke er noen bestillingsrelevans.
Konstant folding
Konklusjonen så langt er at du ikke kan bruke konstanter i de ROW_NUMBERs vindusordningsklausul, men hva med uttrykk basert på konstanter, for eksempel i følgende spørsmål:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Imidlertid blir dette forsøket offer for en prosess kjent som konstant folding, som normalt har en positiv ytelsespåvirkning på spørsmål. Ideen bak denne teknikken er å forbedre søkeytelsen ved å brette noe uttrykk basert på konstanter til deres resultatkonstanter på et tidlig stadium av spørringsbehandlingen. Du kan finne detaljer om hva slags uttrykk som kan foldes konstant her. Uttrykket 1 + 0 er brettet til 1, noe som resulterer i den samme feilen som du fikk da du spesifiserte konstanten 1 direkte:
Windowed-funksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke heltallindekser som ORDER BY-setningsuttrykk.
Du vil møte en lignende situasjon når du prøver å sammenkoble to tegnstrengliteraler, slik:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Du får den samme feilen som du fikk da du spesifiserte bokstavelig «Ingen ordre» direkte:
Windowed funksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke konstanter som ORDER BY-ledduttrykk.
Bizarro world – feil som forhindrer feil
Livet er fullt av overraskelser …
En ting som forhindrer konstant folding er når uttrykket normalt vil føre til en feil. Eksempelvis kan uttrykket 2147483646 + 1 brettes konstant siden det resulterer i en gyldig INT-skrevet verdi. Følgelig mislykkes et forsøk på å kjøre følgende søk:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Vinduefunksjoner, aggregater og NESTE VERDI FOR-funksjoner støtter ikke heltallindekser som ORDER BY-ledduttrykk.
Imidlertid kan ikke uttrykket 2147483647 + 1 foldes konstant fordi et slikt forsøk ville ha resultert i en INT-overflow-feil. Implikasjonen ved bestilling er ganske interessant. Prøv følgende spørsmål (vi vil kalle denne spørringen 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Merkelig nok, denne spørringen kjører vellykket! Det som skjer er at på den ene siden klarer ikke SQL Server å bruke konstant folding, og derfor er bestillingen basert på et uttrykk som ikke er en eneste konstant. På den annen side beregner optimalisereren at bestillingsverdien er den samme for alle rader, så den ignorerer bestillingsuttrykket helt. Dette bekreftes når planen for dette spørsmålet undersøkes som vist i figur 3.
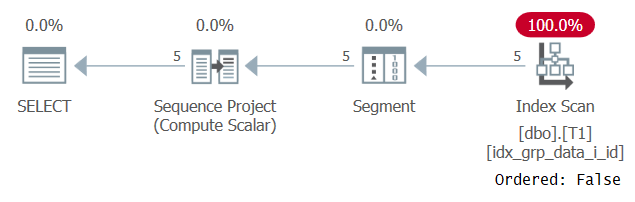 Figur 3: Plan for spørring 2
Figur 3: Plan for spørring 2
Observer at planen skanner noen dekkende indekser med en ordnet: falsk eiendom. Dette var nøyaktig vårt ytelsesmål.
På samme måte innebærer følgende spørsmål et vellykket konstant foldingsforsøk, og mislykkes derfor:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Vinduefunksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke heltallindekser som ORDER BY-ledduttrykk.
Følgende spørsmål innebærer et mislykket konstant foldingsforsøk, og lykkes derfor med å generere planen vist tidligere i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Følgende spørring innebærer et vellykket konstant foldingsforsøk (VARCHAR bokstavelig «1» blir implisitt konvertert til INT 1, og deretter blir 1 + 1 brettet til 2), og mislykkes derfor:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Vinduefunksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke heltallindekser som ORDER BY-setningsuttrykk.
Følgende spørsmål innebærer en mislyktes konstant foldeforsøk (kan ikke konvertere «A» til INT), og lykkes derfor med å generere planen vist tidligere i figur 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
For å være ærlig, selv om denne bizarro-teknikken oppnår vårt opprinnelige ytelsesmål, kan jeg ikke si at jeg anser det som trygt, og derfor er jeg ikke så komfortabel å stole på det.
Runtime konstanter basert på funksjoner
Fortsatt søket etter en god løsning for beregning av radnumre med ikke-bestemt rekkefølge, er det noen få teknikker som virker tryggere enn den siste quirky løsningen: bruk av kjøretidskonstanter basert på funksjoner, bruk av et underspørsmål basert på en konstant, ved hjelp av en alias kolonne basert på en konstant og bruker en variabel.
Som jeg forklarer i T-SQL-feil, fallgruver og best practices – determinisme, blir de fleste funksjonene i T-SQL bare evaluert en gang per referanse i spørringen – ikke en gang per rad. Dette er tilfelle selv med de fleste ikke-bestemte funksjoner som GETDATE og RAND. Det er svært få unntak fra denne regelen, som funksjonene NEWID og CRYPT_GEN_RANDOM, som blir evaluert en gang per rad. De fleste funksjoner, som GETDATE, @@ SPID og mange andre, blir evaluert en gang i begynnelsen av spørringen, og deres verdier blir da betraktet som kjøretidskonstanter. En referanse til slike funksjoner blir ikke konstant brettet. Disse egenskapene gjør en kjøretidskonstant som er basert på en funksjon til et godt valg som vindusbestillingselement, og det ser faktisk ut til at T-SQL støtter det. Samtidig innser optimalisereren at det i praksis ikke er noen bestillingsrelevans, og unngår unødvendige ytelsesstraffer.
Her er et eksempel på GETDATE-funksjonen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Dette spørsmålet får samme plan som vist tidligere i figur 3.
Her er et annet eksempel med @@ SPID-funksjonen (returnerer gjeldende økt-ID):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Hva med funksjonen PI? Prøv følgende spørsmål:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Denne mislykkes med følgende feil:
Windowed-funksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke konstanter som ORDER BY-setningsuttrykk.
Funksjoner som GETDATE og @@ SPID blir evaluert en gang per utførelse av planen, slik at de ikke kan få konstant brettet. PI representerer alltid samme konstant, og blir derfor konstant brettet.
Som nevnt tidligere, er det svært få funksjoner som blir evaluert en gang per rad, for eksempel NEWID og CRYPT_GEN_RANDOM. Dette gjør dem til et dårlig valg som vindusbestillingselement hvis du trenger ikke-bestemt rekkefølge – ikke å forveksle med tilfeldig rekkefølge. Hvorfor betale en unødvendig sorteringsstraff?
Her er et eksempel på NEWID-funksjonen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Planen for dette spørringen er vist i figur 4, som bekrefter at SQL Server la til eksplisitt sortering basert på funksjonens resultat.
 Figur 4: Plan for spørring 3
Figur 4: Plan for spørring 3
Hvis du vil at radnumrene skal tildeles i tilfeldig rekkefølge, for all del, det er teknikken du vil bruke. Du trenger bare å være oppmerksom på at det medfører sorteringskostnaden.
Bruke en underspørring
Du kan også bruke en undersøk basert på en konstant som vinduets bestillingsuttrykk (f.eks. BESTILL AV (VELG «Ingen ordre»)). Også med denne løsningen anerkjenner SQL Servers optimalisereren at det ikke er noen bestillingsrelevans, og pålegger derfor ikke unødvendig sortering eller begrenser lagringsmotorens valg til de som må garantere orden. Prøv å kjøre følgende spørsmål som et eksempel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Du får den samme planen vist tidligere i figur 3.
En av de store fordelene av denne teknikken er at du kan legge til ditt eget personlige preg.Kanskje du virkelig liker NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Kanskje du virkelig liker et bestemt tall:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Kanskje du vil sende noen en melding:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Du forstår poenget.
Gjørbar, men vanskelig
Det er et par teknikker som fungerer, men er litt vanskelig. Det ene er å definere et kolonnealias for et uttrykk basert på en konstant, og deretter bruke det kolonnealiaset som vindusbestillingselement. Du kan gjøre dette enten ved å bruke et tabelluttrykk eller med CROSS APPLY-operatoren og en tabellverdikonstruktør. Her er et eksempel for sistnevnte:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Du får den samme planen som er vist tidligere i figur 3.
Et annet alternativ er å bruke en variabel som vindusbestillingselement:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Dette spørsmålet får også planen vist tidligere i figur 3.
Hva om jeg bruker min egen UDF ?
Du tror kanskje at bruk av din egen UDF som returnerer en konstant, kan være et godt valg som vindusbestillingselement når du ønsker ikke-bestemt rekkefølge, men det er det ikke. Tenk på følgende UDF-definisjon som et eksempel:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Prøv å bruke UDF som vindusbestillingsklausul, slik (vi vil kalle dette Spørsmål 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Før SQL Server 2019 (eller parallelt kompatibilitetsnivå < 150) blir brukerdefinerte funksjoner evaluert per rad . Selv om de returnerer konstant, blir de ikke innrammet. Derfor kan du på den ene siden bruke en slik UDF som vindusbestillingselementet, men på den annen side resulterer dette i en slags straff. Dette bekreftes ved å undersøke planen for dette spørsmålet, som vist i figur 5.
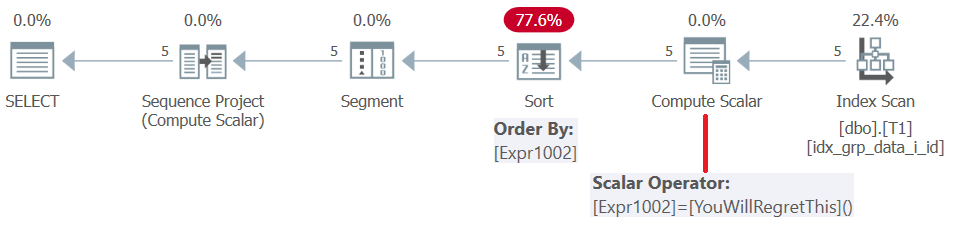 Figur 5: Plan for spørring 4
Figur 5: Plan for spørring 4
Fra og med SQL Server 2019, under kompatibilitetsnivå > = 150, blir slike brukerdefinerte funksjoner inline, noe som stort sett er en flott ting, men i vårt tilfelle resulterer i en feil:
Vinduefunksjoner, aggregater og NESTE VERDI FOR funksjoner støtter ikke konstanter som ORDER BY-setningsuttrykk.
Så bruker en UDF basert på en konstant som vindusbestillingselementet enten tvinger en sortering eller en feil, avhengig av versjonen av SQL Server du bruker og databasekompatibilitetsnivået. Kort sagt, ikke gjør dette.
Partisjonerte radnumre med ikke-bestemmende rekkefølge
En vanlig brukssak for partisjonerte radnumre basert på ikke-bestemmende rekkefølge returnerer en rad per gruppe. Gitt at det per definisjon eksisterer et partisjoneringselement i dette scenariet, vil du tro at en trygg teknikk i et slikt tilfelle vil være å bruke vinduspartisjoneringselementet også som vindusbestillingselement. Som et første trinn beregner du radnumre slik:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Planen for dette spørsmålet er vist i figur 6.
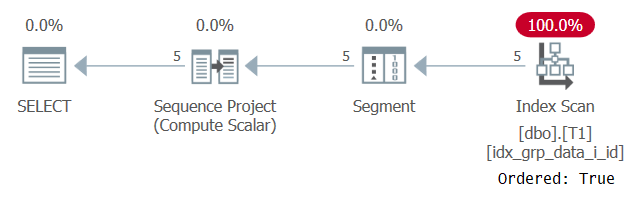 Figur 6: Plan for spørsmål 5
Figur 6: Plan for spørsmål 5
Årsaken til at vår støtteindeks blir skannet med en Ordered: True-egenskap er fordi SQL Server trenger å behandle hver partisjonens rader som en enkelt enhet. Det er tilfelle før filtrering. Hvis du bare filtrerer en rad per partisjon, har du både ordrebaserte og hashbaserte algoritmer som alternativer.
Det andre trinnet er å plassere spørringen med radnummerberegningen i et tabelluttrykk, og i det ytre spørsmålet filtrerer raden med rad nummer 1 i hver partisjon, slik:
Teoretisk sett skal denne teknikken være trygg, men Paul white fant en feil som viser at du ved hjelp av denne metoden kan få attributter fra forskjellige kilderader i den returnerte resultatraden per partisjon. Ved å bruke en kjøretidskonstant basert på en funksjon eller en underspørsel basert på en konstant, ettersom bestillingselementet ser ut til å være trygt selv med dette scenariet, så sørg for at du bruker en løsning som følgende i stedet:
Ingen skal passere denne veien uten min tillatelse
Å prøve å beregne radnumre basert på ikke-bestemmende rekkefølge er et vanlig behov. Det hadde vært fint om T-SQL rett og slett gjorde vindusordningsklausulen valgfri for ROW_NUMBER-funksjonen, men det gjør det ikke. Hvis ikke, ville det vært fint om det i det minste tillot å bruke en konstant som bestillingselement, men det er heller ikke et alternativ som støttes.Men hvis du spør pent, i form av en underspørsel basert på en konstant eller en kjøretidskonstant basert på en funksjon, vil SQL Server tillate det. Dette er de to alternativene jeg er mest komfortabel med. Jeg føler meg ikke veldig komfortabel med de sære feilaktige uttrykkene som ser ut til å fungere, så jeg kan ikke anbefale dette alternativet.