A-roboter .txt-filen inneholder direktiver for søkemotorer. Du kan bruke den til å forhindre søkemotorer i å gjennomsøke bestemte deler av nettstedet ditt og å gi søkemotorer nyttige tips om hvordan de best kan gjennomsøke nettstedet ditt. Robots.txt-filen spiller en stor rolle i SEO.
Når du implementerer robots.txt, må du huske på følgende fremgangsmåter:
- Vær forsiktig når du gjør endringer i robots.txt: denne filen har potensial til å gjøre store deler av nettstedet ditt utilgjengelig for søkemotorer.
- Robots.txt-filen skal ligge i roten til nettstedet ditt (f.eks.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpellerhttps). - Ulike søkemotorer tolker direktiver forskjellig. Som standard vinner alltid det første matchende direktivet. Men med Google og Bing vinner spesifisiteten.
- Unngå å bruke gjennomsøkingsforsinkelsesdirektivet så mye som mulig.
Hva er en robots.txt-fil?
En robots.txt-fil forteller søkemotorer hva nettstedets regler for engasjement er. En stor del av å gjøre SEO handler om å sende riktige signaler til søkemotorer, og robots.txt er en av måtene å kommunisere dine gjennomsøkingsinnstillinger til søkemotorer.
I 2019 har vi sett ganske noen utviklinger rundt robots.txt-standarden: Google foreslo en utvidelse av Robots Exclusion Protocol og åpen sourcing av robots.txt-parseren.
TL; DR
- Googles roboter .txt-tolk er ganske fleksibel og overraskende tilgivende.
- I tilfelle forvirringsdirektiver tar Google feil på de sikre sidene og antar at seksjoner bør være begrenset snarere enn ubegrenset.
Søkemotorer sjekker regelmessig robots.txt-filen på et nettsted for å se om det er noen instruksjoner for gjennomgang av nettstedet. Vi kaller disse instruksjonsdirektivene.
Hvis det ikke finnes noen robots.txt-fil, eller hvis det ikke er noen gjeldende direktiver, vil søkemotorer gjennomsøke hele nettstedet.
Selv om alle store søkemotorer respekterer robots.txt-filen, kan søkemotorer velge å ignorere (deler av) robots.txt-filen din. Selv om direktiver i robots.txt-filen er et sterkt signal til søkemotorer, er det viktig å huske at robots.txt-filen er et sett med valgfrie direktiver til søkemotorer i stedet for et mandat.

Robotene.txt er den mest sensitive filen i SEO-universet. Et enkelt tegn kan bryte et helt nettsted.
Terminologi rundt robots.txt-fil
Robots.txt-filen er implementeringen av robotenes ekskluderingsstandard, eller også kalt protokollen for ekskludering av roboter.
Hvorfor bør du bry deg om robots.txt?
Robotene.txt spiller en viktig rolle fra et SEO-synspunkt. Den forteller søkemotorer hvordan de best kan gjennomsøke nettstedet ditt.
Ved å bruke robots.txt-filen kan du forhindre søkemotorer i å få tilgang til bestemte deler av nettstedet ditt, forhindre duplisert innhold og gi søkemotorer nyttige tips om hvordan de kan gjennomsøke nettstedet mer effektivt.
Vær forsiktig når du gjør endringer i robots.txt: denne filen har potensial til å gjøre store deler av nettstedet ditt utilgjengelig for søkemotorer.

Robots.txt brukes ofte for å redusere duplikatinnhold, og dermed drepe intern lenking så vær veldig forsiktig med det. Mitt råd er å bare bruke det til filer eller sider som søkemotorer aldri skal se, eller som kan ha betydelig innvirkning på gjennomsøking ved å bli sluppet inn. Vanlige eksempler: påloggingsområder som genererer mange forskjellige nettadresser, testområder eller hvor det kan eksistere flere fasetterte navigasjoner. Og sørg for å overvåke robots.txt-filen for eventuelle problemer eller endringer.

De fleste problemer jeg ser med robots.txt-filer, faller i tre bøtter:
- Feil håndtering av jokertegn. Det er ganske vanlig å se deler av nettstedet som er ment å bli sperret av. Noen ganger, hvis du ikke er forsiktig, kan direktiver også komme i konflikt med hverandre.
- Noen, for eksempel en utvikler, har gjort en endring utenom det blå (ofte når du trykker på ny kode) og har utilsiktet endret seg. robots.txt uten din viten.
- Inkludering av direktiver som ikke hører hjemme i en robots.txt-fil. Robots.txt er nettstandard, og er noe begrenset. Jeg ser ofte utviklere lage direktiver som rett og slett ikke vil fungere (i det minste for det store flertallet av crawlere). Noen ganger er det ufarlig, noen ganger ikke så mye.
Eksempel
La oss se på et eksempel for å illustrere dette:
Du driver et e-handelsnettsted, og besøkende kan bruke et filter for raskt å søke gjennom produktene dine. Dette filteret genererer sider som i utgangspunktet viser det samme innholdet som andre sider gjør. Dette fungerer bra for brukere, men forvirrer søkemotorer fordi det skaper duplikatinnhold.
Du vil ikke at søkemotorer skal indeksere disse filtrerte sidene og kaste bort verdifull tid på disse nettadressene med filtrert innhold. Derfor bør du sette opp Disallow regler slik at søkemotorer ikke får tilgang til disse filtrerte produktsidene.
Å forhindre duplisert innhold kan også gjøres ved hjelp av den kanoniske URL-en eller meta-roboten-taggen, men disse adresserer ikke at søkemotorer bare kan gjennomsøke sider som betyr noe.
Ved å bruke en kanonisk URL eller meta-robot-tag vil det ikke hindre søkemotorer i å gjennomgå disse sidene. Det vil bare forhindre at søkemotorer viser disse sidene i søkeresultatene. Siden søkemotorer har begrenset tid til å gjennomsøke et nettsted, bør denne tiden brukes på sider du vil skal vises i søkemotorer.
En feil konfigurert robots.txt-fil kan hindre SEO-ytelsen din. Sjekk om dette er tilfelle for nettstedet ditt med en gang!

Det er et veldig enkelt verktøy, men en robots.txt-fil kan forårsake mange problemer hvis den ikke er konfigurert riktig, spesielt for større nettsteder. Det er veldig enkelt å gjøre feil som å blokkere et helt nettsted etter at et nytt design eller CMS er rullet ut, eller ikke blokkere deler av et nettsted som skal være private. For større nettsteder er det veldig viktig å sikre at Google gjennomsøker effektivt, og at en godt strukturert robots.txt-fil er et viktig verktøy i den prosessen.
Du må ta deg tid til å forstå hvilke deler av nettstedet som best holdes borte. fra Google slik at de bruker mest mulig av ressursen sin på å gjennomsøke sidene du virkelig bryr deg om.
Hvordan ser en robots.txt-fil ut?
Et eksempel på hvordan en enkel robots.txt-fil for et WordPress-nettsted kan være se ut som:
La oss forklare anatomien til en robots.txt-fil basert på eksemplet ovenfor:
- Brukeragent:
user-agentangir for hvilket søk motorene direktivene som følger er ment. -
*: dette indikerer at direktivene er ment for alle søkemotorer. -
Disallow: dette er et direktiv som indikerer hvilket innhold som ikke er tilgjengelig foruser-agent. -
/wp-admin/: dette erpathsom er utilgjengelig foruser-agent.
Oppsummert: Denne robots.txt-filen ber alle søkemotorer om å holde seg utenfor /wp-admin/ -katalogen.
La oss analysere de forskjellige komponenter i robots.txt-filer mer detaljert:
- User-agent
- Disallow
- Tillat
- Sitemap
- Gjennomsøkingsforsinkelse
Brukeragent i robots.txt
Hver søkemotor skal identifisere seg med en user-agent. Googles roboter identifiserer for eksempel som Googlebot, Yahoos roboter som Slurp og Bings robot som BingBot og så videre.
user-agent -posten definerer starten på en gruppe direktiver. Alle direktiver mellom den første user-agent og den neste user-agent posten blir behandlet som direktiver for den første user-agent.
Direktiver kan gjelde for spesifikke brukeragenter, men de kan også gjelde for alle brukeragenter. I så fall brukes et jokertegn: User-agent: *.
Ikke tillat direktiv i robots.txt
Du kan fortelle søkemotorer om ikke å få tilgang til bestemte filer, sider eller deler av nettstedet ditt. Dette gjøres ved hjelp av Disallow -direktivet. Disallow -direktivet følges av path som ikke skal nås. Hvis ingen path er definert, ignoreres direktivet.
Eksempel
I dette eksemplet får alle søkemotorer beskjed om ikke å få tilgang til /wp-admin/ -katalogen.
Tillat direktiv i robots.txt
Allow -direktivet brukes til å motvirke et Disallow -direktiv. Allow -direktivet støttes av Google og Bing. Ved å bruke direktene Allow og Disallow kan du fortelle søkemotorer at de kan få tilgang til en bestemt fil eller side i en katalog som ellers ikke er tillatt. Allow -direktivet følges av path som er tilgjengelig. Hvis ingen path er definert, ignoreres direktivet.
Eksempel
I eksemplet ovenfor har ikke alle søkemotorer tilgang til /media/ katalog, bortsett fra filen /media/terms-and-conditions.pdf.
Viktig: når du bruker Allow og Disallow direktiver sammen, pass på å ikke bruke jokertegn siden dette kan føre til motstridende direktiver.
Eksempel på motstridende direktiver
Søkemotorer vet ikke hva de skal gjøre med nettadressen . Det er uklart for dem om de har tilgang. Når direktiver ikke er klare for Google, vil de følge det minst restriktive direktivet, noe som i dette tilfellet betyr at de faktisk ville få tilgang til
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt er en av funksjonene jeg ofte ser implementert feil, så den blokkerer ikke det de ønsket å blokkere, eller den blokkerer mer enn de forventet, og har en negativ innvirkning på nettstedet deres. Robots.txt er et veldig kraftig verktøy, men for ofte er det feil oppsett.
Bruk av jokertegn *
Jokertegnet kan ikke bare brukes til å definere user-agent, det kan også brukes til å samsvarer med nettadresser. Jokertegnet støttes av Google, Bing, Yahoo og Ask.
Eksempel
I eksemplet ovenfor har ikke alle søkemotorer tilgang til nettadresser som inkluderer et spørsmålstegn (?).

Utviklere eller nettstedeiere synes ofte å tro at de kan bruke all slags vanlig uttrykk i en robots.txt-fil, mens bare en veldig begrenset mengde mønstermatching faktisk er gyldig – for eksempel jokertegn (
*). Det ser ut til å være en forvirring mellom .htaccess-filer og robots.txt-filer fra tid til annen.
Bruke slutten av URL $
For å indikere slutten på en URL kan du bruke dollartegnet ($) på slutten av path.
Eksempel
I eksemplet ovenfor har ikke søkemotorer tilgang til alle nettadresser som ender med .php . URL-er med parametere, f.eks. vil ikke bli tillatt, siden nettadressen ikke slutter etter .php.
Legg til sitemap i roboter. txt
Selv om robots.txt-filen ble oppfunnet for å fortelle søkemotorer hvilke sider som ikke skal gjennomsøkes, kan robots.txt-filen også brukes til å peke søkemotorer til XML-sitemap. Dette støttes av Google, Bing, Yahoo og Ask.
XML-sitemap bør refereres til som en absolutt URL. URL-en trenger ikke å være på samme vert som robots.txt-filen.
Henvisning til XML-sitemap i robots.txt-filen er en av de beste fremgangsmåtene vi anbefaler deg å alltid gjøre, selv om du har kanskje allerede sendt inn XML-sitemap i Google Search Console eller Bing Webmaster Tools. Husk at det er flere søkemotorer der ute.
Vær oppmerksom på at det er mulig å referere til flere XML-sitemaps i en robots.txt-fil.
Eksempler
Flere XML-sitemaps definert i en robots.txt-fil:
Et enkelt XML-sitemap definert i en robot.txt-fil:
Eksemplet ovenfor forteller alle søkemotorer om ikke å få tilgang til katalogen /wp-admin/, og at XML-sitemap kan bli funnet på
Comments are preceded by a # enten plasseres ved starten av en linje eller etter et direktiv på samme linje. Alt etter # vil bli ignorert. Disse kommentarene er kun ment for mennesker.
Eksempel 1
Eksempel 2
Eksemplene ovenfor kommuniserer den samme meldingen.
Gjennomsøkingsforsinkelse i robots.txt
Crawl-delay direktivet er et uoffisielt direktiv som brukes for å forhindre overbelastning av servere med for mange forespørsler. Hvis søkemotorer er i stand til å overbelaste en server, er det bare en midlertidig løsning å legge til Crawl-delay i robots.txt-filen. Faktum er at nettstedet ditt kjører i et dårlig hostingmiljø og / eller at nettstedet ditt er feil konfigurert, og du bør fikse det så snart som mulig.
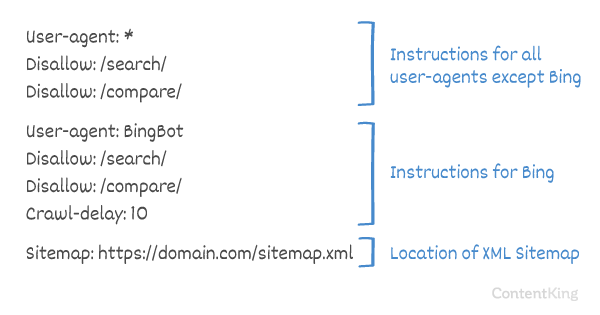
Måten søkemotorer håndterer Crawl-delay er forskjellig. Nedenfor forklarer vi hvordan store søkemotorer håndterer det.
Gjennomsøkingsforsinkelse og Google
Googles søkerobot, Googlebot, støtter ikke Crawl-delay -direktivet, så ikke bry deg med å definere en Googles gjennomsøkingsforsinkelse.
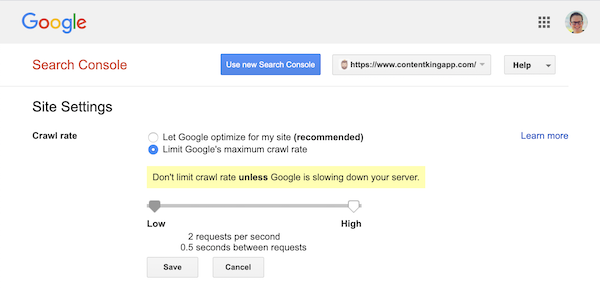
Google støtter imidlertid definering av en gjennomsøkingsfrekvens (eller «forespørselsrate» hvis du ) i Google Search Console.
- Logg på den gamle Google Search Console.
- Velg nettstedet du ønsker å definere gjennomsøkingsfrekvensen for.
- Det er bare en innstilling du kan tilpasse:
Crawl rate, med en glidebryter der du kan angi den foretrukne gjennomsøkningshastigheten. gjennomsøkningshastigheten er satt til «La Google optimalisere for nettstedet mitt (anbefales)».
Slik ser det ut i Google Search Console:
Gjennomsøkingsforsinkelse og Bing, Yahoo og Yandex
Bing, Yahoo og Yandex alle støtter Crawl-delay direktiv for gasspjelding av et nettsted. Tolkningen av gjennomsøkingsforsinkelsen er imidlertid litt annerledes, så sørg for å sjekke dokumentasjonen deres:
- Bing og Yahoo
- Yandex
Direktivet Crawl-delay bør plasseres rett etter Disallow eller Allow -direktivene.
Eksempel:
Gjennomsøkingsforsinkelse og Baidu
Baidu støtter ikke crawl-delay -direktivet, men det er mulig å registrere en Baidu Webmaster Tools-konto i som du kan kontrollere gjennomsøkingsfrekvensen, i likhet med Google Search Console.
Når skal du bruke en robots.txt-fil?
Vi anbefaler å alltid bruke en robots.txt-fil. Det er absolutt ingen skade å ha en, og det er et flott sted å gi søkemotordirektiv om hvordan de best kan gjennomsøke nettstedet ditt.

Robotene.txt kan være nyttig for å hindre at enkelte områder eller dokumenter på nettstedet blir gjennomsøkt og indeksert. Eksempler er for eksempel iscenesettelsessiden eller PDF-filer. Planlegg nøye hva som må indekseres av søkemotorer, og vær oppmerksom på at innhold som er gjort utilgjengelig gjennom robots.txt, fremdeles kan bli funnet av søkemotorrollere hvis det er lenket til fra andre områder på nettstedet.
Robots.txt beste fremgangsmåter
De beste metodene for robots.txt er kategorisert som følger:
- Plassering og filnavn
- Prioritetsrekkefølge
- Bare en gruppe direktiver per robot
- Vær så spesifikk som mulig
- Direktiver for alle roboter, mens du også inkluderer direktiver for en spesifikk robot
- Robots.txt-fil for hvert (under) domene.
- Motstridende retningslinjer: robots.txt kontra Google Search Console
- Overvåke robots.txt-filen din
- Ikke bruk noindex i robots.txt
- Forhindre UTF-8 BOM i robots.txt-filen
Plassering og filnavn
Robots.txt-filen skal alltid plasseres i th e root på et nettsted (i toppnivåkatalogen til verten) og bærer filnavnet robots.txt, for eksempel: . Vær oppmerksom på at URL-adressen til robots.txt-filen er, som enhver annen URL, mellom store og små bokstaver.
Hvis robots.txt-filen ikke finnes på standardplasseringen, vil søkemotorer anta at det ikke er noen direktiver og krype bort på nettstedet ditt.
Prioritetsrekkefølge
Det er viktig å merke seg at søkemotorer håndterer robots.txt-filer på en annen måte. Som standard vinner alltid det første samsvarende direktivet.
Men med Google og Bing-spesifisitet. For eksempel: et Allow -direktiv vinner over et Disallow -direktiv hvis tegnlengden er lengre.
Eksempel
I eksempel over alle søkemotorer, inkludert Google og Bing, har ikke tilgang til /about/ -katalogen, bortsett fra underkatalogen /about/company/.
Eksempel
I eksemplet ovenfor har ikke alle søkemotorer unntatt Google og Bing tilgang til /about/ -katalogen. Det inkluderer katalogen /about/company/.
Google og Bing har tilgang, fordi Allow -direktivet er lenger enn direktivet Disallow direktiv.
Bare en gruppe direktiver per robot
Du kan bare definere en gruppe direktiver per søkemotor. Å ha flere grupper av direktiver for en søkemotor forvirrer dem.
Vær så spesifikk som mulig
Disallow -direktivet utløser på delvis samsvar som vi vil. Vær så spesifikk som mulig når du definerer Disallow -direktivet for å forhindre utilsiktet å ikke tillate tilgang til filer.
Eksempel:
Eksemplet ovenfor gir ikke søkemotorer tilgang til:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Direktiver for alle roboter, samtidig som de inkluderer direktiver for en bestemt robot
For en robot bare en gruppe direktiver er gyldige. I tilfelle direktiver som er ment for alle roboter følges med direktiver for en spesifikk robot, vil bare disse spesifikke direktivene bli tatt i betraktning. For at den spesifikke roboten også skal følge retningslinjene for alle roboter, må du gjenta disse retningslinjene for den spesifikke roboten.
La oss se på et eksempel som vil gjøre dette klart:
Eksempel
Hvis du ikke vil at googlebot skal få tilgang til /secret/ og /not-launched-yet/, må du gjenta disse retningslinjene for googlebot spesifikt:
Vær oppmerksom på at robots.txt-filen din er offentlig tilgjengelig. Å ikke tillate nettstedsdeler der inne kan brukes som en angrepsvektor av personer med ondsinnet hensikt.

Robots.txt kan være farlig. Du forteller ikke bare søkemotorer hvor du ikke vil at de skal se, du forteller folk hvor du gjemmer dine skitne hemmeligheter.
Robots.txt-fil for hvert (under) domene
Robots.txt-direktiver gjelder for (under) domenet filen ligger på.
Eksempler
er gyldig for , men ikke for eller
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Vi bygde robots.txt endringssporing og varsling av denne grunn.
Vi ser det hele tiden: robots.txt-filer endres uten kunnskap om digital markedsføring team. Ikke vær den personen. Begynn å overvåke robots.txt-filen din og motta varsler når den endres!
Ikke bruk noindex i robots.txt
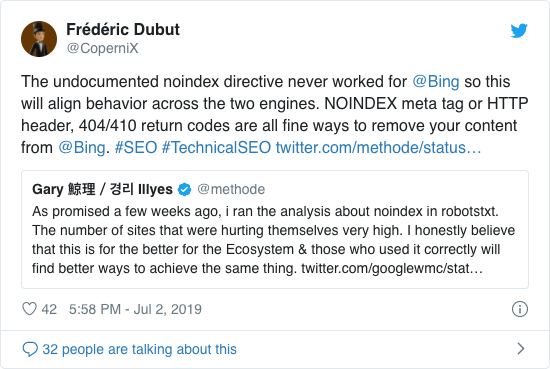
I mange år anbefalte Google allerede åpent å bruke det uoffisielle noindex-direktivet. Fra og med 1. september 2019 sluttet Google imidlertid å støtte det helt.
Det uoffisielle noindex-direktivet virket aldri i Bing, som bekreftet av Frédéric Dubut i denne tweeten:
Den beste måten å signalisere til søkemotorer om at sider ikke skal indekseres, er å bruke meta-robots-taggen eller X-Robots-Tag .
Forhindre UTF-8 BOM i robots.txt-fil
BOM står for byte-ordren, et usynlig tegn i begynnelsen av en fil som brukes til å indikere Unicode-koding av en tekstfil.
Mens Google sier at de ignorerer det valgfrie Unicode-bytebestillingsmerket i begynnelsen av robots.txt-filen, anbefaler vi at du forhindrer «UTF-8 BOM» fordi vi har sett det føre til problemer med tolkningen av robots.txt-filen av søkemotorer.
Selv om Google sier at de kan takle det, er det to grunner til å forhindre UTF-8 BOM:
- Du trenger ikke Du vil ikke ha noen tvetydighet rundt preferansene dine rundt gjennomsøking til søkemotorer.
- Det er andre søkemotorer der ute, som kanskje ikke er så tilgivende som Google hevder å være.
Eksempler på Robots.txt
I dette kapittelet dekker vi et bredt utvalg av eksempler på robots.txt-filer:
- Gi alle roboter tilgang til alt
- Tillat alle roboter tilgang til alt
- Alle Google-bots har ikke tilgang
- Alle Google-bots, bortsett fra Googlebot-nyheter, har ikke tilgang
- Googlebot og Slurp har ikke tilgang
- Alle roboter har ikke tilgang til to kataloger
- Alle roboter har ikke tilgang til en bestemt fil
- Googlebot har ikke tilgang til / admin / og Slurp har ikke tilgang til / private /
- Robots.txt-fil for WordPress
- Robots.txt-fil for Magento
Gi alle roboter tilgang til alt
Det er flere måter for å fortelle søkemotorer at de får tilgang til alle filene:
Eller å ha en tom robots.txt-fil eller ikke ha en robots.txt i det hele tatt.
Tillat alle roboter tilgang til alt
Eksemplet robots.txt nedenfor forteller alle søkemotorer om ikke å få tilgang til hele nettstedet:
Vær oppmerksom på at bare ET ekstra tegn kan utgjøre hele forskjellen.
Alle Google-bots har ikke tilgang
Vær oppmerksom på at når du ikke tillater Googlebot, gjelder dette alle Googlebots. Dette inkluderer Google-roboter som søker etter for eksempel nyheter (googlebot-news) og bilder (googlebot-images).
Alle Google-bots, bortsett fra Googlebot-nyheter, har ikke tilgang
Googlebot og Slurp har ikke tilgang
Alle roboter har ikke tilgang til to kataloger
Alle roboter har ikke tilgang til en bestemt fil
Googlebot har ikke tilgang til / admin / og Slurp har ikke tilgang til / private /
Robots.txt fil for WordPress
Robotene.txt-filen nedenfor er spesielt optimalisert for WordPress, forutsatt:
- Du vil ikke at din administrasjonsseksjon skal gjennomsøkes.
- Du vil ikke gjennomsøke de interne søkeresultatsidene.
- Du ønsker ikke å få gjennomsøkt tag- og forfatterssidene.
- Du trenger ikke t vil at din 404-side skal gjennomsøkes.
Vær oppmerksom på at denne robots.txt-filen fungerer i de fleste tilfeller, men du bør alltid justere den og teste den for å sikre at den gjelder din nøyaktig situasjon.
Robots.txt-fil for Magento
Robots.txt-filen nedenfor er spesielt optimalisert for Magento, og vil gi interne søkeresultater, påloggingssider, øktidentifikatorer og filtrert resultat sett som inneholder price, color, material og size kriterier utilgjengelige for gjennomsøkere.
Vær oppmerksom på at denne robots.txt-filen fungerer for de fleste Magento-butikker, men du bør alltid justere den og teste den for å sikre at den gjelder den eksakte situasjonen din.
Jeg vil fremdeles alltid se etter å blokkere interne søkeresultater i robots.txt på et hvilket som helst nettsted fordi disse typene søke-URL-er er uendelige og uendelige. Det er mye potensiale for Googlebot å komme i en båndfelle.
Hva er begrensningene for robots.txt-filen?
Robots.txt-filen inneholder direktiver
Selv om robots.txt respekteres godt av søk motorer, er det fremdeles et direktiv og ikke et mandat.
Sider som fremdeles vises i søkeresultatene
Sider som er utilgjengelige for søkemotorer på grunn av robotene.txt, men har lenker til dem kan fremdeles vises i søkeresultatene hvis de er lenket fra en side som er gjennomsøkt. Et eksempel på hvordan dette ser ut:

Det er mulig å fjerne disse nettadressene fra Google ved hjelp av Google Search Consoles verktøy for fjerning av nettadresser. Vær oppmerksom på at disse nettadressene bare blir «skjult» midlertidig. For at de skal holde seg utenfor Googles resultatsider, må du sende inn en forespørsel om å skjule nettadressene hver 180. dag.

Bruk robots.txt for å blokkere uønskede og sannsynligvis skadelige tilknyttede tilbakekoblinger. ikke bruk robots.txt i et forsøk på å forhindre at innhold blir indeksert av søkemotorer, da dette uunngåelig mislykkes. Bruk i stedet robotdirektiv noindex når det er nødvendig.
Robots.txt-filen er hurtigbufret opptil 24 timer
Google har indikert at en robot .txt-filen er vanligvis hurtigbufret i opptil 24 timer. Det er viktig å ta hensyn til dette når du gjør endringer i robots.txt-filen.
Det er uklart hvordan andre søkemotorer håndterer caching av robots.txt , men generelt sett er det best å unngå å cache robots.txt-filen til av oid-søkemotorer tar lengre tid enn nødvendig for å kunne hente endringene.
Robots.txt-filstørrelse
For robots.txt-filer støtter Google for øyeblikket en filstørrelsesgrense på 500 kibytes. (512 kilobyte). Alt innhold etter denne maksimale filstørrelsen kan ignoreres.
Det er uklart om andre søkemotorer har maksimal filstørrelse for robots.txt-filer.
Ofte stilte spørsmål om robots.txt
🤖 Hvordan ser et eksempel på robots.txt ut?
Her er et eksempel på innholdet i en robots.txt: User-agent: * Disallow:. Dette forteller alle gjennomsøkere at de kan få tilgang til alt.
⛔ Hva tillater ikke alle å gjøre i robots.txt?
Når du setter en robots.txt til «Ikke tillat alle», er du i bunn og grunn ber alle crawlere å holde seg utenfor. Ingen crawlere, inkludert Google, har tilgang til nettstedet ditt. Dette betyr at de ikke vil kunne gjennomsøke, indeksere og rangere nettstedet ditt. Dette vil føre til et enormt fall i organisk trafikk.
✅ Hva gjør Tillat alt i robots.txt?
Når du setter en robots.txt til «Tillat alt», forteller du hver søkerobot at de kan få tilgang til alle nettadressene på nettstedet. Det er ganske enkelt ingen regler for engasjement. Vær oppmerksom på at dette tilsvarer å ha en tom robots.txt, eller ikke ha noen robots.txt i det hele tatt.
🤔 Hvor viktig er robots.txt for SEO?
I generelt, er robots.txt-filen veldig viktig for SEO-formål. For større nettsteder er robots.txt viktig for å gi søkemotorer veldig klare instruksjoner om hvilket innhold du ikke får tilgang til.