Funkcja okna ROW_NUMBER ma wiele praktycznych zastosowań, znacznie wykraczających poza oczywiste potrzeby związane z rankingiem. W większości przypadków, gdy obliczasz numery wierszy, musisz je obliczyć w oparciu o jakąś kolejność i podać żądaną specyfikację kolejności w klauzuli kolejności okna funkcji. Jednak są przypadki, w których trzeba obliczyć numery wierszy w dowolnej kolejności; innymi słowy, oparty na porządku niedeterministycznym. Może to dotyczyć całego wyniku zapytania lub partycji. Przykłady obejmują przypisywanie unikatowych wartości do wierszy wynikowych, deduplikację danych i zwracanie dowolnego wiersza na grupę.
Zauważ, że konieczność przypisywania numerów wierszy w oparciu o porządek niedeterministyczny różni się od konieczności przypisywania ich w kolejności losowej. W pierwszym przypadku po prostu nie obchodzi Cię, w jakiej kolejności są przypisane i czy powtarzające się wykonania zapytania nadal przypisują te same numery wierszy do tych samych wierszy, czy nie. W przypadku tego drugiego można oczekiwać, że powtarzane wykonania będą nadal zmieniać, którym wierszom przypisano numery wierszy. W tym artykule omówiono różne techniki obliczania numerów wierszy w porządku niedeterministycznym. Nadzieja polega na znalezieniu techniki, która będzie niezawodna i optymalna.
Specjalne podziękowania dla Paula White’a za wskazówkę dotyczącą ciągłego składania, stałą technikę działania i za to, że zawsze jest świetnym źródłem informacji!
Gdy liczy się kolejność
Zacznę od przypadków, w których kolejność numerów wierszy ma znaczenie.
W moich przykładach użyję tabeli o nazwie T1. Użyj poniższego kodu, aby utworzyć tę tabelę i wypełnić ją przykładowymi danymi:
Rozważmy następujące zapytanie (nazwiemy je Query 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Tutaj chcesz, aby numery wierszy były przypisywane w ramach każdej grupy zidentyfikowanej przez grp kolumn, uporządkowane według kolumny datacol. Kiedy uruchomiłem to zapytanie w moim systemie, otrzymałem następujące dane wyjściowe:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Numery wierszy są tutaj przypisywane w częściowo deterministycznej, a częściowo niedeterministycznej kolejności. Rozumiem przez to, że masz pewność, że w tej samej partycji wiersz z większą wartością datacol otrzyma większą wartość numeru wiersza. Jednak ponieważ datacol nie jest unikatowy w ramach partycji grp, kolejność przypisywania numerów wierszy między wierszami z tymi samymi wartościami grp i datacol jest niedeterministyczna. Tak jest w przypadku wierszy o id wartości 2 i 11. Oba mają wartość A grp i wartość datacol 50. Kiedy wykonałem to zapytanie w moim systemie po raz pierwszy, wiersz o identyfikatorze 2 otrzymał wiersz numer 2 i wiersz o identyfikatorze 11 otrzymał wiersz numer 3. Nieważne prawdopodobieństwo, że zdarzy się to w praktyce w SQL Server; jeśli ponownie uruchomię zapytanie, teoretycznie wiersz o identyfikatorze 2 mógłby zostać przypisany do wiersza numer 3, a wiersz o identyfikatorze 11 mógłby zostać przypisany do wiersza numer 2.
Jeśli chcesz przypisać numery wierszy na podstawie w całkowicie deterministycznej kolejności, gwarantującej powtarzalne wyniki podczas wykonywania zapytania, o ile dane bazowe nie ulegają zmianie, kombinacja elementów w klauzulach partycjonowania i porządkowania okna musi być unikalna. W naszym przypadku można to osiągnąć, dodając identyfikator kolumny do klauzuli kolejności okien jako rozstrzygnięcie rozstrzygające. Klauzula OVER wyglądałaby wówczas następująco:
OVER (PARTITION BY grp ORDER BY datacol, id)
W każdym razie, podczas obliczania numerów wierszy w oparciu o jakąś sensowną specyfikację kolejności, jak w zapytaniu 1, SQL Server musi przetworzyć rzędy uporządkowane według kombinacji podziału okien i elementów porządkujących. Można to osiągnąć, pobierając wstępnie uporządkowane dane z indeksu lub sortując dane. W tej chwili na T1 nie ma indeksu obsługującego obliczenia ROW_NUMBER w zapytaniu 1, więc SQL Server musi wybrać sortowanie danych. Można to zobaczyć w planie zapytania 1 pokazanym na rysunku 1.
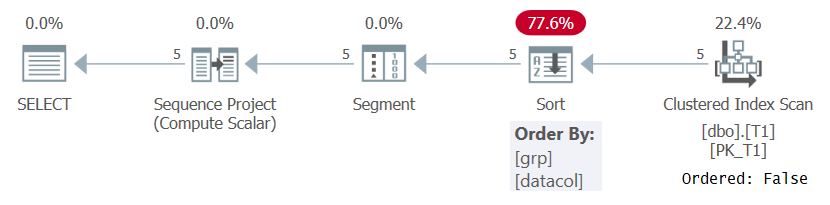 Rysunek 1: Plan dla zapytania 1 bez indeksu pomocniczego
Rysunek 1: Plan dla zapytania 1 bez indeksu pomocniczego
Zauważ, że plan skanuje dane z indeksu klastrowego z właściwością Ordered: False. Oznacza to, że skanowanie nie musi zwracać wierszy uporządkowanych według klucza indeksu. Dzieje się tak, ponieważ indeks klastrowy jest używany w tym miejscu tylko dlatego, że zdarza się, że obejmuje zapytanie, a nie ze względu na kolejność kluczy. Następnie plan stosuje sortowanie, co skutkuje dodatkowymi kosztami, skalowaniem N Log N i opóźnionym czasem odpowiedzi. Operator segmentu tworzy flagę wskazującą, czy wiersz jest pierwszym w partycji, czy nie. Na koniec operator projektu sekwencji przypisuje numery wierszy zaczynające się od 1 w każdej partycji.
Jeśli chcesz uniknąć sortowania, możesz przygotować indeks obejmujący z listą kluczy opartą na elementach partycjonowania i porządkowania oraz listą włączeń opartą na elementach pokrywających.Lubię myśleć o tym indeksie jako o indeksie POC (do partycjonowania, porządkowania i pokrywania). Oto definicja POC, która obsługuje nasze zapytanie:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Uruchom ponownie zapytanie 1:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Plan tego wykonania pokazano na rysunku 2.
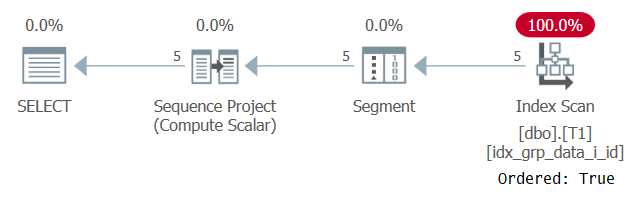 Rysunek 2: Plan dla zapytania 1 z indeksem POC
Rysunek 2: Plan dla zapytania 1 z indeksem POC
Zauważ, że tym razem plan skanuje indeks POC z właściwością Ordered: True. Oznacza to, że skanowanie gwarantuje, że wiersze zostaną zwrócone w kolejności klucza indeksu. Ponieważ dane są pobierane z indeksu z wyprzedzeniem, tak jak wymaga tego funkcja okna, nie ma potrzeby jawnego sortowania. Skalowanie tego planu jest liniowe, a czas odpowiedzi jest dobry.
Gdy kolejność nie ma znaczenia
Sprawy stają się nieco skomplikowane, gdy trzeba przypisać numery wierszy za pomocą całkowicie niedeterministycznej W takim przypadku naturalną rzeczą jest użycie funkcji ROW_NUMBER bez określania klauzuli kolejności okien. Najpierw sprawdźmy, czy pozwala na to standard SQL. Oto odpowiednia część standardu definiująca reguły składni dla okien funkcje:
Zwróć uwagę, że pozycja 6 zawiera listę funkcji < funkcja ntile >, < funkcja lead lub lag >, < ranga funkcja typu > lub ROW_NUMBER, a następnie pozycja 6a mówi, że dla funkcji < funkcja ntile >, < lead lub lag function >, RANK lub DENSE_RANK klauzula kolejności okien powinna b obecny. Nie ma wyraźnego języka stwierdzającego, czy ROW_NUMBER wymaga klauzuli kolejności okien, czy nie, ale wzmianka o funkcji w pozycji 6 i jej pominięcie w pozycji 6a może sugerować, że klauzula jest opcjonalna dla tej funkcji. Jest całkiem oczywiste, dlaczego funkcje takie jak RANK i DENSE_RANK wymagałyby klauzuli kolejności okien, ponieważ te funkcje specjalizują się w obsłudze powiązań, a powiązania istnieją tylko wtedy, gdy istnieje specyfikacja kolejności. Jednak z pewnością można zobaczyć, jak funkcja ROW_NUMBER może skorzystać na opcjonalnej klauzuli kolejności okien.
Spróbujmy więc obliczyć numery wierszy bez porządkowania okien w SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Ta próba skutkuje następującym błędem:
Funkcja „ROW_NUMBER” musi mieć klauzulę OVER z ORDER BY.
Rzeczywiście, jeśli sprawdzisz dokumentację SQL Server dotyczącą funkcji ROW_NUMBER, znajdziesz następujący tekst:
ORDER Klauzula BY określa kolejność, w jakiej wierszom przypisuje się swój unikalny ROW_NUMBER w ramach określonej partycji. Jest to wymagane. ”
Najwyraźniej klauzula kolejności okien jest obowiązkowa dla funkcji ROW_NUMBER w SQL Server . Nawiasem mówiąc, dotyczy to również Oracle.
Muszę powiedzieć, że nie jestem pewien, czy rozumiem powód za tym wymaganiem. Pamiętaj, że pozwalasz definiować numery wierszy w oparciu o częściowo niedeterministyczny porządek, jak w zapytaniu 1. Dlaczego więc nie pozwolić na niedeterminizm w całości? Może jest jakiś powód, o którym nie myślę. Jeśli możesz wymyślić taki powód, podziel się nim.
W każdym razie możesz argumentować, że jeśli nie obchodzi Cię zamówienie, biorąc pod uwagę, że klauzula zamówienia okien jest obowiązkowa, możesz określić dowolne zamówienie. Problem z tym podejściem polega na tym, że jeśli zamawiasz według jakiejś kolumny z zapytanych tabel, może to spowodować niepotrzebny spadek wydajności. Gdy nie ma odpowiedniego indeksu, płacisz za jawne sortowanie. Gdy istnieje indeks pomocniczy, ograniczasz silnik magazynu do strategii skanowania kolejności indeksów (zgodnie z listą połączoną z indeksami). Nie pozwalasz mu na większą elastyczność, jak zwykle, gdy kolejność nie ma znaczenia przy wyborze między skanem kolejności indeksów a skanowaniem kolejności alokacji (na podstawie stron IAM).
Jeden pomysł, który warto wypróbować polega na określeniu stałej, takiej jak 1, w klauzuli kolejności okien. Jeśli jest obsługiwany, możesz mieć nadzieję, że optymalizator jest wystarczająco inteligentny, aby zdać sobie sprawę, że wszystkie wiersze mają tę samą wartość, więc nie ma rzeczywistej trafności kolejności, a zatem nie ma potrzeby wymuszania sortowania ani skanowania kolejności indeksów. Oto zapytanie próbujące zastosować to podejście:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Niestety, SQL Server nie obsługuje tego rozwiązania. Generuje następujący błąd:
Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują indeksów całkowitych jako wyrażeń klauzuli ORDER BY.
Najwyraźniej SQL Server zakłada, że jeśli używasz stałej liczby całkowitej w klauzuli kolejności okien, reprezentuje ona porządkową pozycję elementu na liście SELECT, tak jak wtedy, gdy określasz liczbę całkowitą w prezentacji ORDER Klauzula BY. W takim przypadku inną opcją, którą warto spróbować, jest określenie stałej niecałkowitej, na przykład:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Okazuje się, że to rozwiązanie również nie jest obsługiwane. SQL Server generuje następujący błąd:
Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażenia klauzuli ORDER BY.
Najwyraźniej klauzula kolejności okien nie obsługuje żadnego rodzaju stałej.
Do tej pory dowiedzieliśmy się następujących rzeczy o znaczeniu porządkowania okien funkcji ROW_NUMBER w SQL Server:
- ORDER BY jest wymagane.
- Nie można porządkować według stałej liczby całkowitej, ponieważ SQL Server uważa, że „próbujesz określić pozycję porządkową w SELECT.
- Nie można uporządkować według dowolny rodzaj stałej.
Wniosek jest taki, że powinieneś uporządkować wyrażenia, które nie są stałymi. Oczywiście możesz uporządkować według listy kolumn z zapytanych tabel. Ale staramy się znaleźć wydajne rozwiązanie, w którym optymalizator zda sobie sprawę, że nie ma znaczenia w kolejności.
Stałe zwijanie
Jak dotąd wniosek jest taki, że nie można używać stałych w the Klauzula kolejności okien ROW_NUMBER, ale co z wyrażeniami opartymi na stałych, na przykład w następującym zapytaniu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Jednak ta próba pada ofiarą procesu znanego jako stały zwijanie, co zwykle ma pozytywny wpływ na wydajność zapytań. Ideą tej techniki jest zwiększenie wydajności zapytań poprzez zawinięcie wyrażenia opartego na stałych do stałych wynikowych na wczesnym etapie przetwarzania zapytania. Szczegółowe informacje o tym, jakie wyrażenia mogą być składane na stałe, można znaleźć tutaj. Nasze wyrażenie 1 + 0 jest zawijane do 1, co powoduje ten sam błąd, który otrzymałeś podczas bezpośredniego określania stałej 1:
Funkcje w oknie, agregaty i funkcje NEXT VALUE FOR nie obsługują indeksów całkowitych jako wyrażeń klauzuli ORDER BY.
Podobna sytuacja napotkałabyś podczas próby połączenia dwóch literałów ciągu znaków, na przykład:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Otrzymujesz ten sam błąd, który wystąpił podczas bezpośredniego określania literału „No Order”:
w oknie funkcje, agregaty i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Dziwaczny świat – błędy, które zapobiegają błędom
Życie jest pełne niespodzianek…
Jedyną rzeczą, która zapobiega ciągłemu zwijaniu, jest sytuacja, w której wyrażenie normalnie spowodowałoby błąd. Na przykład wyrażenie 2147483646 + 1 może być składane na stałe, ponieważ daje w wyniku prawidłową wartość typu INT. W rezultacie próba uruchomienia następującego zapytania kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Funkcje okienkowe, agregaty i NASTĘPNA WARTOŚĆ Funkcje FOR nie obsługują indeksów całkowitych jako wyrażeń klauzuli ORDER BY.
Jednak wyrażenie 2147483647 + 1 nie może być składane na stałe, ponieważ taka próba spowodowałaby błąd przepełnienia INT. Konsekwencje dotyczące zamawiania są dość interesujące. Spróbuj wykonać następujące zapytanie (nazwiemy to Zapytaniem 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Dziwne, to zapytanie zostało pomyślnie uruchomione! Dzieje się tak, że z jednej strony SQL Server nie stosuje stałego zwijania, a zatem porządkowanie jest oparte na wyrażeniu, które nie jest pojedynczą stałą. Z drugiej strony optymalizator stwierdza, że wartość porządkowa jest taka sama dla wszystkich wierszy, więc całkowicie ignoruje wyrażenie porządkowe. Zostało to potwierdzone podczas analizy planu dla tego zapytania, jak pokazano na rysunku 3.
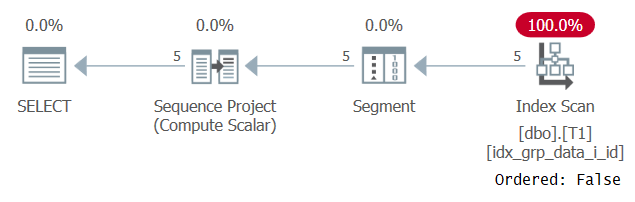 Rysunek 3: Plan dla zapytania 2
Rysunek 3: Plan dla zapytania 2
Obserwuj że plan skanuje indeks obejmujący z właściwością Ordered: False. To był właśnie nasz cel wydajności.
W podobny sposób poniższe zapytanie wiąże się z udaną próbą ciągłego zwijania i dlatego kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują indeksów całkowitych jako wyrażeń klauzuli ORDER BY.
Następujące zapytanie wiąże się z nieudaną próbą stałego zwijania i dlatego kończy się powodzeniem, generując plan pokazany wcześniej na rysunku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Następujące zapytanie obejmuje udaną próbę zwinięcia stałej (literał VARCHAR „1” jest niejawnie konwertowany na INT 1, a następnie 1 + 1 jest zawijany do 2) i dlatego kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują indeksów całkowitych jako wyrażeń klauzuli ORDER BY.
Poniższe zapytanie obejmuje nieudana stała próba zawinięcia (nie można przekonwertować „A” na INT) i dlatego kończy się powodzeniem, generowanie planu pokazanego wcześniej na rysunku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Szczerze mówiąc, nawet jeśli ta dziwaczna technika osiąga nasz pierwotny cel wydajności, nie mogę powiedzieć, że uważam ją za bezpieczną i dlatego nie czuję się komfortowo na niej polegając.
Stałe czasu działania oparte na funkcjach
Kontynuując poszukiwanie dobrego rozwiązania do obliczania numerów wierszy w porządku niedeterministycznym, istnieje kilka technik, które wydają się bezpieczniejsze niż ostatnie dziwaczne rozwiązanie: użycie stałych czasu wykonywania opartych na funkcjach, podzapytanie oparte na stałej, użycie kolumna z aliasami oparta na stałej i przy użyciu zmiennej.
Jak wyjaśniam w T-SQL błędy, pułapki i najlepsze praktyki – determinizm, większość funkcji w T-SQL jest oceniana tylko raz na odwołanie w zapytaniu – a nie raz na wiersz. Dzieje się tak nawet w przypadku większości niedeterministycznych funkcji, takich jak GETDATE i RAND. Jest bardzo niewiele wyjątków od tej reguły, takich jak funkcje NEWID i CRYPT_GEN_RANDOM, które są oceniane raz na wiersz. Większość funkcji, takich jak GETDATE, @@ SPID i wiele innych, jest oceniana raz na początku zapytania, a ich wartości są następnie traktowane jako stałe czasu wykonywania. Odwołanie do takich funkcji nie jest składane na stałe. Te cechy sprawiają, że stała czasu wykonywania, która jest oparta na funkcji, jest dobrym wyborem jako element porządkujący okna i rzeczywiście wydaje się, że T-SQL ją obsługuje. Jednocześnie optymalizator zdaje sobie sprawę, że w praktyce nie ma porządkowania trafności, co pozwala uniknąć niepotrzebnych kar za wydajność.
Oto przykład użycia funkcji GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
To zapytanie pobiera ten sam plan, co pokazany wcześniej na rysunku 3.
Oto kolejny przykład użycia funkcji @@ SPID (zwracający identyfikator bieżącej sesji):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
A co z funkcją PI? Spróbuj wykonać następujące zapytanie:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Ten kończy się niepowodzeniem z następującym błędem:
Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Funkcje takie jak GETDATE i @@ SPID są ponownie oceniane raz na wykonanie planu, więc nie mogą uzyskać stałe składane. PI reprezentuje zawsze tę samą stałą i dlatego jest stała składana.
Jak wspomniano wcześniej, jest bardzo niewiele funkcji, które są oceniane raz na wiersz, na przykład NEWID i CRYPT_GEN_RANDOM. To sprawia, że są złym wyborem jako element porządkujący okna, jeśli potrzebujesz porządku niedeterministycznego – nie mylić z kolejnością losową. Po co płacić niepotrzebną karę sortową?
Oto przykład użycia funkcji NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Plan dla tego zapytania pokazano na rysunku 4, potwierdzając, że SQL Server dodał jawnie sortowanie na podstawie wyniku funkcji.
 Rysunek 4: Plan dla zapytania 3
Rysunek 4: Plan dla zapytania 3
Jeśli chcesz przypisać numery wierszy w kolejności losowej, to jest technika, której chcesz użyć. Musisz tylko mieć świadomość, że wiąże się to z kosztami sortowania.
Korzystanie z podzapytania
Możesz również użyć podzapytania opartego na stałej jako wyrażenia porządkującego okno (np. ORDER BY (WYBIERZ „Brak zamówienia”)). Również w przypadku tego rozwiązania optymalizator SQL Server rozpoznaje, że nie ma znaczenia w kolejności, a zatem nie narzuca niepotrzebnego sortowania ani nie ogranicza możliwości silnika pamięci masowej do tych, które muszą gwarantować porządek. Jako przykład spróbuj uruchomić następujące zapytanie:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Otrzymasz ten sam plan, który pokazano wcześniej na rysunku 3.
Jedna z wielkich korzyści tej techniki polega na tym, że możesz dodać swój osobisty charakter.Może naprawdę lubisz wartości NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Może naprawdę podoba Ci się określona liczba:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Może chcesz wysłać komuś wiadomość:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Masz rację.
Wykonalne, ale niezręczne
Istnieje kilka technik, które działają, ale są nieco niezręczne. Jednym z nich jest zdefiniowanie aliasu kolumny dla wyrażenia opartego na stałej, a następnie użycie tego aliasu kolumny jako elementu porządkowania okna. Możesz to zrobić za pomocą wyrażenia tabeli lub operatora CROSS APPLY i konstruktora wartości tabeli. Oto przykład tego ostatniego:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Otrzymasz taki sam plan, jak pokazany wcześniej na rysunku 3.
Inną opcją jest użycie zmiennej jako element porządkowania okien:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
To zapytanie również pobiera plan pokazany wcześniej na Rysunku 3.
Co jeśli używam własnego UDF ?
Można by pomyśleć, że użycie własnego UDF, który zwraca stałą, może być dobrym wyborem jako element porządkujący okna, gdy chce się uporządkować niedeterministyczny, ale tak nie jest. Jako przykład rozważ następującą definicję UDF:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Spróbuj użyć UDF jako klauzuli porządkowania okien, na przykład (nazwiemy to Query 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Przed SQL Server 2019 (lub poziomem zgodności równoległej < 150) funkcje zdefiniowane przez użytkownika są oceniane według wiersza . Nawet jeśli zwracają stałą, nie są wstawiane. W konsekwencji z jednej strony można użyć takiego UDF jako elementu porządkującego okno, ale z drugiej strony skutkuje to karą sortowania. Potwierdza to analiza planu dla tego zapytania, jak pokazano na rysunku 5.
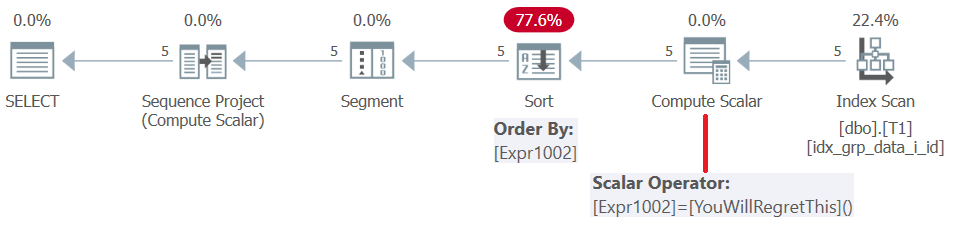 Rysunek 5: Plan zapytania 4
Rysunek 5: Plan zapytania 4
Począwszy od SQL Server 2019, na poziomie zgodności > = 150, takie funkcje zdefiniowane przez użytkownika są wstawiane, co jest w większości świetną rzeczą, ale w naszym przypadku powoduje błąd:
Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Zatem użycie funkcji UDF opartej na stała, ponieważ element porządkowania okien wymusza sortowanie lub błąd w zależności od używanej wersji programu SQL Server i poziomu zgodności bazy danych. Krótko mówiąc, nie rób tego.
Podzielone na partycje numery wierszy z niedeterministycznym porządkiem
Typowym przypadkiem użycia dla podzielonych na partycje numerów wierszy na podstawie niedeterministycznej kolejności jest zwrócenie dowolnego wiersza na grupę. Biorąc pod uwagę, że z definicji element partycjonujący istnieje w tym scenariuszu, można by pomyśleć, że bezpieczną techniką w takim przypadku byłoby użycie elementu partycjonującego okno również jako elementu porządkującego okna. Pierwszym krokiem jest obliczenie numerów wierszy w następujący sposób:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Plan dla tego zapytania pokazano na rysunku 6.
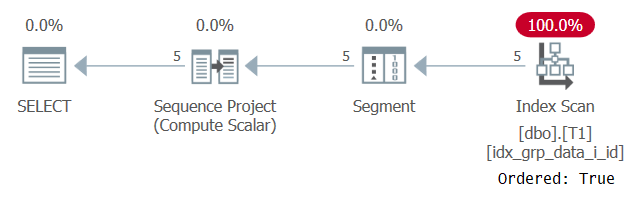 Rysunek 6: Planowanie zapytania 5
Rysunek 6: Planowanie zapytania 5
Przyczyną skanowania naszego indeksu pomocniczego za pomocą właściwości Ordered: True jest to, że SQL Server musi przetwarzać wiersze każdej partycji jako pojedyńcza jednostka. Tak jest przed filtrowaniem. Jeśli filtrujesz tylko jeden wiersz na partycję, jako opcje dostępne są zarówno algorytmy oparte na zamówieniach, jak i na podstawie skrótu.
Drugim krokiem jest umieszczenie zapytania z obliczeniem numeru wiersza w wyrażeniu tabeli i w zewnętrzne zapytanie filtruje wiersz z numerem 1 w każdej partycji, na przykład:
Teoretycznie ta technika powinna być bezpieczna, ale Paul White znalazł błąd, który pokazuje, że używając tej metody można uzyskać atrybuty z różne wiersze źródłowe w zwróconym wierszu wyników na partycję. Używanie stałej czasu wykonywania opartej na funkcji lub podzapytaniu opartym na stałej, ponieważ element porządkujący wydaje się być bezpieczny nawet w tym scenariuszu, więc upewnij się, że zamiast tego używasz rozwiązania takiego jak następujące:
Nikt przejdzie w ten sposób bez mojej zgody
Próba obliczenia numerów wierszy w oparciu o porządek niedeterministyczny jest powszechną potrzebą. Byłoby miło, gdyby T-SQL po prostu uczynił klauzulę kolejności okna opcjonalną dla funkcji ROW_NUMBER, ale tak nie jest. Jeśli nie, byłoby miło, gdyby przynajmniej pozwalało na użycie stałej jako elementu porządkującego, ale to też nie jest obsługiwana opcja.Ale jeśli ładnie zapytasz, w formie podzapytania opartego na stałej lub stałej czasu wykonania opartej na funkcji, SQL Server na to pozwoli. To są dwie opcje, które najbardziej mi odpowiadają. Nie czuję się komfortowo z dziwacznymi błędnymi wyrażeniami, które wydają się działać, więc nie mogę polecić tej opcji.