Robots Plik .txt zawiera dyrektywy dla wyszukiwarek. Możesz go użyć, aby uniemożliwić wyszukiwarkom indeksowanie określonych części witryny i udzielić wyszukiwarkom przydatnych wskazówek, jak najlepiej indeksować Twoją witrynę. Plik robots.txt odgrywa dużą rolę w SEO.
Podczas implementacji pliku robots.txt należy pamiętać o następujących sprawdzonych metodach:
- Zachowaj ostrożność podczas wprowadzania zmian w robots.txt: ten plik może spowodować, że duże części Twojej witryny będą niedostępne dla wyszukiwarek.
- Plik robots.txt powinien znajdować się w katalogu głównym witryny (np.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httplubhttps). - Różne wyszukiwarki różnie interpretują dyrektywy. Domyślnie pierwsza zgodna dyrektywa zawsze wygrywa. Jednak dzięki Google i Bing wygrywa specyficzność.
- Unikaj używania dyrektywy opóźnienia indeksowania dla wyszukiwarek w jak największym stopniu.
Co to jest plik robots.txt?
Plik robots.txt informuje wyszukiwarki, jakie są zasady zaangażowania w Twojej witrynie. Duża część SEO polega na wysyłaniu odpowiednich sygnałów do wyszukiwarek, a plik robots.txt jest jednym ze sposobów przekazywania wyszukiwarkom informacji o preferencjach dotyczących indeksowania.
W 2019 roku widzieliśmy całkiem sporo pewne zmiany związane ze standardem robots.txt: Google zaproponował rozszerzenie protokołu Robots Exclusion Protocol i udostępnił jego parser robots.txt.
TL; DR
- Roboty Google Interpreter .txt jest dość elastyczny i zaskakująco wybaczający.
- W przypadku dyrektyw powodujących pomyłkę Google popełnia błędy i zakłada, że sekcje powinny być ograniczone, a nie nieograniczone.
Wyszukiwarki regularnie sprawdzają plik robots.txt witryny, aby sprawdzić, czy istnieją instrukcje dotyczące indeksowania witryny. Nazywamy te instrukcje dyrektywami.
Jeśli nie ma pliku robots.txt lub nie ma odpowiednich dyrektyw, wyszukiwarki zaindeksują całą witrynę.
Chociaż wszystkie główne wyszukiwarki szanują pliku robots.txt, wyszukiwarki mogą zdecydować o zignorowaniu (części) pliku robots.txt. Chociaż dyrektywy w pliku robots.txt są silnym sygnałem dla wyszukiwarek, należy pamiętać, że plik robots.txt to zestaw opcjonalnych dyrektyw dla wyszukiwarek, a nie nakaz.

Robots.txt to najbardziej wrażliwy plik w świecie SEO. Pojedynczy znak może zepsuć całą witrynę.
Terminologia związana z plikiem robots.txt
Plik robots.txt to implementacja standardu wykluczania robotów lub nazywany także protokół wykluczania robotów.
Dlaczego powinieneś przejmować się plikiem robots.txt?
Plik robots.txt odgrywa istotną rolę z punktu widzenia SEO. Informuje wyszukiwarki, jak najlepiej indeksować Twoją witrynę.
Korzystając z pliku robots.txt, możesz uniemożliwić wyszukiwarkom dostęp do określonych części witryny, zapobiegać powielaniu treści i udzielać wyszukiwarkom przydatnych wskazówek może sprawniej indeksować Twoją witrynę.
Zachowaj ostrożność podczas wprowadzania zmian w pliku robots.txt: ten plik może spowodować, że duże części Twojej witryny będą niedostępne dla wyszukiwarek.

Plik Robots.txt jest często nadużywany do ograniczania powielonych treści, przez co zabijanie linków wewnętrznych, więc bądź z tym bardzo ostrożny. Moja rada jest taka, aby używać go tylko w przypadku plików lub stron, których wyszukiwarki nigdy nie powinny widzieć lub które mogą znacząco wpłynąć na indeksowanie, jeśli zostaną do nich wpuszczone. Typowe przykłady: obszary logowania, które generują wiele różnych adresów URL, obszary testowe lub w których może istnieć wiele aspektów nawigacji. I pamiętaj, aby monitorować plik robots.txt pod kątem wszelkich problemów lub zmian.

Ogromna większość problemów z plikami robots.txt, które widzę, można podzielić na trzy grupy:
- Niewłaściwa obsługa symboli wieloznacznych. Dość często zdarza się, że blokowane są części witryny, które miały zostać zablokowane. Czasami, jeśli nie jesteś ostrożny, dyrektywy mogą również wchodzić ze sobą w konflikt.
- Ktoś, na przykład programista, dokonał zmiany nieoczekiwanie (często podczas wypychania nowego kodu) i nieumyślnie zmienił plik robots.txt bez Twojej wiedzy.
- Uwzględnienie dyrektyw, które nie należą do pliku robots.txt. Plik Robots.txt jest standardem internetowym i jest nieco ograniczony. Często widzę, jak programiści tworzą dyrektywy, które po prostu nie działają (przynajmniej w przypadku większości robotów). Czasami jest to nieszkodliwe, czasami nie tak bardzo.
Przykład
Spójrzmy na przykład, aby to zilustrować:
Ty Prowadzisz witrynę eCommerce, a odwiedzający mogą używać filtra, aby szybko przeszukiwać Twoje produkty. Ten filtr generuje strony, które w zasadzie pokazują te same treści, co inne strony. Działa to świetnie dla użytkowników, ale dezorientuje wyszukiwarki, ponieważ tworzy zduplikowaną treść.
Nie chcesz, aby wyszukiwarki indeksowały te odfiltrowane strony i marnowały swój cenny czas na te adresy URL z przefiltrowaną treścią. Dlatego należy skonfigurować reguły Disallow, aby wyszukiwarki nie miały dostępu do tych filtrowanych stron produktów.
Zapobieganie powielaniu treści można również wykonać za pomocą kanonicznego adresu URL lub metatag robots, jednak nie dotyczą one zezwalania wyszukiwarkom na przeszukiwanie tylko ważnych stron.
Użycie kanonicznego adresu URL lub metatagu robots nie uniemożliwi wyszukiwarkom indeksowania tych stron. Zapobiegnie to tylko wyświetlaniu tych stron przez wyszukiwarki w wynikach wyszukiwania. Ponieważ wyszukiwarki mają ograniczony czas na indeksowanie witryny, ten czas należy poświęcić na strony, które mają pojawiać się w wyszukiwarkach.
Nieprawidłowo skonfigurowany plik robots.txt może obniżać wydajność SEO. Sprawdź, czy tak jest w przypadku Twojej witryny od razu!

To bardzo proste narzędzie, ale plik robots.txt może powodować wiele problemów, jeśli nie jest poprawnie skonfigurowany, szczególnie dla większych witryn. Bardzo łatwo jest popełniać błędy, takie jak blokowanie całej witryny po wdrożeniu nowego projektu lub CMS lub nie blokowanie sekcji witryny, które powinny być prywatne. W przypadku większych witryn bardzo ważne jest zapewnienie skutecznego indeksowania przez Google, a dobrze zorganizowany plik robots.txt jest podstawowym narzędziem w tym procesie.
Musisz poświęcić trochę czasu, aby dowiedzieć się, które sekcje witryny najlepiej trzymać z daleka. od Google, aby wydawali jak najwięcej zasobów na indeksowanie stron, na których naprawdę Ci zależy.
Jak wygląda plik robots.txt?
Przykład tego, jak prosty plik robots.txt dla witryny WordPress może wygląda następująco:
Wyjaśnijmy anatomię pliku robots.txt na podstawie powyższego przykładu:
- User-agent:
user-agentwskazuje, dla którego wyszukiwania silniki, o których mowa w dyrektywach. -
*: oznacza to, że dyrektywy są przeznaczone dla wszystkich wyszukiwarek. -
Disallow: jest to dyrektywa wskazująca, jaka zawartość nie jest dostępna dlauser-agent. -
/wp-admin/: to jestpath, który jest niedostępny dlauser-agent.
Podsumowując: ten plik robots.txt mówi wszystkim wyszukiwarkom, aby trzymały się z dala od katalogu /wp-admin/.
Przeanalizujmy różne szczegółowe informacje o składnikach plików robots.txt:
- User-agent
- Disallow
- Zezwalaj
- Mapa witryny
- Opóźnienie indeksowania
Klient użytkownika w pliku robots.txt
Każda wyszukiwarka powinna identyfikować się za pomocą user-agent. Roboty Google identyfikują się jako Googlebot, na przykład roboty Yahoo jako Slurp, a robot Binga jako BingBot i tak dalej.
Rekord user-agent definiuje początek grupy dyrektyw. Wszystkie dyrektywy pomiędzy pierwszym user-agent a następnym user-agent rekordem są traktowane jako dyrektywy dla pierwszego user-agent.
Dyrektywy mogą dotyczyć określonych klientów użytkownika, ale mogą też mieć zastosowanie do wszystkich klientów użytkownika. W takim przypadku używany jest symbol wieloznaczny: User-agent: *.
Dyrektywa Disallow w pliku robots.txt
Możesz zabronić wyszukiwarkom dostępu określone pliki, strony lub sekcje Twojej witryny. Odbywa się to za pomocą dyrektywy Disallow. Po dyrektywie Disallow następuje path, do którego nie należy uzyskiwać dostępu. Jeśli nie zdefiniowano path, dyrektywa jest ignorowana.
Przykład
W tym przykładzie wszystkie wyszukiwarki mają nie uzyskiwać dostępu do katalogu /wp-admin/.
Zezwól na dyrektywę w pliku robots.txt
Dyrektywa Allow służy do przeciwdziałania dyrektywie Disallow. Dyrektywa Allow jest obsługiwana przez Google i Bing. Używając razem dyrektyw Allow i Disallow, możesz wskazać wyszukiwarkom, że mogą uzyskać dostęp do określonego pliku lub strony w katalogu, który jest w inny sposób niedozwolony. Po dyrektywie Allow następuje path, do którego można uzyskać dostęp. Jeśli nie zdefiniowano path, dyrektywa jest ignorowana.
Przykład
W powyższym przykładzie żadne wyszukiwarki nie mają dostępu do /media/, z wyjątkiem pliku /media/terms-and-conditions.pdf.
Ważne: podczas korzystania z Allow i Disallow dyrektywy razem, pamiętaj, aby nie używać symboli wieloznacznych, ponieważ może to prowadzić do sprzecznych dyrektyw.
Przykład sprzecznych dyrektyw
Wyszukiwarki nie będą wiedzieć, co zrobić z adresem URL . Nie jest dla nich jasne, czy mają dostęp. Gdy dyrektywy nie są jasne dla Google, zostaną zastosowane z najmniej restrykcyjną dyrektywą, co w tym przypadku oznacza, że w rzeczywistości będą miały dostęp do
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt to jedna z funkcji, które najczęściej widzę zaimplementowane nieprawidłowo, więc nie blokuje tego, co chcieli zablokować, lub blokuje więcej, niż oczekiwali i ma negatywny wpływ na ich witrynę. Robots.txt to bardzo potężne narzędzie, ale zbyt często jest nieprawidłowo konfigurowane.
Używanie symboli wieloznacznych *
Nie tylko można użyć symbolu wieloznacznego do zdefiniowania user-agent, ale można go również użyć do dopasuj adresy URL. Symbol wieloznaczny jest obsługiwany przez Google, Bing, Yahoo i Ask.
Przykład
W powyższym przykładzie żadna wyszukiwarka nie ma dostępu do adresów URL zawierających znak zapytania (?).

Programiści lub właściciele witryn często myślą, że mogą używać wszelkiego rodzaju wyrażeń regularnych w pliku robots.txt, podczas gdy w rzeczywistości poprawna jest tylko bardzo ograniczona liczba dopasowań do wzorca – na przykład symbole wieloznaczne (
*). Wydaje się, że od czasu do czasu występuje pomyłka między plikami .htaccess i robots.txt.
Używanie końca adresu URL $
Aby wskazać koniec adresu URL, możesz użyć znaku dolara ($) na końcu path.
Przykład
W powyższym przykładzie wyszukiwarki nie mają dostępu do wszystkich adresów URL kończących się na .php . Adresy URL z parametrami, np. nie będzie niedozwolone, ponieważ adres URL nie kończy się po .php.
Dodaj mapę witryny do pliku robots. txt
Mimo że plik robots.txt został wymyślony, aby poinformować wyszukiwarki, które strony nie mają indeksować, plik robots.txt może być również używany do wskazywania wyszukiwarkom mapy witryny XML. Jest to obsługiwane przez Google, Bing, Yahoo i Ask.
Do mapy witryny XML należy odnosić się jako bezwzględny adres URL. Adres URL nie musi znajdować się na tym samym hoście co plik robots.txt.
Odwołanie się do mapy witryny XML w pliku robots.txt jest jedną z najlepszych praktyk, które zawsze zalecamy, mimo że być może już przesłałeś mapę witryny XML w Google Search Console lub Bing Webmaster Tools. Pamiętaj, że istnieje więcej wyszukiwarek.
Pamiętaj, że w pliku robots.txt można odwołać się do wielu map witryn XML.
Przykłady
Wiele Mapy witryn XML zdefiniowane w pliku robots.txt:
Pojedyncza mapa witryny XML zdefiniowana w pliku robots.plik txt:
Powyższy przykład informuje wszystkie wyszukiwarki, aby nie uzyskiwały dostępu do katalogu /wp-admin/ i że mapę witryny XML można znaleźć pod adresem
Comments are preceded by a # i można być umieszczane na początku wiersza lub po dyrektywie w tym samym wierszu. Wszystko po tagu # będzie ignorowane. Te komentarze są przeznaczone wyłącznie dla ludzi.
Przykład 1
Przykład 2
Powyższe przykłady przekazują ten sam komunikat.
Opóźnienie indeksowania w pliku robots.txt
Crawl-delay jest nieoficjalną dyrektywą używaną do zapobiegania przeciążaniu serwerów zbyt dużą liczbą żądań. Jeśli wyszukiwarki mogą przeciążyć serwer, dodanie Crawl-delay do pliku robots.txt jest tylko tymczasowym rozwiązaniem. Faktem jest, że Twoja witryna działa w kiepskim środowisku hostingowym i / lub jest nieprawidłowo skonfigurowana. Należy to naprawić jak najszybciej.
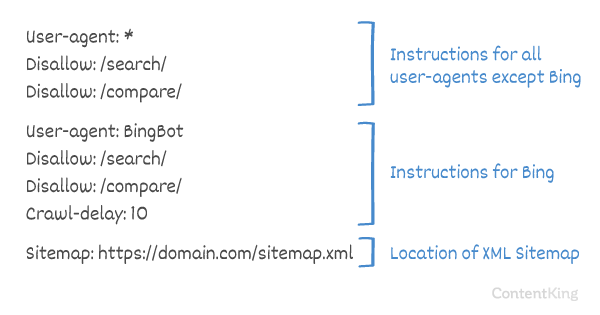
Różni się sposób, w jaki wyszukiwarki obsługują Crawl-delay. Poniżej wyjaśniamy, jak radzą sobie z tym główne wyszukiwarki.
Opóźnienie indeksowania i Google
Robot Google, Googlebot, nie obsługuje Crawl-delay, więc nie przejmuj się definiowaniem opóźnienia indeksowania Google.
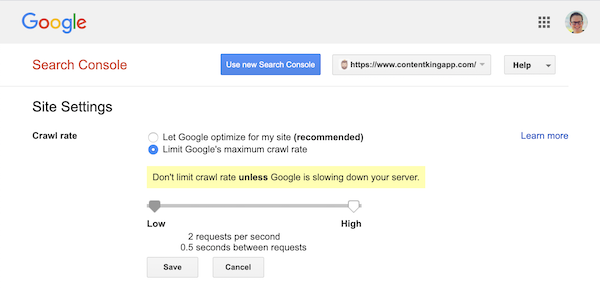
Jednak Google obsługuje definiowanie szybkości indeksowania (lub „szybkości żądań”, jeśli chcesz ) w Google Search Console.
- Zaloguj się do starej Google Search Console.
- Wybierz witrynę, którą chcesz zdefiniować szybkość indeksowania.
- Jest tylko jedno ustawienie, które możesz dostosować:
Crawl rate, za pomocą suwaka, za pomocą którego możesz ustawić preferowaną szybkość indeksowania. Domyślnie szybkość indeksowania jest ustawiona na „Pozwól Google na optymalizację dla mojej witryny (zalecane)”.
Tak to wygląda w Google Search Console:
Crawl-delay oraz Bing, Yahoo i Yandex
Bing, Yahoo i Yandex wszystkie obsługują Crawl-delay, aby ograniczyć indeksowanie witryny. Ich interpretacja opóźnienia indeksowania jest jednak nieco inna, więc koniecznie sprawdź ich dokumentację:
- Bing i Yahoo
- Yandex
Dyrektywę Crawl-delay należy umieścić bezpośrednio po dyrektywach Disallow lub Allow.
Przykład:
Crawl-delay i Baidu
Baidu nie obsługuje dyrektywy crawl-delay, jednak można zarejestrować konto Baidu Webmaster Tools w które możesz kontrolować częstotliwość indeksowania, podobnie jak w Google Search Console.
Kiedy używać pliku robots.txt?
Zalecamy, aby zawsze używać pliku robots.txt. Nie ma absolutnie nic złego w ich posiadaniu i jest to świetne miejsce, aby przekazać wyszukiwarkom wytyczne dotyczące najlepszego indeksowania Twojej witryny.

Plik robots.txt może być przydatny, aby uniemożliwić pobieranie i indeksowanie określonych obszarów lub dokumentów w witrynie. Przykładami są na przykład witryna pomostowa lub pliki PDF. Dokładnie zaplanuj, co musi zostać zaindeksowane przez wyszukiwarki, i pamiętaj, że treści, które zostały zablokowane przez plik robots.txt, mogą nadal zostać znalezione przez roboty wyszukiwarek, jeśli prowadzą do nich linki z innych obszarów witryny.
Montse Cano, Montse Cano
Robots.txt – sprawdzone metody
Sprawdzone metody w pliku robots.txt są podzielone na następujące kategorie:
- Lokalizacja i nazwa pliku
- Kolejność pierwszeństwa
- Tylko jedna grupa dyrektyw na robota
- Podaj jak najwięcej szczegółów
- Dyrektywy dla wszystkich robotów, uwzględniając jednocześnie dyrektywy dla konkretnego robota
- Plik Robots.txt dla każdej (pod) domeny.
- Sprzeczne wytyczne: plik robots.txt a Google Search Console
- Monitoruj plik robots.txt
- Nie używaj noindex w pliku robots.txt
- Zapobiegaj BOM UTF-8 w pliku robots.txt
Lokalizacja i nazwa pliku
Plik robots.txt należy zawsze umieszczać w e root witryny (w katalogu najwyższego poziomu hosta) i nosić nazwę pliku robots.txt, na przykład: . Pamiętaj, że w adresie URL pliku robots.txt rozróżniana jest wielkość liter, podobnie jak w przypadku każdego innego adresu URL.
Jeśli nie można znaleźć pliku robots.txt w domyślnej lokalizacji, wyszukiwarki założą, że nie ma żadnych dyrektyw i będą indeksować Twoją witrynę.
Kolejność pierwszeństwa
Należy pamiętać, że wyszukiwarki inaczej obsługują pliki robots.txt. Domyślnie pierwsza pasująca dyrektywa zawsze wygrywa.
Jednak w przypadku Google i Bing wygrywa specyficzność. Na przykład: dyrektywa Allow wygrywa z dyrektywą Disallow, jeśli długość jej znaków jest dłuższa.
Przykład
W przykład ponad wszystkie wyszukiwarki, w tym Google i Bing, nie mają dostępu do katalogu /about/, z wyjątkiem podkatalogu /about/company/.
Przykład
W powyższym przykładzie wszystkie wyszukiwarki oprócz Google i Bing nie mają dostępu do katalogu /about/. Obejmuje to katalog /about/company/.
Google i Bing mają dostęp, ponieważ dyrektywa Allow jest dłuższa niż Disallow.
Tylko jedna grupa dyrektyw na robota
Możesz zdefiniować tylko jedną grupę dyrektyw na wyszukiwarkę. Posiadanie wielu grup dyrektyw dla jednej wyszukiwarki jest mylące.
Podaj jak najwięcej szczegółów
Dyrektywa Disallow uruchamia częściowe dopasowania, ponieważ dobrze. Definiując dyrektywę Disallow, zachowaj jak największą precyzję, aby zapobiec przypadkowemu zablokowaniu dostępu do plików.
Przykład:
Powyższy przykład nie pozwala wyszukiwarkom na dostęp do:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Dyrektywy dla wszystkich robotów, zawierające również dyrektywy dla konkretnego robota
Dla robota obowiązuje tylko jedna grupa dyrektyw. W przypadku, gdy po dyrektywach przeznaczonych dla wszystkich robotów zostaną uwzględnione dyrektywy dotyczące konkretnego robota, pod uwagę zostaną wzięte tylko te konkretne dyrektywy. Aby konkretny robot również przestrzegał dyrektyw dla wszystkich robotów, musisz powtórzyć te dyrektywy dla konkretnego robota.
Spójrzmy na przykład, który to wyjaśni:
Przykład
Jeśli nie chcesz, aby Googlebot miał dostęp do /secret/ i /not-launched-yet/, musisz powtórzyć te dyrektywy dla googlebot w szczególności:
Pamiętaj, że Twój plik robots.txt jest publicznie dostępny. Zablokowanie tam zawartych sekcji witryny może być wykorzystywane jako wektor ataku przez osoby o złych zamiarach.

Plik Robots.txt może być niebezpieczny. Nie tylko mówisz wyszukiwarkom, gdzie nie chcesz ich szukać, ale mówisz ludziom, gdzie ukrywasz swoje brudne sekrety.
Plik Robots.txt dla każdej (pod) domeny
Tylko dyrektywy Robots.txt dotyczą (pod) domeny, na której jest hostowany plik.
Przykłady
jest ważny dla , ale nie lub
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Z tego powodu stworzyliśmy w pliku robots.txt funkcję śledzenia zmian i alertów.
Widzimy to cały czas: pliki robots.txt zmieniają się bez wiedzy o marketingu cyfrowym zespół. Nie bądź tą osobą. Zacznij monitorować plik robots.txt, teraz otrzymuj powiadomienia o zmianach!
Nie używaj noindex w pliku robots.txt
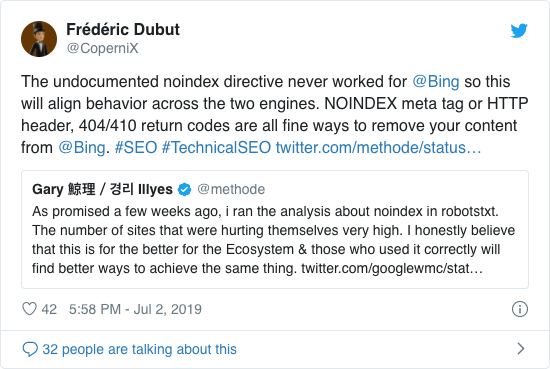
Już od lat Google otwarcie odradza stosowanie nieoficjalnej dyrektywy noindex. Jednak od 1 września 2019 r. Firma Google całkowicie przestała go wspierać.
Nieoficjalna dyrektywa noindex nigdy nie działała w Bing, co potwierdził Frédéric Dubut w tym tweecie:
Najlepszym sposobem zasygnalizowania wyszukiwarkom, że strony nie powinny być indeksowane, jest użycie metatagu robots lub X-Robots-Tag .
Zapobiegaj BOM UTF-8 w pliku robots.txt
BOM to znak kolejności bajtów, niewidoczny znak na początku plik używany do wskazania kodowania Unicode pliku tekstowego.
Chociaż Google twierdzi, że ignoruje opcjonalny znak kolejności bajtów Unicode na początku pliku robots.txt, zalecamy zapobieganie „BOM UTF-8”, ponieważ zauważyliśmy, że powoduje to problemy z interpretacją plik robots.txt przez wyszukiwarki.
Mimo że Google twierdzi, że sobie z tym poradzi, istnieją dwa powody, dla których należy unikać BOM UTF-8:
- Nie Nie chcę, aby Twoje preferencje dotyczące indeksowania do wyszukiwarek były niejednoznaczne.
- Istnieją inne wyszukiwarki, które mogą nie być tak wyrozumiałe, jak twierdzi Google.
Przykłady pliku robots.txt
W tym rozdziale omówimy szeroki zakres przykładów plików robots.txt:
- Zezwalaj wszystkim robotom na dostęp do wszystkiego
- Nie zezwalaj wszystkim robotom na dostęp do wszystkiego
- Wszystkie roboty Google nie mają dostępu
- Wszystkie roboty Google, z wyjątkiem wiadomości Googlebot, nie mają dostępu
- Googlebot i Slurp nie mają dostępu
- Wszystkie roboty nie mają dostępu do dwóch katalogi
- Wszystkie roboty nie mają dostępu do jednego konkretnego pliku
- Googlebot nie ma dostępu do / admin /, a Slurp nie ma dostępu do / private /
- Plik Robots.txt dla WordPress
- Plik Robots.txt dla Magento
Zezwól wszystkim robotom na dostęp do wszystkiego
Jest wiele sposobów aby poinformować wyszukiwarki, że mogą uzyskać dostęp do wszystkich plików:
Lub posiadanie pustego pliku robots.txt lub brak pliku robots.txt.
Zabroń wszystkim robotom dostępu do wszystkiego
Przykład Poniższy plik robots.txt informuje wszystkie wyszukiwarki, aby nie uzyskiwały dostępu do całej witryny:
Pamiętaj, że tylko JEDEN dodatkowy znak może mieć znaczenie.
Żadne roboty Google nie mają dostępu
Należy pamiętać, że odrzucenie Googlebota dotyczy wszystkich Googlebotów. Obejmuje to roboty Google, które wyszukują np. Wiadomości (googlebot-news) i obrazy (googlebot-images).
Wszystko Boty Google, z wyjątkiem wiadomości Googlebot, nie mają dostępu
Googlebot i Slurp nie mają dostępu
Wszystkie roboty nie mają dostępu do dwóch katalogów
Wszystkie roboty nie mają dostępu do jednego konkretnego pliku
Googlebot nie ma dostępu do / admin / i Slurp nie mają dostępu do / private /
Robots.txt plik dla WordPress
Poniższy plik robots.txt jest specjalnie zoptymalizowany pod kątem WordPress, przy założeniu:
- Nie chcesz, aby sekcja administratora była indeksowana.
- Nie chcesz, aby Twoje wewnętrzne strony wyników wyszukiwania były indeksowane.
- Nie chcesz, aby Twój tag i strony autorów były indeksowane.
- Nie nie chcesz, aby strona 404 została zindeksowana.
Pamiętaj, że ten plik robots.txt będzie działał w większości przypadków, ale zawsze należy go dostosować i przetestować, aby upewnić się, że dotyczy dokładna sytuacja.
Plik Robots.txt dla Magento
Poniższy plik robots.txt jest specjalnie zoptymalizowany pod kątem Magento i będzie zawierał wewnętrzne wyniki wyszukiwania, strony logowania, identyfikatory sesji i filtrowane wyniki zestawy zawierające price, color, material i size kryteria niedostępne dla robotów indeksujących.
Pamiętaj, że ten plik robots.txt będzie działał w większości sklepów Magento, ale Ty należy go zawsze dostosować i przetestować, aby upewnić się, że pasuje do konkretnej sytuacji.
Zawsze starałbym się blokować wewnętrzne wyniki wyszukiwania w pliku robots.txt w dowolnej witrynie, ponieważ tego typu adresy URL wyszukiwania są nieskończone i nie mają końca. Googlebot może wpaść w pułapkę robota.
Jakie są ograniczenia pliku robots.txt?
Plik Robots.txt zawiera dyrektywy
Mimo że plik robots.txt jest dobrze szanowany przez wyszukiwanie wyszukiwarek, to wciąż dyrektywa, a nie nakaz.
Strony wciąż pojawiające się w wynikach wyszukiwania
Strony niedostępne dla wyszukiwarek ze względu na roboty.txt, ale mają do nich linki, mogą nadal pojawiać się w wynikach wyszukiwania, jeśli prowadzą do nich linki z przeszukiwanej strony. Przykład, jak to wygląda:

Możliwe jest usunięcie tych adresów URL z Google za pomocą narzędzia do usuwania adresów URL w Google Search Console. Pamiętaj, że te adresy URL będą tylko tymczasowo „ukryte”. Aby pozostawały poza stronami wyników wyszukiwania Google, musisz co 180 dni przesyłać żądanie ukrycia adresów URL.

Użyj pliku robots.txt, aby zablokować niepożądane i prawdopodobnie szkodliwe linki zwrotne podmiotów stowarzyszonych. nie używaj pliku robots.txt, aby zapobiec indeksowaniu treści przez wyszukiwarki, ponieważ nieuchronnie zakończy się to niepowodzeniem. Zamiast tego zastosuj dyrektywę robotów noindex, gdy jest to konieczne.
Plik Robots.txt jest przechowywany w pamięci podręcznej do 24 godzin
Firma Google wskazała, że plik robots Plik .txt jest zwykle przechowywany w pamięci podręcznej przez maksymalnie 24 godziny. Należy wziąć to pod uwagę podczas wprowadzania zmian w pliku robots.txt.
Nie jest jasne, jak inne wyszukiwarki radzą sobie z buforowaniem pliku robots.txt , ale generalnie najlepiej unikać buforowania pliku robots.txt w formacie av oid pobieranie zmian trwa dłużej niż to konieczne.
Rozmiar pliku Robots.txt
W przypadku plików robots.txt Google obecnie obsługuje limit rozmiaru pliku wynoszący 500 kibibajtów (512 kilobajtów). Wszelkie treści po tym maksymalnym rozmiarze mogą zostać zignorowane.
Nie jest jasne, czy inne wyszukiwarki mają maksymalny rozmiar pliku dla plików robots.txt.
Często zadawane pytania dotyczące pliku robots.txt
🤖 Jak wygląda przykład pliku robots.txt?
Oto przykład zawartości pliku robots.txt: User-agent: * Disallow:. To powie wszystkim robotom, że mają dostęp do wszystkiego.
⛔ Co robi Disallow all w pliku robots.txt?
Po ustawieniu w pliku robots.txt opcji „Disallow all” zasadniczo mówi wszystkim robotom, aby się trzymali. Żadne roboty, w tym Google, nie mają dostępu do Twojej witryny. Oznacza to, że nie będą w stanie pobierać, indeksować i oceniać Twojej witryny. Doprowadzi to do ogromnego spadku ruchu organicznego.
✅ Co robi Allow all w pliku robots.txt?
Po ustawieniu w pliku robots.txt opcji „Zezwalaj na wszystko” informuje się każdego robota, że może uzyskać dostęp do każdego adresu URL w witrynie. Po prostu nie ma reguł zaręczyn. Pamiętaj, że jest to odpowiednik pustego pliku robots.txt lub braku pliku robots.txt.
🤔 Jak ważny jest plik robots.txt dla SEO?
W Ogólnie plik robots.txt jest bardzo ważny dla celów SEO. W przypadku większych witryn plik robots.txt jest niezbędny, ponieważ zapewnia wyszukiwarkom bardzo jasne instrukcje dotyczące treści, do których nie należy uzyskiwać dostępu.