Ein Roboter Die TXT-Datei enthält Anweisungen für Suchmaschinen. Sie können es verwenden, um zu verhindern, dass Suchmaschinen bestimmte Teile Ihrer Website crawlen, und um Suchmaschinen hilfreiche Tipps zu geben, wie sie Ihre Website am besten crawlen können. Die robots.txt-Datei spielt eine große Rolle bei der Suchmaschinenoptimierung.
Beachten Sie bei der Implementierung von robots.txt die folgenden Best Practices:
- Seien Sie vorsichtig, wenn Sie Änderungen an Ihrer vornehmen robots.txt: Diese Datei kann dazu führen, dass große Teile Ihrer Website für Suchmaschinen nicht mehr zugänglich sind.
- Die robots.txt-Datei sollte sich im Stammverzeichnis Ihrer Website befinden (z. B. oder
https). - Verschiedene Suchmaschinen interpretieren Direktiven unterschiedlich. Standardmäßig gewinnt immer die erste übereinstimmende Direktive. Bei Google und Bing gewinnt jedoch die Spezifität.
- Vermeiden Sie die Verwendung der Crawl-Delay-Direktive für Suchmaschinen so oft wie möglich.
Was ist ein robots.txt-Datei?
Eine robots.txt-Datei informiert Suchmaschinen über die Einsatzregeln Ihrer Website. Ein großer Teil der Suchmaschinenoptimierung besteht darin, die richtigen Signale an Suchmaschinen zu senden, und die robots.txt ist eine der Möglichkeiten, Suchmaschinen Ihre Crawling-Einstellungen mitzuteilen.
Im Jahr 2019 haben wir ziemlich viel gesehen Einige Entwicklungen rund um den robots.txt-Standard: Google schlug eine Erweiterung des Robots Exclusion Protocol vor und stellte seinen robots.txt-Parser als Open-Source-Version zur Verfügung.
TL; DR
- Googles Roboter Der .txt-Interpreter ist sehr flexibel und überraschend verzeihend.
- Bei Verwechslungsanweisungen irrt Google auf der sicheren Seite und geht davon aus, dass Abschnitte eher eingeschränkt als uneingeschränkt sein sollten.
Suchmaschinen überprüfen regelmäßig die robots.txt-Datei einer Website, um festzustellen, ob Anweisungen zum Crawlen der Website vorhanden sind. Wir nennen diese Anweisungen Direktiven.
Wenn keine robots.txt-Datei vorhanden ist oder wenn keine anwendbaren Direktiven vorhanden sind, crawlen Suchmaschinen die gesamte Website.
Obwohl alle großen Suchmaschinen dies respektieren In der robots.txt-Datei ignorieren Suchmaschinen möglicherweise (Teile) Ihrer robots.txt-Datei. Während Direktiven in der robots.txt-Datei ein starkes Signal für Suchmaschinen sind, ist es wichtig, sich daran zu erinnern, dass die robots.txt-Datei eine Reihe optionaler Direktiven für Suchmaschinen und kein Mandat ist.

Die robots.txt ist die sensibelste Datei im SEO-Universum. Ein einzelnes Zeichen kann eine ganze Site beschädigen.
Terminologie für die robots.txt-Datei
Die robots.txt-Datei ist die Implementierung des Robots-Ausschlussstandards oder wird auch aufgerufen das Roboter-Ausschlussprotokoll.
Warum sollten Sie sich für robots.txt interessieren?
Die robots.txt spielt aus SEO-Sicht eine wesentliche Rolle. Hier erfahren Suchmaschinen, wie sie Ihre Website am besten crawlen können.
Mit der Datei robots.txt können Sie verhindern, dass Suchmaschinen auf bestimmte Teile Ihrer Website zugreifen, doppelte Inhalte verhindern und Suchmaschinen hilfreiche Tipps dazu geben Sie können Ihre Website effizienter crawlen.
Seien Sie jedoch vorsichtig, wenn Sie Änderungen an Ihrer robots.txt vornehmen: Diese Datei kann dazu führen, dass große Teile Ihrer Website für Suchmaschinen nicht mehr zugänglich sind.

Robots.txt wird häufig zu häufig verwendet, um doppelte Inhalte zu reduzieren Töte interne Verknüpfungen, sei also sehr vorsichtig damit. Mein Rat ist, es immer nur für Dateien oder Seiten zu verwenden, die Suchmaschinen niemals sehen sollten oder die das Crawlen erheblich beeinträchtigen können, wenn sie zugelassen werden. Allgemeine Beispiele: Anmeldebereiche, die viele verschiedene URLs generieren, Testbereiche oder in denen mehrere facettierte Navigation vorhanden sein kann. Und stellen Sie sicher, dass Sie Ihre robots.txt-Datei auf Probleme oder Änderungen überwachen.

Die meisten Probleme, die ich mit robots.txt-Dateien sehe, lassen sich in drei Bereiche unterteilen:
- Der Missbrauch von Platzhaltern. Es ist ziemlich üblich, dass Teile der Website blockiert werden, die blockiert werden sollten. Wenn Sie nicht vorsichtig sind, können Direktiven manchmal auch miteinander in Konflikt stehen.
- Jemand, z. B. ein Entwickler, hat aus heiterem Himmel eine Änderung vorgenommen (häufig beim Pushen von neuem Code) und sich versehentlich geändert die robots.txt ohne dein Wissen.
- Die Aufnahme von Anweisungen, die nicht in eine robots.txt-Datei gehören. Robots.txt ist Webstandard und etwas eingeschränkt. Ich sehe oft Entwickler, die Richtlinien erstellen, die einfach nicht funktionieren (zumindest für die Massenmehrheit der Crawler). Manchmal ist das harmlos, manchmal nicht so sehr.
Beispiel
Schauen wir uns ein Beispiel an, um dies zu veranschaulichen:
Sie Sie betreiben eine E-Commerce-Website und Besucher können mithilfe eines Filters schnell nach Ihren Produkten suchen. Dieser Filter generiert Seiten, die im Grunde den gleichen Inhalt wie andere Seiten anzeigen. Dies funktioniert hervorragend für Benutzer, verwirrt jedoch Suchmaschinen, da doppelte Inhalte erstellt werden.
Sie möchten nicht, dass Suchmaschinen diese gefilterten Seiten indizieren und ihre wertvolle Zeit mit gefiltertem Inhalt für diese URLs verschwenden. Daher sollten Sie Disallow -Regeln einrichten, damit Suchmaschinen nicht auf diese gefilterten Produktseiten zugreifen.
Das Verhindern doppelter Inhalte kann auch über die kanonische URL oder erfolgen Das Meta-Robots-Tag behebt jedoch nicht, dass Suchmaschinen nur wichtige Seiten crawlen.
Die Verwendung einer kanonischen URL oder eines Meta-Robots-Tags verhindert nicht, dass Suchmaschinen diese Seiten crawlen. Es wird nur verhindert, dass Suchmaschinen diese Seiten in den Suchergebnissen anzeigen. Da Suchmaschinen nur eine begrenzte Zeit zum Crawlen einer Website haben, sollte diese Zeit für Seiten aufgewendet werden, die in Suchmaschinen angezeigt werden sollen.
Eine falsch eingerichtete robots.txt-Datei kann Ihre SEO-Leistung beeinträchtigen. Überprüfen Sie sofort, ob dies für Ihre Website der Fall ist!

Es ist ein sehr einfaches Tool, aber eine robots.txt-Datei kann viele Probleme verursachen, wenn sie nicht richtig konfiguriert ist, insbesondere für größere Websites. Es ist sehr einfach, Fehler zu machen, z. B. das Blockieren einer gesamten Site nach der Einführung eines neuen Designs oder CMS oder das Blockieren von Abschnitten einer Site, die privat sein sollten. Bei größeren Websites ist es sehr wichtig, sicherzustellen, dass Google effizient crawlt, und eine gut strukturierte robots.txt-Datei ist ein wesentliches Werkzeug in diesem Prozess.
Sie müssen sich Zeit nehmen, um zu verstehen, welche Bereiche Ihrer Website am besten ferngehalten werden von Google, damit sie so viel Ressourcen wie möglich für das Crawlen der Seiten verwenden, die Ihnen wirklich wichtig sind.
Wie sieht eine robots.txt-Datei aus?
Ein Beispiel dafür, wie eine einfache robots.txt-Datei für eine WordPress-Website aussehen kann aussehen wie folgt:
Lassen Sie uns die Anatomie einer robots.txt-Datei anhand des obigen Beispiels erläutern:
- Benutzeragent: Die
user-agentgibt an, für welche Suche Engines Die folgenden Anweisungen sind gemeint. -
*: Dies zeigt an, dass die Anweisungen für alle Suchmaschinen bestimmt sind. -
Disallow: Dies ist eine Anweisung, die angibt, auf welchen Inhalt dieuser-agentnicht zugreifen kann. -
/wp-admin/: Dies ist diepath, auf die für dieuser-agentnicht zugegriffen werden kann.
Zusammenfassend: Diese robots.txt-Datei weist alle Suchmaschinen an, sich aus dem Verzeichnis /wp-admin/ herauszuhalten.
Analysieren wir die verschiedenen Komponenten von robots.txt-Dateien im Detail:
- Benutzeragent
- Nicht zulassen
- Zulassen
- Sitemap
- Crawling-Verzögerung
Benutzeragent in robots.txt
Jede Suchmaschine sollte sich mit einer user-agent. Die Roboter von Google identifizieren sich beispielsweise als Googlebot, die Roboter von Yahoo als Slurp und der Roboter von Bing als BingBot usw.
Der Datensatz user-agent definiert den Beginn einer Gruppe von Anweisungen. Alle Anweisungen zwischen dem ersten user-agent und dem nächsten user-agent -Datensatz werden als Anweisungen für den ersten user-agent.
Anweisungen können für bestimmte Benutzeragenten gelten, sie können jedoch auch für alle Benutzeragenten gelten. In diesem Fall wird ein Platzhalter verwendet: User-agent: *.
Direktive in robots.txt nicht zulassen
Sie können Suchmaschinen anweisen, nicht darauf zuzugreifen bestimmte Dateien, Seiten oder Abschnitte Ihrer Website. Dies erfolgt mit der Anweisung Disallow. Auf die Anweisung Disallow folgt die Anweisung path, auf die nicht zugegriffen werden soll. Wenn kein path definiert ist, wird die Direktive ignoriert.
Beispiel
In diesem Beispiel werden alle Suchmaschinen angewiesen, nicht auf das Verzeichnis /wp-admin/ zuzugreifen.
Direktive in robots.txt
Die Anweisung Allow wird verwendet, um einer Anweisung Disallow entgegenzuwirken. Die Anweisung Allow wird von Google und Bing unterstützt. Wenn Sie die Anweisungen Allow und Disallow gemeinsam verwenden, können Sie Suchmaschinen mitteilen, dass sie auf eine bestimmte Datei oder Seite in einem Verzeichnis zugreifen können, das ansonsten nicht zulässig ist. Auf die Anweisung Allow folgt die Anweisung path, auf die zugegriffen werden kann. Wenn kein path definiert ist, wird die Direktive ignoriert.
Beispiel
Im obigen Beispiel dürfen nicht alle Suchmaschinen auf die Verzeichnis mit Ausnahme der Datei /media/terms-and-conditions.pdf.
Wichtig: Bei Verwendung von Allow und Disallow Anweisungen zusammen, stellen Sie sicher, dass Sie keine Platzhalter verwenden, da dies zu widersprüchlichen Anweisungen führen kann.
Beispiel für widersprüchliche Anweisungen
Suchmaschinen wissen nicht, was sie mit der URL . Es ist ihnen unklar, ob sie Zugang haben. Wenn Direktiven für Google nicht klar sind, verwenden sie die am wenigsten restriktive Direktive. In diesem Fall bedeutet dies, dass sie tatsächlich auf
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt ist eine der Funktionen, die ich am häufigsten falsch implementiert sehe, sodass sie nicht blockiert, was sie blockieren wollten, oder mehr blockiert als erwartet und sich negativ auf ihre Website auswirkt. Robots.txt ist ein sehr leistungsfähiges Tool, aber zu oft ist es falsch eingerichtet.
Platzhalter verwenden *
Der Platzhalter kann nicht nur zum Definieren des user-agent verwendet werden, sondern auch URLs abgleichen. Der Platzhalter wird von Google, Bing, Yahoo und Ask unterstützt.
Beispiel
Im obigen Beispiel haben alle Suchmaschinen keinen Zugriff auf URLs, die ein Fragezeichen enthalten (?).

Entwickler oder Websitebesitzer scheinen oft zu glauben, dass sie alle Arten von regulären Ausdrücken in einer robots.txt-Datei verwenden können, während nur eine sehr begrenzte Menge an Musterabgleich tatsächlich gültig ist – zum Beispiel Platzhalter (
*). Von Zeit zu Zeit scheint es eine Verwechslung zwischen .htaccess-Dateien und robots.txt-Dateien zu geben.
Verwenden des URL-Endes $
Um das Ende einer URL anzugeben, können Sie das Dollarzeichen ($) am Ende von path.
Beispiel
Im obigen Beispiel dürfen Suchmaschinen nicht auf alle URLs zugreifen, die mit .php enden . URLs mit Parametern, z. wird nicht zugelassen, da die URL nicht nach .php endet.
Sitemap zu Robotern hinzufügen. txt
Obwohl die robots.txt-Datei erfunden wurde, um Suchmaschinen mitzuteilen, welche Seiten nicht gecrawlt werden sollen, kann die robots.txt-Datei auch verwendet werden, um Suchmaschinen auf die XML-Sitemap zu verweisen. Dies wird von Google, Bing, Yahoo und Ask unterstützt.
Die XML-Sitemap sollte als absolute URL referenziert werden. Die URL muss sich nicht auf demselben Host wie die robots.txt-Datei befinden.
Das Verweisen auf die XML-Sitemap in der robots.txt-Datei ist eine der bewährten Methoden, die Sie immer empfehlen sollten Möglicherweise haben Sie Ihre XML-Sitemap bereits in der Google Search Console oder in den Bing Webmaster-Tools eingereicht. Denken Sie daran, dass es mehr Suchmaschinen gibt.
Bitte beachten Sie, dass in einer robots.txt-Datei auf mehrere XML-Sitemaps verwiesen werden kann.
Beispiele
Mehrere In einer robots.txt-Datei definierte XML-Sitemaps:
Eine einzelne XML-Sitemap, die in einem Roboter definiert ist.txt-Datei:
Das obige Beispiel weist alle Suchmaschinen an, nicht auf das Verzeichnis /wp-admin/ zuzugreifen. Die XML-Sitemap finden Sie unter
Comments are preceded by a # und können entweder am Anfang einer Zeile oder nach einer Anweisung in derselben Zeile stehen. Alles nach # wird ignoriert. Diese Kommentare sind nur für Menschen bestimmt.
Beispiel 1
Beispiel 2
Die obigen Beispiele vermitteln dieselbe Nachricht.
Crawling-Verzögerung in robots.txt
Die Crawl-delay ist eine inoffizielle Anweisung, mit der verhindert wird, dass Server mit zu vielen Anforderungen überlastet werden. Wenn Suchmaschinen einen Server überlasten können, ist das Hinzufügen von Crawl-delay zu Ihrer robots.txt-Datei nur eine vorübergehende Korrektur. Tatsache ist, dass Ihre Website in einer schlechten Hosting-Umgebung ausgeführt wird und / oder Ihre Website falsch konfiguriert ist. Sie sollten dies so schnell wie möglich beheben.
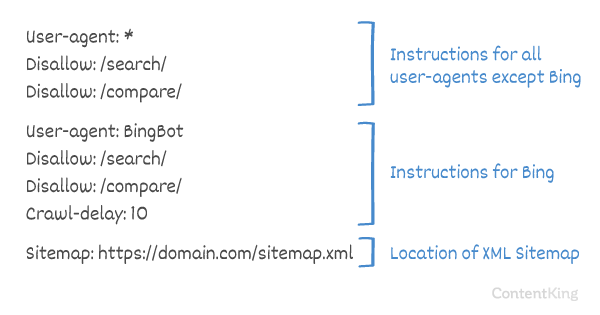
Die Art und Weise, wie Suchmaschinen mit Crawl-delay umgehen, ist unterschiedlich. Im Folgenden wird erläutert, wie große Suchmaschinen damit umgehen.
Crawling-Verzögerung und Google
Der Google-Crawler Googlebot unterstützt das Crawl-delay Direktive, also kümmern Sie sich nicht um das Definieren einer Google-Crawling-Verzögerung.
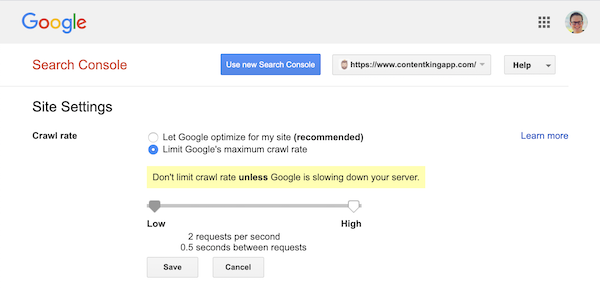
Google unterstützt jedoch das Definieren einer Crawling-Rate (oder „Anforderungsrate“, wenn Sie so wollen ) in der Google Search Console.
- Melden Sie sich bei der alten Google Search Console an.
- Wählen Sie die gewünschte Website aus Sie möchten die Durchforstungsrate für definieren.
- Sie können nur eine Einstellung anpassen:
Crawl rate, mit einem Schieberegler, mit dem Sie die bevorzugte Durchforstungsrate festlegen können. Standardmäßig Die Crawling-Rate ist auf „Google für meine Website optimieren lassen (empfohlen)“ festgelegt.
So sieht es in der Google Search Console aus:
Crawling-Verzögerung und Bing, Yahoo und Yandex
Bing, Yahoo und Yandex Alle unterstützen die Crawl-delay Anweisung zum Drosseln des Crawls einer Website. Ihre Interpretation der Crawling-Verzögerung unterscheidet sich jedoch geringfügig. Überprüfen Sie daher unbedingt die Dokumentation:
- Bing und Yahoo
- Yandex
Die Direktive Crawl-delay sollte direkt nach der Direktive Disallow oder Allow platziert werden.
Beispiel:
Crawl-Verzögerung und Baidu
Baidu unterstützt die Anweisung crawl-delay nicht, es ist jedoch möglich, ein Konto bei den Baidu Webmaster-Tools zu registrieren Sie können die Durchforstungshäufigkeit ähnlich wie in der Google Search Console steuern.
Wann wird eine robots.txt-Datei verwendet?
Wir empfehlen, immer eine robots.txt-Datei zu verwenden. Es schadet absolut nichts, eine zu haben, und es ist ein großartiger Ort, um Suchmaschinen Anweisungen zu geben, wie sie Ihre Website am besten crawlen können.

Die robots.txt kann hilfreich sein, um zu verhindern, dass bestimmte Bereiche oder Dokumente auf Ihrer Site gecrawlt und indiziert werden. Beispiele sind beispielsweise die Staging-Site oder PDFs. Planen Sie sorgfältig, was von Suchmaschinen indiziert werden muss, und beachten Sie, dass Inhalte, auf die über robots.txt nicht zugegriffen werden kann, von Suchmaschinen-Crawlern möglicherweise weiterhin gefunden werden, wenn sie mit anderen Bereichen der Website verknüpft sind.
Best Practices für Robots.txt
Die Best Practices für robots.txt sind wie folgt kategorisiert:
- Speicherort und Dateiname
- Rangfolge
- Nur eine Gruppe von Anweisungen pro Roboter
- Seien Sie so spezifisch wie möglich.
- Anweisungen für alle Roboter, einschließlich Anweisungen für einen bestimmten Roboter.
- Robots.txt-Datei für jede (Unter-) Domäne.
- Widersprüchliche Richtlinien: robots.txt vs. Google Search Console
- Überwachen Sie Ihre robots.txt-Datei
- Verwenden Sie keinen noindex in Ihrer robots.txt
- UTF-8-Stückliste in der robots.txt-Datei verhindern
Speicherort und Dateiname
Die robots.txt-Datei sollte immer in th abgelegt werden e root einer Website (im obersten Verzeichnis des Hosts) und tragen Sie den Dateinamen robots.txt, zum Beispiel: . Beachten Sie, dass bei der URL für die robots.txt-Datei wie bei jeder anderen URL zwischen Groß- und Kleinschreibung unterschieden wird.
Wenn die Datei robots.txt nicht am Standardspeicherort gefunden werden kann, gehen Suchmaschinen davon aus, dass keine Anweisungen vorhanden sind, und kriechen auf Ihrer Website davon.
Rangfolge
Es ist wichtig zu beachten, dass Suchmaschinen robots.txt-Dateien unterschiedlich behandeln. Standardmäßig gewinnt immer die erste übereinstimmende Direktive.
Bei Google und Bing gewinnt jedoch die Spezifität. Beispiel: Eine Allow Direktive gewinnt eine Disallow Direktive, wenn ihre Zeichenlänge länger ist.
Beispiel
In der Beispiel Vor allem Suchmaschinen, einschließlich Google und Bing, dürfen nicht auf das Verzeichnis /about/ zugreifen, mit Ausnahme des Unterverzeichnisses /about/company/.
Beispiel
Im obigen Beispiel haben alle Suchmaschinen außer Google und Bing keinen Zugriff auf das Verzeichnis /about/. Dazu gehört das Verzeichnis /about/company/.
Google und Bing haben Zugriff, da die Anweisung Allow länger ist als die Disallow Direktive.
Nur eine Gruppe von Direktiven pro Roboter
Sie können nur eine Gruppe von Direktiven pro Suchmaschine definieren. Wenn mehrere Gruppen von Direktiven für eine Suchmaschine vorhanden sind, werden sie verwirrt.
Seien Sie so genau wie möglich.
Die Direktive Disallow wird bei Teilübereinstimmungen als ausgelöst Gut. Seien Sie so genau wie möglich, wenn Sie die Anweisung Disallow definieren, um zu verhindern, dass der Zugriff auf Dateien unbeabsichtigt nicht zugelassen wird.
Beispiel:
Das obige Beispiel erlaubt Suchmaschinen keinen Zugriff auf:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Anweisungen für alle Roboter, einschließlich Anweisungen für einen bestimmten Roboter
Für einen Roboter Es ist nur eine Gruppe von Richtlinien gültig. Falls Anweisungen, die für alle Roboter bestimmt sind, mit Anweisungen für einen bestimmten Roboter befolgt werden, werden nur diese spezifischen Anweisungen berücksichtigt. Damit der bestimmte Roboter auch den Anweisungen für alle Roboter folgt, müssen Sie diese Anweisungen für den bestimmten Roboter wiederholen.
Schauen wir uns ein Beispiel an, das dies verdeutlicht:
Beispiel
Wenn Sie nicht möchten, dass Googlebot auf /secret/ und /not-launched-yet/ zugreift, müssen Sie diese Anweisungen für googlebot speziell:
Bitte beachten Sie, dass Ihre robots.txt-Datei öffentlich verfügbar ist. Das Deaktivieren von Website-Abschnitten kann von Personen mit böswilliger Absicht als Angriffsvektor verwendet werden.

Robots.txt kann gefährlich sein. Sie sagen Suchmaschinen nicht nur, wo sie nicht aussehen sollen, sondern auch, wo Sie Ihre schmutzigen Geheimnisse verbergen.
Robots.txt-Datei nur für jede (Unter-) Domain
Robots.txt-Direktiven gelten für die (Unter-) Domäne, in der die Datei gehostet wird.
Beispiele
gilt für , jedoch nicht für oder
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Aus diesem Grund haben wir robots.txt-Änderungsverfolgung und -warnung erstellt.
Wir sehen es ständig: robots.txt-Dateien ändern sich ohne Kenntnis des digitalen Marketings Mannschaft. Sei nicht diese Person. Beginnen Sie mit der Überwachung Ihrer robots.txt-Datei und erhalten Sie jetzt Benachrichtigungen, wenn sie sich ändern!
Verwenden Sie keinen noindex in Ihrer robots.txt
Google hat bereits seit Jahren offen davon abgeraten, die inoffizielle No-Index-Richtlinie zu verwenden. Ab dem 1. September 2019 hat Google die Unterstützung jedoch vollständig eingestellt.
Die inoffizielle No-Index-Richtlinie hat in Bing nie funktioniert, wie Frédéric Dubut in diesem Tweet bestätigt hat:
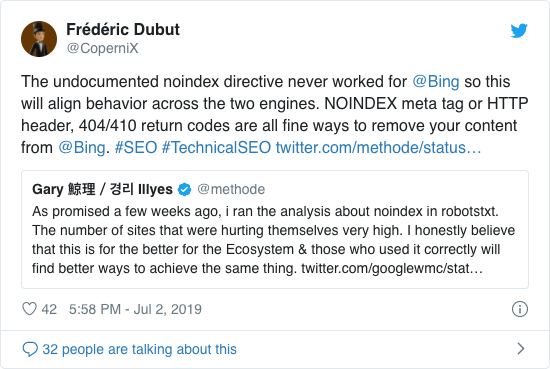
Der beste Weg, um Suchmaschinen zu signalisieren, dass Seiten nicht indiziert werden sollten, ist die Verwendung des Meta-Robots-Tags oder des X-Robots-Tags
UTF-8-Stückliste in der robots.txt-Datei verhindern
Stückliste steht für Byte Order Mark, ein unsichtbares Zeichen am Anfang von a Datei, die zur Angabe der Unicode-Codierung einer Textdatei verwendet wird.
Während Google angibt, die optionale Unicode-Bytereihenfolge am Anfang der robots.txt-Datei zu ignorieren, empfehlen wir, die „UTF-8-Stückliste“ zu verhindern, da dies zu Problemen bei der Interpretation von führt die robots.txt-Datei von Suchmaschinen.
Obwohl Google angibt, dass sie damit umgehen können, gibt es zwei Gründe, um die UTF-8-Stückliste zu verhindern:
- Sie ziehen an Ich möchte nicht, dass Ihre Präferenzen beim Crawlen zu Suchmaschinen nicht eindeutig sind.
- Es gibt andere Suchmaschinen, die möglicherweise nicht so verzeihend sind, wie Google behauptet.
Beispiele für Robots.txt
In diesem Kapitel werden wir eine Vielzahl von Beispielen für robots.txt-Dateien behandeln:
- Ermöglichen Sie allen Robotern den Zugriff auf alles
- Allen Robotern den Zugriff auf alles verbieten
- Alle Google-Bots haben keinen Zugriff
- Alle Google-Bots außer Googlebot-Nachrichten haben keinen Zugriff
- Googlebot und Slurp haben keinen Zugriff
- Alle Roboter haben keinen Zugriff auf zwei Verzeichnisse
- Alle Roboter haben keinen Zugriff auf eine bestimmte Datei
- Googlebot hat keinen Zugriff auf / admin / und Slurp hat keinen Zugriff auf / private /
- Robots.txt-Datei für WordPress
- Robots.txt-Datei für Magento
Ermöglichen Sie allen Robotern den Zugriff auf alles
Es gibt mehrere Möglichkeiten Um Suchmaschinen mitzuteilen, dass sie auf alle Dateien zugreifen können:
Oder eine leere robots.txt-Datei oder überhaupt keine robots.txt.
Allen Robotern den Zugriff auf alles verbieten
Das Beispiel Die unten stehende robots.txt weist alle Suchmaschinen an, nicht auf die gesamte Site zuzugreifen:
Bitte beachten Sie, dass nur EIN zusätzliches Zeichen den Unterschied ausmachen kann.
Alle Google-Bots haben keinen Zugriff
Bitte beachten Sie, dass dies für alle Googlebots gilt, wenn Googlebot nicht zugelassen wird. Dazu gehören Google-Roboter, die beispielsweise nach Nachrichten (googlebot-news) und Bildern (googlebot-images) suchen.
Alle Google-Bots haben außer für Googlebot-Nachrichten keinen Zugriff.
Googlebot und Slurp haben keinen Zugriff
Alle Roboter haben keinen Zugriff auf zwei Verzeichnisse
Alle Roboter haben keinen Zugriff auf eine bestimmte Datei
Googlebot hat keinen Zugriff auf / admin / und Slurp haben keinen Zugriff auf / private /
Robots.txt Datei für WordPress
Die folgende robots.txt-Datei ist speziell für WordPress optimiert, vorausgesetzt:
- Sie möchten nicht, dass Ihr Admin-Bereich gecrawlt wird.
- Sie möchten nicht, dass Ihre internen Suchergebnisseiten gecrawlt werden.
- Sie möchten nicht, dass Ihre Tag- und Autorenseiten gecrawlt werden.
- Sie tun es nicht. Sie möchten nicht, dass Ihre 404-Seite gecrawlt wird.
Bitte beachten Sie, dass diese robots.txt-Datei in den meisten Fällen funktioniert. Sie sollten sie jedoch immer anpassen und testen, um sicherzustellen, dass sie für Ihre Seite gilt genaue Situation.
Robots.txt-Datei für Magento
Die folgende robots.txt-Datei ist speziell für Magento optimiert und erstellt interne Suchergebnisse, Anmeldeseiten, Sitzungskennungen und gefilterte Ergebnisse Sätze, die price, color, material und size Kriterien, auf die Crawler nicht zugreifen können.
Bitte beachten Sie, dass diese robots.txt-Datei für die meisten Magento-Stores funktioniert, außer für Sie sollte es immer anpassen und testen, um sicherzustellen, dass es genau Ihrer Situation entspricht.
Ich würde immer noch versuchen, interne Suchergebnisse in robots.txt auf jeder Site zu blockieren, da diese Arten von Such-URLs unendliche und endlose Leerzeichen sind. Es gibt viel Potenzial für Googlebot, in eine Crawlerfalle zu geraten.
Was sind die Einschränkungen der robots.txt-Datei?
Die Robots.txt-Datei enthält Anweisungen
Auch wenn die robots.txt-Datei bei der Suche gut berücksichtigt wird Suchmaschinen, es ist immer noch eine Richtlinie und kein Mandat.
Seiten, die immer noch in den Suchergebnissen angezeigt werden
Seiten, auf die Suchmaschinen aufgrund der Roboter nicht zugreifen können.txt, aber Links zu ihnen können weiterhin in den Suchergebnissen angezeigt werden, wenn sie von einer gecrawlten Seite verlinkt sind. Ein Beispiel dafür, wie dies aussieht:

Es ist möglich, diese URLs mit dem URL-Entfernungstool der Google Search Console von Google zu entfernen. Bitte beachten Sie, dass diese URLs nur vorübergehend „ausgeblendet“ werden. Damit sie nicht auf den Ergebnisseiten von Google angezeigt werden, müssen Sie alle 180 Tage eine Anfrage zum Ausblenden der URLs senden.

Verwenden Sie robots.txt, um unerwünschte und wahrscheinlich schädliche Partner-Backlinks auszublenden Verwenden Sie robots.txt nicht, um zu verhindern, dass Inhalte von Suchmaschinen indiziert werden, da dies unweigerlich fehlschlägt. Wenden Sie stattdessen bei Bedarf die Roboterrichtlinie noindex an.
Die Robots.txt-Datei wird bis zu 24 Stunden zwischengespeichert.
Google hat angegeben, dass ein Roboter Die TXT-Datei wird im Allgemeinen bis zu 24 Stunden zwischengespeichert. Es ist wichtig, dies zu berücksichtigen, wenn Sie Änderungen an Ihrer robots.txt-Datei vornehmen.
Es ist unklar, wie andere Suchmaschinen mit dem Caching von robots.txt umgehen Im Allgemeinen ist es jedoch am besten, das Zwischenspeichern Ihrer robots.txt-Datei in av zu vermeiden oid-Suchmaschinen brauchen länger als nötig, um Änderungen zu erfassen.
Robots.txt-Dateigröße
Für robots.txt-Dateien unterstützt Google derzeit eine Dateigrößenbeschränkung von 500 Kibibyte (512 Kilobyte). Inhalte nach dieser maximalen Dateigröße werden möglicherweise ignoriert.
Es ist unklar, ob andere Suchmaschinen eine maximale Dateigröße für robots.txt-Dateien haben.
Häufig gestellte Fragen zu robots.txt
🤖 Wie sieht ein robots.txt-Beispiel aus?
Hier ist ein Beispiel für den Inhalt einer robots.txt: User-Agent: * Disallow :. Dies teilt allen Crawlern mit, dass sie auf alles zugreifen können.
⛔ Was macht Disallow all in robots.txt?
Wenn Sie eine robots.txt auf „All Allowow“ setzen, sind Sie Im Wesentlichen werden alle Crawler angewiesen, sich fernzuhalten. Kein Crawler, einschließlich Google, darf auf Ihre Website zugreifen. Dies bedeutet, dass er Ihre Website nicht crawlen, indizieren und bewerten kann. Dies führt zu einem massiven Rückgang des organischen Datenverkehrs.
✅ Was macht Allow in robots.txt?
Wenn Sie eine robots.txt auf „Allow all“ setzen, teilen Sie jedem Crawler mit, dass er auf jede URL auf der Site zugreifen kann. Es gibt einfach keine Regeln für das Engagement. Bitte beachten Sie, dass dies einer leeren robots.txt oder gar keiner robots.txt entspricht.
🤔 Wie wichtig ist die robots.txt für SEO?
In Im Allgemeinen ist die Datei robots.txt für SEO-Zwecke sehr wichtig. Für größere Websites ist die robots.txt wichtig, um Suchmaschinen sehr klare Anweisungen zu geben, auf welche Inhalte nicht zugegriffen werden soll.