A-robotar .txt-filen innehåller riktlinjer för sökmotorer. Du kan använda den för att förhindra sökmotorer från att genomsöka specifika delar av din webbplats och för att ge sökmotorer användbara tips om hur de bäst kan genomsöka din webbplats. Robots.txt-filen spelar en stor roll i SEO.
Tänk på följande bästa metoder när du implementerar robots.txt:
- Var försiktig när du gör ändringar i din robots.txt: den här filen har potential att göra stora delar av din webbplats otillgängliga för sökmotorer.
- Robots.txt-filen ska finnas i roten på din webbplats (t.ex.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpellerhttps). - Olika sökmotorer tolkar direktiv på olika sätt. Som standard vinner alltid det första matchande direktivet. Men med Google och Bing vinner specificiteten.
- Undvik att använda genomsökningsfördröjningsdirektivet för sökmotorer så mycket som möjligt.
Vad är en robots.txt-fil?
En robots.txt-fil berättar för sökmotorer vad din webbplats regler för engagemang är. En stor del av att göra SEO handlar om att skicka rätt signaler till sökmotorer och robots.txt är ett av sätten att kommunicera dina genomsökningsinställningar till sökmotorer.
Under 2019 har vi sett ganska viss utveckling kring robots.txt-standarden: Google föreslog en tillägg till Robots Exclusion Protocol och öppnade sina robots.txt-parser.
TL; DR
- Googles robotar .txt-tolk är ganska flexibel och överraskande förlåtande.
- Vid förvirringsdirektiv gör Google fel på de säkra sidorna och antar att avsnitt bör begränsas snarare än obegränsade.
Sökmotorer kontrollerar regelbundet en webbplats robots.txt-fil för att se om det finns några instruktioner för genomsökning av webbplatsen. Vi kallar dessa instruktionsdirektiv.
Om det inte finns någon robots.txt-fil eller om det inte finns några tillämpliga direktiv kommer sökmotorer att genomsöka hela webbplatsen.
Även om alla större sökmotorer respekterar robots.txt-filen kan sökmotorer välja att ignorera (delar av) din robots.txt-fil. Medan direktiv i robots.txt-filen är en stark signal till sökmotorerna är det viktigt att komma ihåg att robots.txt-filen är en uppsättning valfria direktiv till sökmotorer snarare än ett mandat.

Robots.txt är den mest känsliga filen i SEO-universum. En enda karaktär kan bryta en hel webbplats.
Terminologi kring robots.txt-fil
Roboten.txt-filen är implementeringen av robots uteslutningsstandard, eller kallas också protokollet för uteslutning av robotar.
Varför skulle du bry dig om robots.txt?
Robots.txt spelar en viktig roll ur SEO-synvinkel. Den berättar för sökmotorer hur de bäst kan genomsöka din webbplats.
Med hjälp av robots.txt-filen kan du förhindra sökmotorer från att komma åt vissa delar av din webbplats, förhindra duplicerat innehåll och ge sökmotorer användbara tips om hur de kan genomsöka din webbplats mer effektivt.
Var dock försiktig när du gör ändringar i din robots.txt: den här filen har potential att göra stora delar av din webbplats otillgängliga för sökmotorer.

Robots.txt används ofta för att minska duplicerat innehåll och därmed döda intern länk så var riktigt försiktig med det. Mitt råd är att bara använda det för filer eller sidor som sökmotorer aldrig ska se, eller som kan påverka genomsökningen avsevärt genom att släppas in. Vanliga exempel: inloggningsområden som genererar många olika webbadresser, testområden eller där flera facetterad navigering kan finnas. Och se till att övervaka din robots.txt-fil för eventuella problem eller ändringar.

De flesta problem som jag ser med robots.txt-filer faller i tre hinkar:
- Fel hantering av jokertecken. Det är ganska vanligt att se delar av webbplatsen blockerade som var avsedda att blockeras. Ibland, om du inte är försiktig, kan direktiven också komma i konflikt med varandra.
- Någon, som en utvecklare, har gjort en förändring ur det blåa (ofta när man trycker på en ny kod) och har av misstag ändrat robots.txt utan din vetskap.
- Inkludering av direktiv som inte hör hemma i en robots.txt-fil. Robots.txt är webbstandard och är något begränsat. Jag ser ofta utvecklare göra direktiv som helt enkelt inte kommer att fungera (åtminstone för den stora majoriteten av sökrobotar). Ibland är det ofarligt, ibland inte så mycket.
Exempel
Låt oss titta på ett exempel för att illustrera detta:
Du driver en e-handelswebbplats och besökare kan använda ett filter för att snabbt söka igenom dina produkter. Detta filter genererar sidor som i princip visar samma innehåll som andra sidor gör. Detta fungerar bra för användare, men förvirrar sökmotorer eftersom det skapar dubblettinnehåll.
Du vill inte att sökmotorer ska indexera dessa filtrerade sidor och slösa bort deras värdefulla tid på dessa webbadresser med filtrerat innehåll. Därför bör du ställa in Disallow regler så att sökmotorer inte får åtkomst till dessa filtrerade produktsidor.
Att förhindra duplicerat innehåll kan också göras med den kanoniska URL: n eller meta-robot-taggen, men dessa tar inte upp att låta sökmotorer bara genomsöka sidor som är viktiga.
Att använda en kanonisk URL eller meta-robot-tagg hindrar inte sökmotorer från att genomsöka dessa sidor. Det förhindrar bara sökmotorer från att visa dessa sidor i sökresultaten. Eftersom sökmotorer har begränsad tid att genomsöka en webbplats bör denna tid ägnas åt sidor som du vill ska visas i sökmotorer.
En felaktigt konfigurerad robots.txt-fil kan hålla tillbaka din SEO-prestanda. Kontrollera om detta är fallet för din webbplats direkt!

Det är ett väldigt enkelt verktyg, men en robots.txt-fil kan orsaka många problem om den inte är korrekt konfigurerad, särskilt för större webbplatser. Det är väldigt enkelt att göra misstag som att blockera en hel webbplats efter att en ny design eller CMS har rullats ut eller inte blockera delar av en webbplats som ska vara privat. För större webbplatser är det mycket viktigt att se till att Google genomsöker effektivt och att en välstrukturerad robots.txt-fil är ett viktigt verktyg i den processen.
Du måste ta dig tid att förstå vilka delar av din webbplats som bäst hålls borta från Google så att de spenderar så mycket av sin resurs som möjligt på att genomsöka de sidor som du verkligen bryr dig om.
Hur ser en robots.txt-fil ut?
Ett exempel på hur en enkel robots.txt-fil för en WordPress-webbplats kan ser ut som:
Låt oss förklara anatomin för en robots.txt-fil baserat på exemplet ovan:
- Användaragent:
user-agentanger för vilken sökning motorerna de riktlinjer som följer är avsedda. -
*: detta indikerar att direktiven är avsedda för alla sökmotorer. -
Disallow: detta är ett direktiv som anger vilket innehåll som inte är tillgängligt föruser-agent. -
/wp-admin/: detta ärpathsom är otillgänglig föruser-agent.
Sammanfattningsvis: den här robots.txt-filen ber alla sökmotorer att hålla sig utanför /wp-admin/ -katalogen.
Låt oss analysera de olika komponenter i robots.txt-filer mer detaljerat:
- User-agent
- Disallow
- Tillåt
- Sitemap
- Genomsökningsfördröjning
Användaragent i robots.txt
Varje sökmotor ska identifiera sig med en user-agent. Googles robotar identifierar till exempel Googlebot till exempel Yahoos robotar som Slurp och Bings robot som BingBot och så vidare.
user-agent -posten definierar början på en grupp av direktiv. Alla direktiv mellan den första user-agent och nästa user-agent post behandlas som riktlinjer för den första user-agent.
Direktiven kan tillämpas på specifika användaragenter, men de kan också tillämpas på alla användaragenter. I så fall används ett jokertecken: User-agent: *.
Tillåt inte direktivet i robots.txt
Du kan säga till sökmotorer att inte komma åt vissa filer, sidor eller delar av din webbplats. Detta görs med hjälp av direktivet Disallow. Direktivet Disallow följs av path som inte bör nås. Om inget path definieras ignoreras direktivet.
Exempel
I det här exemplet uppmanas alla sökmotorer att inte komma åt katalogen /wp-admin/.
Tillåt direktiv i robots.txt
Allow -direktivet används för att motverka ett Disallow -direktiv. Allow -direktivet stöds av Google och Bing. Genom att använda direktiven Allow och Disallow kan du berätta för sökmotorer att de kan komma åt en specifik fil eller sida i en katalog som annars inte tillåts. Direktivet Allow följs av path som kan nås. Om inget path definieras ignoreras direktivet.
Exempel
I exemplet ovan får alla sökmotorer inte tillgång till /media/ -katalog, förutom filen /media/terms-and-conditions.pdf.
Viktigt: när du använder Allow och Disallow riktlinjer tillsammans, var noga med att inte använda jokertecken eftersom detta kan leda till motstridiga direktiv.
Exempel på motstridiga direktiv
Sökmotorer vet inte vad de ska göra med webbadressen . Det är oklart för dem om de får åtkomst. När direktiv inte är tydliga för Google kommer de att följa det minst restriktiva direktivet, vilket i det här fallet innebär att de faktiskt skulle få åtkomst till
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt är en av de funktioner som jag oftast ser implementerad felaktigt så att den inte blockerar vad de ville blockera eller blockerar mer än de förväntade sig och har en negativ inverkan på deras webbplats. Robots.txt är ett mycket kraftfullt verktyg men alltför ofta är det felaktigt inställt.
Använda jokertecken *
Jokertecken kan inte bara användas för att definiera user-agent, det kan också användas för att matcha webbadresser. Jokerteckenet stöds av Google, Bing, Yahoo och Ask.
Exempel
I exemplet ovan får inte alla sökmotorer tillgång till webbadresser som innehåller ett frågetecken (?).

Utvecklare eller webbplatsägare verkar ofta tro att de kan använda alla slags reguljära uttryck i en robots.txt-fil medan endast en mycket begränsad mängd mönstermatchning faktiskt är giltig – till exempel jokertecken (
*). Det verkar finnas en förvirring mellan .htaccess-filer och robots.txt-filer då och då.
Användning av webbadressens slut $
För att ange slutet på en URL kan du använda dollartecknet ($) i slutet av path.
Exempel
I exemplet ovan får sökmotorer inte komma åt alla webbadresser som slutar med .php . URL: er med parametrar, t.ex. skulle inte tillåtas, eftersom webbadressen inte slutar efter .php.
Lägg till webbplatskarta i robotar. txt
Även om robots.txt-filen uppfanns för att berätta för sökmotorer vilka sidor som inte ska genomsökas, kan robots.txt-filen också användas för att peka sökmotorer till XML-webbplatskartan. Detta stöds av Google, Bing, Yahoo och Ask.
XML-webbplatskartan bör refereras till som en absolut webbadress. URL: en behöver inte vara på samma värd som robots.txt-filen.
Hänvisning till XML-webbplatskartan i robots.txt-filen är en av de bästa metoderna vi rekommenderar att du alltid gör, även om du kanske redan har skickat in din XML-webbplatskarta i Google Search Console eller Bing Webmaster Tools. Kom ihåg att det finns fler sökmotorer där ute.
Observera att det är möjligt att referera till flera XML-webbplatskartor i en robots.txt-fil.
Exempel
Flera XML-webbplatskartor definierade i en robots.txt-fil:
En enda XML-webbplatskarta definierad i en robot.txt-fil:
Exemplet ovan berättar för alla sökmotorer att inte komma åt katalogen /wp-admin/ och att XML-webbplatskartan finns på
Comments are preceded by a # antingen placeras i början av en rad eller efter ett direktiv på samma rad. Allt efter # ignoreras. Dessa kommentarer är endast avsedda för människor.
Exempel 1
Exempel 2
Exemplen ovan kommunicerar samma meddelande.
Genomsökningsfördröjning i robots.txt
Crawl-delay direktivet är ett inofficiellt direktiv som används för att förhindra överbelastning av servrar med för många förfrågningar. Om sökmotorer kan överbelasta en server är det bara en tillfällig åtgärd att lägga till Crawl-delay i din robots.txt-fil. Faktum är att din webbplats körs i en dålig värdmiljö och / eller att din webbplats är felaktigt konfigurerad och du bör åtgärda det så snart som möjligt.
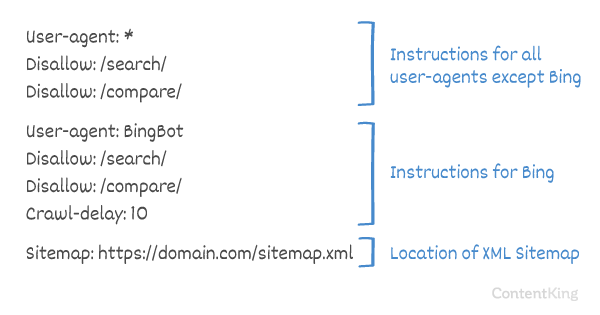
Hur sökmotorer hanterar Crawl-delay skiljer sig åt. Nedan förklarar vi hur stora sökmotorer hanterar det.
Genomsökning och Google
Googles sökrobot, Googlebot, stöder inte Crawl-delay direktivet, så bry dig inte om att definiera en Googles genomsökningsfördröjning.
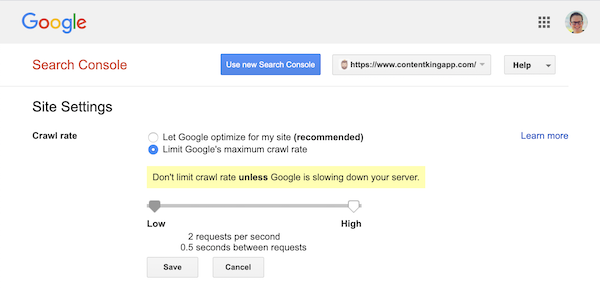
Google stöder dock att definiera en genomsökningshastighet (eller ”begäran” om du vill ) i Google Search Console.
- Logga in på den gamla Google Search Console.
- Välj webbplatsen du vill definiera genomsökningshastigheten för.
- Det finns bara en inställning som du kan justera:
Crawl rate, med en skjutreglage där du kan ställa in önskad genomsökningshastighet. Som standard genomsökningshastigheten är inställd på ”Låt Google optimera för min webbplats (rekommenderas)”.
Så här ser det ut i Google Search Console:
Genomsökning och Bing, Yahoo och Yandex
Bing, Yahoo och Yandex alla stöder Crawl-delay direktiv för gasreglering av en webbplats. Deras tolkning av genomsökningsfördröjningen är dock något annorlunda, så se till att kontrollera deras dokumentation:
- Bing och Yahoo
- Yandex
Direktivet Crawl-delay bör placeras direkt efter Disallow eller Allow -direktiven.
Exempel:
Genomsökning och Baidu
Baidu stöder inte crawl-delay -direktivet, men det är möjligt att registrera ett Baidu Webmaster Tools-konto i som du kan kontrollera genomsökningsfrekvensen, liknar Google Search Console.
När ska du använda en robots.txt-fil?
Vi rekommenderar att du alltid använder en robots.txt-fil. Det finns absolut ingen skada att ha en, och det är ett utmärkt ställe att ge sökmotordirektiv om hur de bäst kan genomsöka din webbplats.

Robots.txt kan vara användbart för att förhindra att vissa områden eller dokument på din webbplats genomsöks och indexeras. Exempel är till exempel iscensättningssidan eller PDF-filer. Planera noggrant vad som måste indexeras av sökmotorer och var uppmärksam på att innehåll som har gjorts otillgängligt via robots.txt fortfarande kan hittas av sökmotors sökrobotar om det är länkat till från andra delar av webbplatsen.
Robots.txt bästa metoder
De bästa metoderna för robots.txt kategoriseras enligt följande:
- Plats och filnamn
- Prioritetsordning
- Endast en grupp riktlinjer per robot
- Var så specifik som möjligt
- Direktiv för alla robotar samtidigt som du inkluderar direktiv för en specifik robot
- Robots.txt-fil för varje (under) domän.
- Motstridiga riktlinjer: robots.txt vs Google Search Console
- Övervaka din robots.txt-fil
- Använd inte noindex i din robots.txt
- Förhindra UTF-8 BOM i robots.txt-filen
Plats och filnamn
Roboten.txt-filen ska alltid placeras i th e root på en webbplats (i värdens toppkatalog) och bär filnamnet robots.txt, till exempel: . Observera att URL: en för robots.txt-filen är, som alla andra webbadresser, skiftlägeskänslig.
Om robots.txt-filen inte kan hittas på standardplatsen, antar sökmotorerna att det inte finns några direktiv och genomsöker på din webbplats.
Prioritetsordning
Det är viktigt att notera att sökmotorer hanterar robots.txt-filer på olika sätt. Som standard vinner alltid det första matchande direktivet.
Men med Google och Bing-specificitet vinner det. Till exempel: ett Allow -direktiv vinner ett Disallow -direktiv om dess karaktärslängd är längre.
Exempel
I exempel framför allt sökmotorer, inklusive Google och Bing, får inte komma åt katalogen /about/, förutom underkatalogen /about/company/.
Exempel
I exemplet ovan får alla sökmotorer utom Google och Bing åtkomst till /about/ -katalogen. Det inkluderar katalogen /about/company/.
Google och Bing får åtkomst, eftersom Allow -direktivet är längre än direktivet Disallow -direktiv.
Endast en grupp direktiv per robot
Du kan bara definiera en grupp direktiv per sökmotor. Att ha flera grupper av direktiv för en sökmotor förvirrar dem.
Var så specifik som möjligt
Disallow -direktivet utlöser partiella matchningar som väl. Var så specifik som möjligt när du definierar Disallow -direktivet för att förhindra oavsiktligt att inte tillåta åtkomst till filer.
Exempel:
Exemplet ovan tillåter inte sökmotorer tillgång till:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Direktiv för alla robotar samtidigt som direktiv för en specifik robot
För en robot endast en grupp av direktiv är giltig. Om direktiv som är avsedda för alla robotar följs med direktiv för en specifik robot kommer endast dessa specifika direktiv att beaktas. För att den specifika roboten också ska följa riktlinjerna för alla robotar måste du upprepa dessa riktlinjer för den specifika roboten.
Låt oss titta på ett exempel som gör detta tydligt:
Exempel
Om du inte vill att googlebot ska få tillgång till /secret/ och /not-launched-yet/ måste du upprepa dessa direktiv för googlebot specifikt:
Observera att din robots.txt-fil är allmänt tillgänglig. Att tillåta webbplatsavsnitt där inne kan användas som en attackvektor av personer med skadlig avsikt.

Robots.txt kan vara farligt. Du berättar inte bara sökmotorer var du inte vill att de ska leta, du berättar för människor var du gömmer dina smutsiga hemligheter.
Robots.txt-fil för varje (sub) domän
Endast Robots.txt-direktiv gäller för (under) domänen som filen är värd för.
Exempel
gäller för , men inte för eller
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Vi byggde robots.txt-ändringsspårning och varning av den anledningen.
Vi ser det hela tiden: robots.txt-filer ändras utan kunskap om digital marknadsföring team. Var inte den personen. Börja övervaka din robots.txt-fil och få varningar när den ändras!
Använd inte noindex i din robots.txt
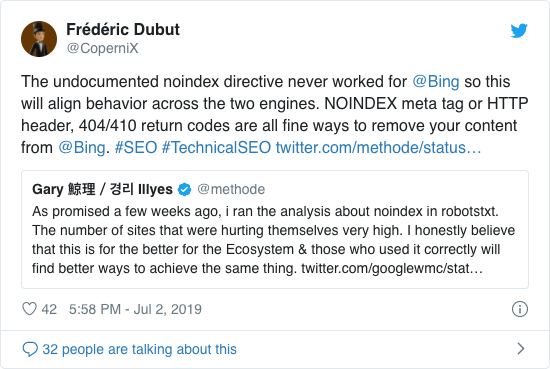
I flera år rekommenderade Google redan öppet att använda det inofficiella noindex-direktivet. Från och med den 1 september 2019 slutade dock Google att stödja det helt.
Det inofficiella noindex-direktivet fungerade aldrig i Bing, vilket bekräftades av Frédéric Dubut i denna tweet:
Det bästa sättet att signalera till sökmotorer om att sidor inte ska indexeras är att använda meta-robot-taggen eller X-Robots-Tag .
Förhindra UTF-8 BOM i robots.txt-fil
BOM står för byte ordermark, ett osynligt tecken i början av en fil som används för att indikera Unicode-kodning av en textfil.
Medan Google säger att de ignorerar det valfria Unicode-bytebeställningsmärket i början av robots.txt-filen, rekommenderar vi att du förhindrar ”UTF-8 BOM” eftersom vi har sett det orsaka problem med tolkningen av robots.txt-filen av sökmotorer.
Även om Google säger att de kan hantera det, här är två skäl för att förhindra UTF-8 BOM:
- Du behöver inte vill inte ha några tvetydigheter kring dina preferenser kring genomsökning till sökmotorer.
- Det finns andra sökmotorer där ute, som kanske inte är så förlåtande som Google påstår sig vara.
Robots.txt-exempel
I det här kapitlet kommer vi att täcka ett stort antal exempel på robots.txt-filer:
- Ge alla robotar tillgång till allt
- Tillåt alla robotar tillgång till allt
- Alla Google-bots har inte åtkomst
- Alla Google-bots, förutom Googlebot-nyheter, har inte tillgång
- Googlebot och Slurp har ingen åtkomst
- Alla robotar har inte tillgång till två kataloger
- Alla robotar har inte tillgång till en specifik fil
- Googlebot har inte åtkomst till / admin / och Slurp har inte tillgång till / privat /
- Robots.txt-fil för WordPress
- Robots.txt-fil för Magento
Ge alla robotar tillgång till allt
Det finns flera sätt för att berätta för sökmotorer att de kan komma åt alla filer:
Eller ha en tom robots.txt-fil eller inte ha någon robots.txt alls.
Tillåt alla robotar tillgång till allt
Exemplet robots.txt nedan berättar för alla sökmotorer att inte komma åt hela webbplatsen:
Observera att bara ETT extra tecken kan göra skillnad.
Alla Google-bots har inte åtkomst
Observera att när du inte tillåter Googlebot gäller detta alla Googlebots. Detta inkluderar Google-robotar som till exempel söker efter nyheter (googlebot-news) och bilder (googlebot-images).
Alla Googles bots, förutom Googlebot-nyheter, har inte tillgång
Googlebot och Slurp har ingen åtkomst
Alla robotar har inte tillgång till två kataloger
Alla robotar har inte åtkomst till en specifik fil
Googlebot har inte tillgång till / admin / och Slurp har inte tillgång till / privat /
Robots.txt fil för WordPress
Roboten.txt-filen nedan är specifikt optimerad för WordPress, förutsatt att:
- Du vill inte att din administratörssektion ska genomsökas.
- Du vill inte att dina interna sökresultatsidor ska genomsökas.
- Du vill inte att dina taggar och författarsidor ska genomsökas.
- Du behöver inte ’ t vill att din 404-sida ska genomsökas.
Observera att den här robots.txt-filen fungerar i de flesta fall, men du bör alltid justera den och testa den för att se till att den gäller din exakt situation.
Robots.txt-fil för Magento
Roboten.txt-filen nedan är specifikt optimerad för Magento och ger interna sökresultat, inloggningssidor, sessionsidentifierare och filtrerat resultat uppsättningar som innehåller price, color, material och size kriterier oåtkomliga för sökrobotar.
Observera att den här robots.txt-filen fungerar för de flesta Magento-butiker, men du bör alltid justera det och testa det för att se till att det gäller din exakta situation.
Jag vill fortfarande alltid blockera interna sökresultat i robots.txt på vilken webbplats som helst eftersom dessa typer av webbadresser är oändliga och oändliga. Det finns mycket potential för Googlebot att hamna i en sökrobot.
Vilka är begränsningarna för robots.txt-filen?
Robots.txt-filen innehåller direktiv
Även om robots.txt respekteras väl av sökningen motorer, det är fortfarande ett direktiv och inte ett mandat.
Sidor som fortfarande visas i sökresultat
Sidor som är oåtkomliga för sökmotorer på grund av robotarna.txt, men har länkar till dem kan fortfarande visas i sökresultaten om de är länkade från en sida som genomsöks. Ett exempel på hur detta ser ut:

Det är möjligt att ta bort dessa webbadresser från Google med Google Search Consoles verktyg för borttagning av webbadresser. Observera att dessa webbadresser bara ”döljs” tillfälligt. För att de ska kunna hålla sig utanför Googles resultatsidor måste du skicka en begäran om att dölja webbadresserna var 180: e dag.

Använd robots.txt för att blockera oönskade och sannolikt skadliga anslutna bakåtlänkar. använd inte robots.txt i ett försök att förhindra att innehåll indexeras av sökmotorer, eftersom detta oundvikligen misslyckas. Använd istället robotdirektiv noindex vid behov.
Robots.txt-filen cachas upp till 24 timmar
Google har angett att en robot .txt-filen är vanligtvis cachad i upp till 24 timmar. Det är viktigt att ta hänsyn till detta när du gör ändringar i din robots.txt-fil.
Det är oklart hur andra sökmotorer hanterar cachning av robots.txt , men i allmänhet är det bäst att undvika att cacha din robots.txt-fil till av oid-sökmotorer tar längre tid än nödvändigt för att kunna hämta ändringar.
Robots.txt-filstorlek
För robots.txt-filer stöder Google för närvarande en filstorleksgräns på 500 kibytes. (512 kilobyte). Allt innehåll efter denna maximala filstorlek kan ignoreras.
Det är oklart om andra sökmotorer har maximal filstorlek för robots.txt-filer.
Vanliga frågor om robots.txt
🤖 Hur ser ett robots.txt-exempel ut?
Här är ett exempel på ett robots.txt-innehåll: User-agent: * Disallow:. Detta berättar för alla sökrobotar att de kan få tillgång till allt.
does Vad tillåter inte alla att göra i robots.txt?
När du ställer in en robots.txt på ”Tillåt inte alla” är du i huvudsak berätta för alla sökrobotar att hålla sig borta. Inga sökrobotar, inklusive Google, får åtkomst till din webbplats. Det betyder att de inte kommer att kunna genomsöka, indexera och rangordna din webbplats. Detta kommer att leda till en enorm nedgång i organisk trafik.
✅ Vad gör tillåt allt i robots.txt?
När du ställer in robots.txt på ”Tillåt allt”, säger du till varje sökrobot att de kan komma åt alla webbadresser på webbplatsen. Det finns helt enkelt inga regler för förlovning. Observera att detta motsvarar att ha ett tomt robots.txt eller inte ha något robots.txt alls.
🤔 Hur viktigt är robots.txt för SEO?
I allmänt är robots.txt-filen mycket viktig för SEO-ändamål. För större webbplatser är robots.txt viktigt för att ge sökmotorer mycket tydliga instruktioner om vilket innehåll som inte får åtkomst.