Det är ingen hemlighet. Vi lever officiellt i big data-eran. Nästan alla företag – särskilt stora företag – samlar in, lagrar och analyserar data till förmån för tillväxt. I de flesta dagliga affärsverksamheter är hantering av data en norm, med hjälp av verktyg som:
- Databaser
- Automationssystem
- CRM-plattformar
Om du har arbetat i något företag under en tid har du förmodligen stött på termen Data Normalization. En bästa praxis för hantering och användning av lagrad information, datanormalisering är en process som hjälper till att förbättra framgången för ett helt företag.
Här är allt du behöver veta om datanormalisering tillsammans med några tips om hur du kan förbättra dina data effektivt.
Vad är datanormalisering?
Datanormalisering anses allmänt vara utvecklingen av rena data. Att dyka djupare är dock innebörden eller målet för datanormalisering dubbelt:
- Datanormalisering är organisationen av data så att de liknar alla poster och fält.
- Det ökar sammanhållningen av ingångstyper som leder till rensning, leadgenerering, segmentering och högre kvalitetsdata.
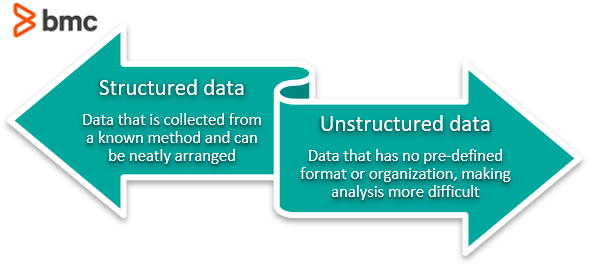
Enkelt uttryckt inkluderar denna process att eliminera ostrukturerad data och redundans (dubbletter) för att säkerställa logiska data lagring. När datanormalisering är korrekt kommer du att sluta med standardiserad informationsinmatning. Till exempel gäller denna process hur URL: er, kontaktnamn, gatuadresser, telefonnummer och till och med koder registreras. Dessa standardiserade informationsfält kan sedan grupperas och läsas snabbt.
Vem behöver datanormalisering?
Varje företag som vill driva framgångsrikt och växa måste regelbundet utföra normalisering av data. Det är en av de viktigaste sakerna du kan göra för att bli av med fel som gör löpande informationsanalyser komplicerade och svåra. Sådana fel smyger sig ofta när du ändrar, lägger till eller tar bort systeminformation. När datainmatningsfel tas bort kommer en organisation att ha ett väl fungerande system som är fullt av användbara, fördelaktiga data.
Med normalisering kan en organisation utnyttja sina data så väl som investera i datainsamling på en större, effektivare nivå. Att titta på data för att förbättra hur ett företag drivs blir en mindre utmanande uppgift, särskilt vid korsundersökning. För dem som regelbundet konsoliderar och frågar efter data från programvara-som-tjänst-applikationer såväl som för dem som samlar in data från en mängd olika källor som sociala medier, digitala webbplatser och mer, blir datanormalisering en ovärderlig process som sparar tid, utrymme och pengar.
Hur datanormalisering fungerar
Nu är det dags att notera att din normalisering, beroende på din specifika typ av data, ser annorlunda ut.
När det är mest grundläggande är normalisering helt enkelt att skapa ett standardformat för alla data i ett företag:
- Miss EMILY kommer att skrivas i fru Emily
- 8023097864 kommer att skrivas skrivet 802-309-7864
- 24 canillas RD kommer att skrivas 24 Canillas Road
- GoogleBiz kommer att skrivas Google Biz, Inc.
- VP-marknadsföring kommer att skrivas Vice president för marknadsföring
Utöver grundläggande formatering är experter överens om att det finns fem allmänna regler eller ”normala former” för att utföra datanormalisering. Varje regel fokuserar på att sätta e ntity typer i antal kategorier beroende på nivån av komplexitet. Anses vara riktlinjer för normalisering, det finns tillfällen när variationer från formuläret måste ske. Vid variationer är det viktigt att överväga konsekvenser och avvikelser.
För komplexitetsändamål diskuteras i den här artikeln de första och tre vanligaste formerna på toppnivå och all data är beaktas i tabellformat.
First Normal Form (1NF)
Den mest grundläggande formen för datanormalisering är 1NFm vilket säkerställer att det inte finns några upprepade poster i en grupp. För att betraktas som 1NF måste varje post bara ha ett enda värde för varje cell och varje post måste vara unik.
Till exempel spelar du in en persons namn, adress, kön och om de köpte cookies.
Andra normala formuläret (2NF)
Återigen arbetar vi för att säkerställa att inga upprepade poster, för att vara i 2NF-regeln, måste data först gälla alla 1NF-kraven. Därefter måste data bara ha en primär nyckel. För att separera data för att bara ha en primär nyckel, bör alla underuppsättningar av data som kan placeras i flera rader placeras i separata tabeller. Sedan kan relationer skapas genom nya utländska nyckeletiketter.
Du registrerar till exempel namn, adress, kön på en person, om de köpte kakor, liksom kaketyper. Cookietyperna placeras i en annan tabell med motsvarande främmande nyckel till varje persons namn.
Tredje normala formuläret (3NF)
För att data ska vara i denna regel måste de först uppfylla alla 2NF-kraven. Efter det måste data i en tabell bara vara beroende av den primära nyckeln. Om den primära nyckeln ändras måste all data som påverkas läggas i en ny tabell.
Till exempel spelar du in en persons namn, adress och kön men går tillbaka och byter namn av en person. När du gör detta kan könen också förändras. För att undvika detta ges i 3NF kön en främmande nyckel och en ny tabell för att lagra kön.
När du börjar förstå normaliseringsformerna blir reglerna tydligare när du delar dina data i tabeller och nivåer blir enkla. Dessa tabeller gör det sedan enkelt för alla inom en organisation att samla in information och se till att de samlar in korrekta data som inte dupliceras.
Fördelarna med datanormalisering
Som nämnts ovan är det mest viktig del av datanormalisering är bättre analys som leder till tillväxt; Det finns dock några otroliga fördelar med denna process:
Mer utrymme
Med databaser fyllda med information frigör organisation och eliminering av dubbletter mycket nödvändigt gigabyte- och terabyteutrymme. När ett system laddas med onödiga saker minskar bearbetningsprestandan. Efter rengöring av digitalt minne kommer dina system att köras snabbare och laddas snabbare, vilket innebär att dataanalys görs i en effektivare takt.
Snabbare svar på frågor
På tal om snabbare processer, efter normalisering blir en enkel uppgift kan du organisera dina data utan att behöva ändra dem ytterligare. Detta hjälper olika team inom ett företag att spara värdefull tid istället för att försöka översätta galna data som inte har lagrats ordentligt.
Bättre segmentering
Ett av de bästa sätten att växa ett företag är att säkerställa blysegmentering. Med datanormalisering kan grupper snabbt delas in i kategorier baserat på titlar, branscher – du heter det. Att skapa listor baserat på vad som är värdefullt för en specifik lead är en process som inte längre orsakar huvudvärk.
Data normalisering är inte ett alternativ
Eftersom data blir mer värdefulla för alla typer av hur det är organiserat i masskvaliteter kan inte förbises.
Från att säkerställa leverans av e-postmeddelanden till att förhindra felaktiga uppringningar och förbättra analysen av grupper utan att oroa sig för dubbletter, är det lätt att se att när data normalisering utförs korrekt resulterar det i bättre övergripande affärsfunktion. Tänk dig om du lämnar dina data i ordning och missar viktiga tillväxtmöjligheter på grund av att en webbplats inte laddas eller anteckningar inte kommer till en VP. Inget av det låter som framgång eller tillväxt.
Att välja att normalisera data är en av de viktigaste sakerna du kan göra för din organisation idag.