Det er ingen hemmelighed. Vi lever officielt i æraen med big data. Næsten alle virksomheder – især store virksomheder – indsamler, gemmer og analyserer data til gavn for vækst. I de fleste daglige forretningsdrift er styring af data en norm ved hjælp af værktøjer som:
- Databaser
- Automatiseringssystemer
- CRM-platforme
Hvis du har arbejdet i et hvilket som helst firma i nogen tid, har du sandsynligvis stødt på udtrykket Data Normalization. En bedste praksis til håndtering og anvendelse af lagret information, datanormalisering er en proces, der hjælper med at forbedre succes på tværs af en hel virksomhed.
Her er alt hvad du behøver at vide om datanormalisering sammen med nogle tip til, hvordan du forbedrer dine data effektivt.
Hvad er data normalisering?
Data normalisering betragtes generelt som udviklingen af rene data. Når man dykker dybere, er betydningen eller målet for datanormalisering dobbelt:
- Datanormalisering er organisationen af data, der skal se ens ud på tværs af alle poster og felter.
- Det øges sammenhængen mellem indtastningstyper, der fører til rensning, leadgenerering, segmentering og højere kvalitetsdata.
Enkelt sagt inkluderer denne proces eliminering af ustrukturerede data og redundans (duplikater) for at sikre logiske data opbevaring. Når data normaliseres korrekt, vil du ende med standardiseret information. For eksempel gælder denne proces for, hvordan webadresser, kontaktnavne, gadenavne, telefonnumre og endda koder registreres. Disse standardiserede informationsfelter kan derefter grupperes og læses hurtigt.
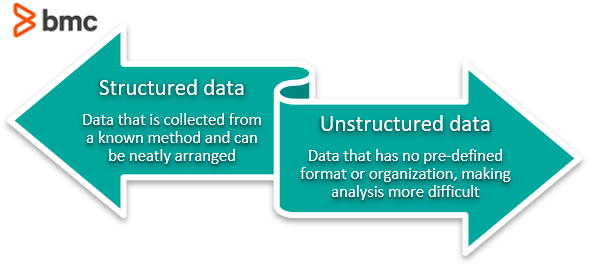
Hvem har brug for datanormalisering?
Enhver virksomhed, der ønsker at køre med succes og vokse, skal regelmæssigt udføre datanormalisering. Det er en af de vigtigste ting, du kan gøre for at slippe af med fejl, der gør løbende informationsanalyse kompliceret og vanskelig. Sådanne fejl sniger sig ofte, når du ændrer, tilføjer eller fjerner systemoplysninger. Når dataindtastningsfejl fjernes, vil en organisation have et velfungerende system, der er fyldt med brugbare, gavnlige data.
Med normalisering kan en organisation få mest muligt ud af sine data såvel som investere i dataindsamling på et større og mere effektivt niveau. At se på data for at forbedre, hvordan en virksomhed drives, bliver en mindre udfordrende opgave, især når man krydserverer. For dem, der regelmæssigt konsoliderer og forespørger om data fra software-as-a-service-applikationer såvel som for dem, der samler data fra en række kilder som sociale medier, digitale websteder og mere, bliver datanormalisering en uvurderlig proces, der sparer tid, plads og penge.
Sådan fungerer datanormalisering
Nu er det tid til at bemærke, at din normalisering, afhængigt af din specifikke datatype, ser anderledes ud.
Normalt er normalisering simpelthen at skabe et standardformat for alle data i hele virksomheden:
- Miss EMILY vil blive skrevet i fru Emily
- 8023097864 vil være skrevet 802-309-7864
- 24 canillas RD vil blive skrevet 24 Canillas Road
- GoogleBiz vil blive skrevet Google Biz, Inc.
- VP marketing vil blive skrevet Vice President of Marketing
Ud over grundlæggende formatering er eksperter enige om, at der er fem generelle regler eller “normale former” for udførelse af datanormalisering. Hver regel fokuserer på at sætte e ntity typer i antal kategorier afhængigt af kompleksitetsniveauet. Betragtes som retningslinjer for normalisering, er der tilfælde, hvor variationer fra formularen skal finde sted. I tilfælde af variationer er det vigtigt at overveje konsekvenser og uregelmæssigheder.
Af hensyn til kompleksiteten diskuteres i denne artikel den første og tre mest almindelige former på et topniveau, og alle data er betragtes i tabelformat.
Første normale form (1NF)
Den mest basale form for datanormalisering er 1NFm, hvilket sikrer, at der ikke er gentagne poster i en gruppe. For at blive betragtet som 1NF skal hver post kun have en enkelt værdi for hver celle, og hver post skal være unik.
For eksempel registrerer du navn, adresse, køn på en person, og hvis de købte cookies.
Anden normal form (2NF)
Igen for at sikre, at der ikke gentages poster, for at være i 2NF-reglen skal dataene først gælde for alle 1NF-kravene. Herefter skal data kun have en primær nøgle. For at adskille data for kun at have en primær nøgle skal alle undersæt af data, der kan placeres i flere rækker, placeres i separate tabeller. Derefter kan relationer oprettes gennem nye udenlandske nøgleetiketter.
For eksempel registrerer du navn, adresse, køn på en person, hvis de købte cookies såvel som cookietyperne. Cookietyperne placeres i en anden tabel med en tilsvarende fremmed nøgle til hver persons navn.
Tredje normal form (3NF)
For at data skal være i denne regel, skal de først overholde alle 2NF-kravene. Herefter skal data i en tabel kun afhænge af den primære nøgle. Hvis den primære nøgle ændres, skal alle data, der påvirkes, placeres i en ny tabel.
For eksempel registrerer du navn, adresse og køn på en person, men gå tilbage og skift navn af en person. Når du gør dette, kan kønnet muligvis også ændre sig. For at undgå dette gives i 3NF køn en fremmed nøgle og en ny tabel til lagring af køn.
Når du begynder bedre at forstå normaliseringsformularerne, bliver reglerne mere klare, mens du adskiller dine data i tabeller og niveauer bliver ubesværet. Disse tabeller vil derefter gøre det enkelt for alle inden for en organisation at indsamle information og sikre, at de indsamler korrekte data, der ikke duplikeres.
Fordele ved datanormalisering
Som nævnt ovenfor er det mest vigtig del af datanormalisering er bedre analyse, der fører til vækst; der er dog nogle få flere utrolige fordele ved denne proces:
Mere plads
Med databaser fyldt med information frigiver tiltrængt gigabyte- og terabyte plads til organisering og eliminering af dubletter. Når et system er fyldt med unødvendige ting, falder behandlingsydelsen. Efter rengøring af digital hukommelse kører dine systemer hurtigere og indlæses hurtigere, hvilket betyder, at dataanalyse udføres i en mere effektiv hastighed.
Hurtigere spørgsmålssvar
Når vi taler om hurtigere processer, efter at normalisering bliver en simpel opgave, kan du organisere dine data uden behov for yderligere at ændre. Dette hjælper forskellige teams inden for en virksomhed med at spare værdifuld tid i stedet for at forsøge at oversætte skøre data, der ikke er gemt ordentligt.
Bedre segmentering
En af de bedste måder at vokse en forretning på er at sikre blysegmentering. Med datanormalisering kan grupper hurtigt opdeles i kategorier baseret på titler, brancher – du hedder det. Oprettelse af lister baseret på, hvad der er værdifuldt for en bestemt kundeemne, er en proces, der ikke længere forårsager hovedpine.
Datanormalisering er ikke en mulighed
Da data bliver mere værdifulde for alle typer den måde, det er organiseret i massekvaliteter på, ikke kan overses.
Fra at sikre levering af e-mails til forebyggelse af fejlopkald og forbedring af analyser af grupper uden bekymring for duplikater er det let at se, at når data normalisering udføres korrekt, det resulterer i en bedre samlet forretningsfunktion. Forestil dig, hvis du efterlader dine data i uorden og går glip af vigtige vækstmuligheder på grund af et websted, der ikke indlæses, eller noter ikke kommer til en vicepræsident. Intet af det lyder som succes eller vækst.
At vælge at normalisere data er en af de vigtigste ting, du kan gøre for din organisation i dag.