A-robotter .txt-filen indeholder direktiver til søgemaskiner. Du kan bruge den til at forhindre søgemaskiner i at gennemgå bestemte dele af dit websted og give søgemaskiner nyttige tip til, hvordan de bedst kan gennemgå dit websted. Robots.txt-filen spiller en stor rolle i SEO.
Når du implementerer robots.txt, skal du huske følgende bedste praksis:
- Vær forsigtig, når du foretager ændringer i din robots.txt: denne fil har potentialet til at gøre store dele af dit websted utilgængelige for søgemaskiner.
- Robots.txt-filen skal findes i roden på dit websted (f.eks.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpellerhttps). - Forskellige søgemaskiner fortolker direktiver forskelligt. Som standard vinder det første matchende direktiv altid. Men med Google og Bing vinder specificitet.
- Undgå at bruge crawl-delay-direktivet til søgemaskiner så meget som muligt.
Hvad er en robots.txt-fil?
En robots.txt-fil fortæller søgemaskiner, hvad dit websteds regler for engagement er. En stor del af SEO handler om at sende de rigtige signaler til søgemaskiner, og robots.txt er en af måderne til at kommunikere dine gennemsøgningsindstillinger til søgemaskiner.
I 2019 har vi set ganske nogle udviklinger omkring robots.txt-standarden: Google foreslog en udvidelse af Robots Exclusion Protocol og åbnede sin robots.txt-parser.
TL; DR
- Googles robotter .txt-tolk er ret fleksibel og overraskende tilgivende.
- I tilfælde af forvirringsdirektiver tager Google fejl på de sikre sider og antager, at sektioner bør begrænses snarere end ubegrænsede.
Søgemaskiner kontrollerer regelmæssigt et websteds robots.txt-fil for at se, om der er nogen instruktioner til at gennemgå webstedet. Vi kalder disse instruktionsdirektiver.
Hvis der ikke findes nogen robots.txt-fil, eller hvis der ikke er nogen relevante direktiver, gennemgår søgemaskiner hele webstedet.
Selvom alle større søgemaskiner respekterer robots.txt-filen, kan søgemaskiner vælge at ignorere (dele af) din robots.txt-fil. Mens direktiver i robots.txt-filen er et stærkt signal til søgemaskiner, er det vigtigt at huske, at robots.txt-filen er et sæt valgfri direktiver til søgemaskiner snarere end et mandat.

Robots.txt er den mest følsomme fil i SEO-universet. Et enkelt tegn kan bryde et helt sted.
Terminologi omkring robots.txt-fil
Robotten.txt-filen er implementeringen af robottens ekskluderingsstandard eller også kaldet protokollen til ekskludering af robotter.
Hvorfor skal du være interesseret i robots.txt?
Robots.txt spiller en vigtig rolle fra et SEO-synspunkt. Det fortæller søgemaskiner, hvordan de bedst kan gennemgå dit websted.
Ved hjælp af robots.txt-filen kan du forhindre søgemaskiner i at få adgang til bestemte dele af dit websted, forhindre duplikatindhold og give søgemaskiner nyttige tip til, hvordan de kan gennemgå dit websted mere effektivt.
Vær dog forsigtig, når du foretager ændringer i din robots.txt: denne fil har potentialet til at gøre store dele af dit websted utilgængelige for søgemaskiner.

Robots.txt bruges ofte til at reducere duplikatindhold og derved dræbe intern sammenkædning, så vær virkelig forsigtig med det. Mit råd er kun at bruge det til filer eller sider, som søgemaskiner aldrig bør se, eller som kan have væsentlig indflydelse på gennemsøgning ved at blive tilladt. Almindelige eksempler: login-områder, der genererer mange forskellige webadresser, testområder eller hvor der kan findes flere facetteret navigation. Og sørg for at overvåge din robots.txt-fil for eventuelle problemer eller ændringer.

De fleste problemer, jeg ser med robots.txt-filer, falder i tre spande:
- Fejlhåndtering af jokertegn. Det er ret almindeligt at se dele af webstedet blokeret, der var beregnet til at blive blokeret. Nogle gange, hvis du ikke er forsigtig, kan direktiver også komme i konflikt med hinanden.
- Nogen, som f.eks. En udvikler, har foretaget en ændring ud af det blå (ofte ved at skubbe på ny kode) og har utilsigtet ændret sig robots.txt uden din viden.
- Inkludering af direktiver, der ikke hører hjemme i en robots.txt-fil. Robots.txt er webstandard og er noget begrænset. Jeg ser ofte udviklere udarbejde direktiver, der simpelthen ikke fungerer (i det mindste for det store flertal af crawlere). Nogle gange er det harmløst, nogle gange ikke så meget.
Eksempel
Lad os se på et eksempel for at illustrere dette:
Dig kører et e-handelswebsted, og besøgende kan bruge et filter til hurtigt at søge gennem dine produkter. Dette filter genererer sider, der grundlæggende viser det samme indhold som andre sider gør. Dette fungerer godt for brugerne, men forvirrer søgemaskiner, fordi det skaber duplikatindhold.
Du vil ikke have søgemaskiner til at indeksere disse filtrerede sider og spilde deres værdifulde tid på disse webadresser med filtreret indhold. Derfor skal du oprette Disallow regler, så søgemaskiner ikke får adgang til disse filtrerede produktsider.
Forebyggelse af duplikatindhold kan også gøres ved hjælp af den kanoniske URL eller meta-robot-tagget, men disse adresserer ikke, at søgemaskiner kun gennemsøger sider, der betyder noget.
Brug af en kanonisk URL eller meta-robot-tag forhindrer ikke søgemaskiner i at gennemgå disse sider. Det forhindrer kun søgemaskiner i at vise disse sider i søgeresultaterne. Da søgemaskiner har begrænset tid til at gennemgå et websted, skal denne tid bruges på sider, som du vil have vist i søgemaskiner.
En forkert opsat robots.txt-fil holder muligvis din SEO-præstation tilbage. Kontroller, om dette er tilfældet med dit websted med det samme!

Det er et meget simpelt værktøj, men en robots.txt-fil kan forårsage mange problemer, hvis den ikke er konfigureret korrekt, især til større websteder. Det er meget let at lave fejl som f.eks. At blokere et helt websted, efter at et nyt design eller CMS er rullet ud, eller ikke blokere sektioner af et websted, der skal være privat. For større websteder er det meget vigtigt at sikre, at Google gennemsøger effektivt, og at en velstruktureret robots.txt-fil er et vigtigt værktøj i denne proces.
Du skal tage dig tid til at forstå, hvilke dele af dit websted der bedst holdes væk fra Google, så de bruger så meget af deres ressource som muligt på at gennemgå de sider, som du virkelig holder af.
Hvordan ser en robots.txt-fil ud?
Et eksempel på hvordan en simpel robots.txt-fil til et WordPress-websted kan være ligner:
Lad os forklare anatomien i en robots.txt-fil baseret på eksemplet ovenfor:
- Brugeragent:
user-agentangiver til hvilken søgning de efterfølgende direktiver er ment. -
*: dette indikerer, at direktiverne er beregnet til alle søgemaskiner. -
Disallow: dette er et direktiv, der angiver, hvilket indhold der ikke er tilgængeligt foruser-agent. -
/wp-admin/: dette erpathsom er utilgængelig foruser-agent.
Sammenfattende: Denne robots.txt-fil fortæller alle søgemaskiner at holde sig ude af /wp-admin/ -mappen.
Lad os analysere de forskellige komponenter i robots.txt-filer mere detaljeret:
- User-agent
- Disallow
- Tillad
- Sitemap
- Crawl-delay
User-agent in robots.txt
Hver søgemaskine skal identificere sig selv med en user-agent. Googles robotter identificerer for eksempel som Googlebot, Yahoos robotter som Slurp og Bings robot som BingBot osv.
user-agent -posten definerer starten på en gruppe direktiver. Alle direktiver mellem den første user-agent og den næste user-agent -post behandles som direktiver for den første user-agent.
Direktiver kan gælde for specifikke brugeragenter, men de kan også gælde for alle brugeragenter. I så fald bruges et jokertegn: User-agent: *.
Tillad ikke direktiv i robots.txt
Du kan fortælle søgemaskinerne om ikke at få adgang bestemte filer, sider eller sektioner på dit websted. Dette gøres ved hjælp af Disallow -direktivet. Direktivet Disallow efterfølges af path, der ikke skal tilgås. Hvis der ikke er defineret path, ignoreres direktivet.
Eksempel
I dette eksempel bliver alle søgemaskiner bedt om ikke at få adgang til /wp-admin/ -mappen.
Tillad direktiv i robots.txt
Direktivet Allow bruges til at modvirke et Disallow -direktiv. Allow -direktivet understøttes af Google og Bing. Ved hjælp af direktiverne Allow og Disallow kan du fortælle søgemaskiner, at de kan få adgang til en bestemt fil eller side i et bibliotek, der ellers ikke er tilladt. Direktivet Allow efterfølges af path, der er tilgængelig. Hvis der ikke er defineret path, ignoreres direktivet.
Eksempel
I eksemplet ovenfor har alle søgemaskiner ikke adgang til /media/ -mappe, undtagen filen /media/terms-and-conditions.pdf.
Vigtigt: Når du bruger Allow og Disallow direktiver sammen, sørg for ikke at bruge jokertegn, da dette kan føre til modstridende direktiver.
Eksempel på modstridende direktiver
Søgemaskiner ved ikke, hvad de skal gøre med webadressen . Det er uklart for dem, om de har adgang. Når direktiver ikke er klare for Google, følger de det mindst restriktive direktiv, hvilket i dette tilfælde betyder, at de faktisk ville få adgang til
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt er en af de funktioner, jeg oftest ser implementeret forkert, så det blokerer ikke, hvad de ønskede at blokere, eller det blokerer mere, end de forventede, og har en negativ indvirkning på deres hjemmeside. Robots.txt er et meget kraftfuldt værktøj, men alt for ofte er det forkert opsat.
Brug af wildcard *
Wildcardet kan ikke kun bruges til at definere user-agent, det kan også bruges til at match webadresser. Jokertegnet understøttes af Google, Bing, Yahoo og Ask.
Eksempel
I eksemplet ovenfor har alle søgemaskiner ikke adgang til webadresser, der inkluderer et spørgsmålstegn (?).

Udviklere eller webstedsejere synes ofte at tro, at de kan bruge al slags regelmæssigt udtryk i en robots.txt-fil, mens kun en meget begrænset mængde mønstermatchning faktisk er gyldig – for eksempel jokertegn (
*). Der ser ud til at være en forveksling mellem .htaccess-filer og robots.txt-filer fra tid til anden.
Brug af slutningen af URL $
For at angive slutningen af en URL kan du bruge dollartegnet ($) i slutningen af path.
Eksempel
I eksemplet ovenfor har søgemaskiner ikke adgang til alle webadresser, der slutter med .php . URL’er med parametre, f.eks. vil ikke blive tilladt, da URL’en ikke slutter efter .php.
Føj sitemap til robotter. txt
Selvom robots.txt-filen blev opfundet for at fortælle søgemaskiner, hvilke sider der ikke skal gennemgås, kan robots.txt-filen også bruges til at pege søgemaskiner til XML-sitemap. Dette understøttes af Google, Bing, Yahoo og Ask.
XML-sitemap skal henvises til som en absolut URL. URL’en behøver ikke at være på samme vært som robots.txt-filen.
Henvisning til XML-sitemap i robots.txt-filen er en af de bedste fremgangsmåder, vi råder dig til altid at gøre, selvom du har muligvis allerede sendt dit XML-sitemap i Google Search Console eller Bing Webmaster Tools. Husk, der er flere søgemaskiner derude.
Bemærk, at det er muligt at henvise til flere XML-sitemaps i en robots.txt-fil.
Eksempler
Flere XML-sitemaps defineret i en robots.txt-fil:
Et enkelt XML-sitemap defineret i en robot.txt-fil:
Eksemplet ovenfor fortæller alle søgemaskiner, at de ikke har adgang til biblioteket /wp-admin/, og at XML-sitemap kan findes på
Comments are preceded by a # enten placeres i starten af en linje eller efter et direktiv på den samme linje. Alt efter # ignoreres. Disse kommentarer er kun beregnet til mennesker.
Eksempel 1
Eksempel 2
Eksemplerne ovenfor kommunikerer den samme besked.
Crawl-delay i robots.txt
Crawl-delay direktivet er et uofficielt direktiv, der bruges til at forhindre overbelastning af servere med for mange anmodninger. Hvis søgemaskiner er i stand til at overbelaste en server, er det kun en midlertidig løsning at tilføje Crawl-delay til din robots.txt-fil. Faktum er, at dit websted kører i et dårligt hostingmiljø, og / eller at dit websted er forkert konfigureret, og du skal rette det så hurtigt som muligt.
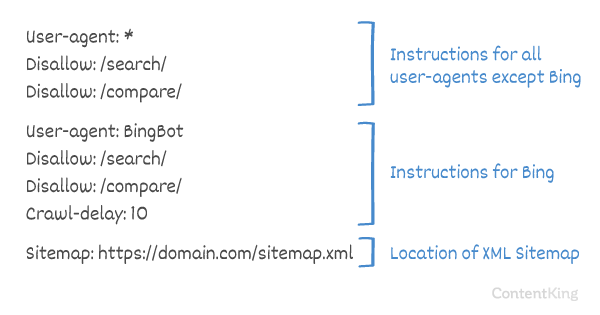
Måden, hvormed søgemaskiner håndterer Crawl-delay er forskellig. Nedenfor forklarer vi, hvordan store søgemaskiner håndterer det.
Crawl-delay og Google
Googles webcrawler, Googlebot, understøtter ikke Crawl-delay direktivet, så gider ikke med at definere en Google-gennemgangsforsinkelse.
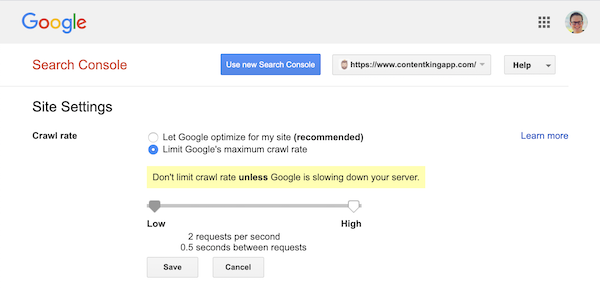
Google understøtter dog defineringen af en gennemgangshastighed (eller “anmodningshastighed”, hvis du vil ) i Google Search Console.
- Log ind på den gamle Google Search Console.
- Vælg det websted, du ønsker at definere gennemsøgningshastigheden for.
- Der er kun en indstilling, du kan tilpasse:
Crawl ratemed en skyder, hvor du kan indstille den foretrukne gennemgangshastighed. Som standard gennemgangshastigheden er indstillet til “Lad Google optimere til mit websted (anbefales)”.
Sådan ser det ud i Google Search Console:
Crawl-delay og Bing, Yahoo og Yandex
Bing, Yahoo og Yandex alle støtter Crawl-delay direktiv om gashåndtering af et websted. Deres fortolkning af gennemsøgningsforsinkelsen er dog lidt anderledes, så sørg for at tjekke deres dokumentation:
- Bing og Yahoo
- Yandex
Direktivet Crawl-delay skal placeres lige efter Disallow eller Allow direktiverne.
Eksempel:
Crawl-delay og Baidu
Baidu understøtter ikke crawl-delay direktivet, men det er muligt at registrere en Baidu Webmaster Tools-konto i som du kan kontrollere gennemgangsfrekvensen svarende til Google Search Console.
Hvornår skal du bruge en robots.txt-fil?
Vi anbefaler altid at bruge en robots.txt-fil. Der er absolut ingen skade ved at have en, og det er et godt sted at give søgemaskiner direktiver om, hvordan de bedst kan gennemgå dit websted.

Robotten.txt kan være nyttig til at forhindre, at bestemte områder eller dokumenter på dit websted bliver gennemgået og indekseret. Eksempler er f.eks. Iscenesættelsesstedet eller PDF-filer. Planlæg nøje, hvad der skal indekseres af søgemaskiner, og vær opmærksom på, at indhold, der er gjort utilgængeligt gennem robots.txt, stadig kan findes af søgemaskine-crawlere, hvis det er linket til fra andre områder af webstedet.
Robots.txt bedste fremgangsmåder
De bedste fremgangsmåder ved robots.txt er kategoriseret som følger:
- Placering og filnavn
- Forrangsrækkefølge
- Kun en gruppe direktiver pr. Robot
- Vær så specifik som muligt
- Direktiver for alle robotter, mens du også inkluderer direktiver for en specifik robot
- Robots.txt-fil for hvert (under) domæne.
- Modstridende retningslinjer: robots.txt vs. Google Search Console
- Overvåg din robots.txt-fil
- Brug ikke noindex i din robots.txt
- Forhindre UTF-8 BOM i robots.txt-fil
Placering og filnavn
Robotten.txt-filen skal altid placeres i th e root på et websted (i værtens topkatalog) og bære filnavnet robots.txt, for eksempel: . Bemærk, at URL-adressen til robots.txt-filen er som enhver anden URL store og små bogstaver.
Hvis robots.txt-filen ikke kan findes på standardplaceringen, antager søgemaskinerne, at der ikke er nogen direktiver og kravler væk på dit websted.
Forrangsrækkefølge
Det er vigtigt at bemærke, at søgemaskiner håndterer robots.txt-filer forskelligt. Som standard vinder det første matchende direktiv altid.
Men med Google og Bing-specificitet vinder det. For eksempel: et Allow -direktiv vinder et Disallow -direktiv, hvis dets tegnlængde er længere.
Eksempel
I eksempel over alle søgemaskiner, inklusive Google og Bing, har ikke adgang til /about/ -mappen, undtagen underkatalogen /about/company/.
Eksempel
I eksemplet ovenfor har alle søgemaskiner undtagen Google og Bing ikke adgang til /about/ -mappen. Dette inkluderer biblioteket /about/company/.
Google og Bing har adgang, fordi Allow -direktivet er længere end direktivet Disallow direktiv.
Kun en gruppe direktiver pr. robot
Du kan kun definere en gruppe direktiver pr. søgemaskine. At have flere grupper af direktiver for en søgemaskine forvirrer dem.
Vær så specifik som muligt
Disallow -direktivet udløser på delvise matches som godt. Vær så specifik som muligt, når du definerer Disallow -direktivet for at forhindre utilsigtet ikke at give adgang til filer.
Eksempel:
Eksemplet ovenfor tillader ikke søgemaskiner adgang til:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Direktiver for alle robotter, mens de også inkluderer direktiver for en specifik robot
For en robot kun en gruppe direktiver er gyldige. Hvis direktiver beregnet til alle robotter følges med direktiver for en specifik robot, vil kun disse specifikke direktiver blive taget i betragtning. For at den specifikke robot også skal følge direktiverne for alle robotter, skal du gentage disse direktiver for den specifikke robot.
Lad os se på et eksempel, der gør dette klart:
Eksempel
Hvis du ikke ønsker, at googlebot skal få adgang til /secret/ og /not-launched-yet/, skal du gentage disse direktiver for googlebot specifikt:
Bemærk, at din robots.txt-fil er offentligt tilgængelig. At ikke tillade websidesektioner derinde kan bruges som en angrepsvektor af mennesker med ondsindet hensigt.

Robots.txt kan være farligt. Du fortæller ikke kun søgemaskiner, hvor du ikke vil have dem til at se, du fortæller folk, hvor du skjuler dine beskidte hemmeligheder.
Robots.txt-fil for hvert (under) domæne
Kun Robots.txt-direktiver gælder for det (under) domæne, filen er hostet på.
Eksempler
er gyldig for , men ikke til eller
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Vi har bygget robots.txt-ændringssporing og alarmering af denne grund.
Vi ser det hele tiden: robots.txt-filer ændres uden kendskab til digital markedsføring hold. Vær ikke den person. Start med at overvåge din robots.txt-fil, og modtag alarmer, når den ændres!
Brug ikke noindex i din robots.txt
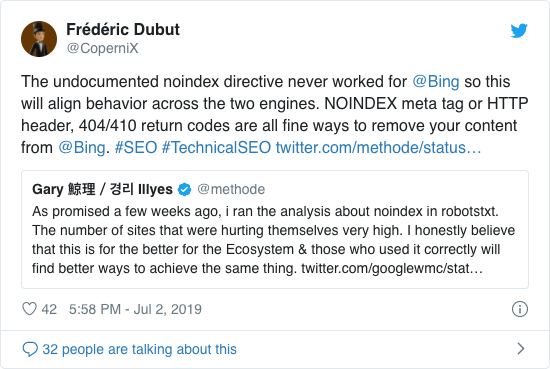
I årevis anbefalede Google allerede åbent at bruge det uofficielle noindex-direktiv. Fra den 1. september 2019 holdt Google dog op med at støtte det helt.
Det uofficielle noindex-direktiv fungerede aldrig i Bing, som bekræftet af Frédéric Dubut i dette tweet:
Den bedste måde at signalere til søgemaskiner om, at sider ikke skal indekseres, er at bruge meta-robots-tagget eller X-Robots-Tag .
Forhindre UTF-8 BOM i robots.txt-fil
BOM står for byte-ordremærke, en usynlig karakter i begyndelsen af en fil, der bruges til at angive Unicode-kodning af en tekstfil.
Mens Google siger, at de ignorerer det valgfri Unicode-byteordermærke i begyndelsen af robots.txt-filen, anbefaler vi at forhindre “UTF-8 BOM”, fordi vi har set det forårsage problemer med fortolkningen af robots.txt-filen fra søgemaskiner.
Selvom Google siger, at de kan håndtere det, er der to grunde til at forhindre UTF-8 BOM:
- Du don Du vil ikke have nogen tvetydighed omkring dine præferencer omkring gennemsøgning til søgemaskiner.
- Der er andre søgemaskiner derude, som måske ikke er så tilgivende som Google hævder at være.
Eksempler på Robots.txt
I dette kapitel dækker vi en lang række eksempler på robots.txt-filer:
- Tillad alle robotter adgang til alt
- Tillad alle robotter adgang til alt
- Alle Google-bots har ikke adgang
- Alle Google-bots undtagen Googlebot-nyheder har ikke adgang
- Googlebot og Slurp har ingen adgang
- Alle robotter har ikke adgang til to kataloger
- Alle robotter har ikke adgang til en bestemt fil
- Googlebot har ikke adgang til / admin / og Slurp har ikke adgang til / private /
- Robots.txt-fil til WordPress
- Robots.txt-fil til Magento
Giv alle robotter adgang til alt
Der er flere måder for at fortælle søgemaskiner, at de kan få adgang til alle filer:
Eller have en tom robots.txt-fil eller slet ikke have en robots.txt.
Tillad alle robotter adgang til alt
Eksemplet robots.txt nedenfor fortæller alle søgemaskiner, at de ikke skal få adgang til hele webstedet:
Bemærk, at kun ET ekstra tegn kan gøre hele forskellen.
Alle Google-bots har ikke adgang
Bemærk, at når du ikke tillader Googlebot, gælder dette for alle Googlebots. Dette inkluderer Google-robotter, der f.eks. Søger efter nyheder (googlebot-news) og billeder (googlebot-images).
Alle Google-bots bortset fra Googlebot-nyheder har ikke adgang
Googlebot og Slurp har ingen adgang
Alle robotter har ikke adgang til to mapper
Alle robotter har ikke adgang til en bestemt fil
Googlebot har ikke adgang til / admin / og Slurp har ikke adgang til / private /
Robots.txt fil til WordPress
Robotten.txt-filen nedenfor er specifikt optimeret til WordPress, forudsat:
- Du vil ikke have din administratorafdeling, der skal gennemgås.
- Du vil ikke have dine interne søgeresultatsider gennemsøgt.
- Du vil ikke have dine tag- og forfattersider gennemgået.
- Du don ‘ t ønsker, at din 404-side skal crawles.
Bemærk, at denne robots.txt-fil fungerer i de fleste tilfælde, men du skal altid justere den og teste den for at sikre, at den gælder for din nøjagtig situation.
Robots.txt-fil til Magento
Robotten.txt-filen nedenfor er specifikt optimeret til Magento og giver interne søgeresultater, login-sider, sessionsidentifikatorer og filtreret resultat sæt, der indeholder price, color, material og size kriterier utilgængelige for crawlere.
Bemærk, at denne robots.txt-fil fungerer i de fleste Magento-butikker, men du bør altid justere det og teste det for at sikre, at det gælder din nøjagtige situation.
Jeg vil stadig altid se efter at blokere interne søgeresultater i robots.txt på ethvert websted, fordi disse typer søge-URL’er er uendelige og uendelige. Der er meget potentiale for, at Googlebot kommer i en crawlerfælde.
Hvad er begrænsningerne i robots.txt-filen?
Robots.txt-filen indeholder direktiver
Selvom robots.txt respekteres godt ved søgning motorer, er det stadig et direktiv og ikke et mandat.
Sider, der stadig vises i søgeresultater
Sider, der er utilgængelige for søgemaskiner på grund af robotterne.txt, men har links til dem kan stadig vises i søgeresultaterne, hvis de linkes fra en side, der er gennemgået. Et eksempel på hvordan dette ser ud:

Det er muligt at fjerne disse webadresser fra Google ved hjælp af Google Search Consoles værktøj til fjernelse af webadresser. Bemærk, at disse webadresser kun “skjules” midlertidigt. For at de kan forblive ude af Googles resultatsider, skal du indsende en anmodning om at skjule webadresserne hver 180. dag.

Brug robots.txt til at blokere for uønskede og sandsynligvis skadelige tilknyttede backlinks. ikke bruge robots.txt i et forsøg på at forhindre indhold i at blive indekseret af søgemaskiner, da dette uundgåeligt mislykkes. Anvend i stedet robottedirektiv noindex når det er nødvendigt.
Robots.txt-filen er cache i op til 24 timer
Google har angivet, at en robot .txt-fil er generelt cachelagret i op til 24 timer. Det er vigtigt at tage dette i betragtning, når du foretager ændringer i din robots.txt-fil.
Det er uklart, hvordan andre søgemaskiner håndterer caching af robots.txt , men generelt er det bedst at undgå at cache din robots.txt-fil til av oid-søgemaskiner tager længere tid end nødvendigt for at kunne hente ændringer.
Robots.txt-filstørrelse
For robots.txt-filer understøtter Google i øjeblikket en filstørrelsesgrænse på 500 kibibytes (512 kilobyte). Alt indhold efter denne maksimale filstørrelse kan ignoreres.
Det er uklart, om andre søgemaskiner har en maksimal filstørrelse til robots.txt-filer.
Ofte stillede spørgsmål om robots.txt
🤖 Hvordan ser et robots.txt-eksempel ud?
Her er et eksempel på et robots.txt-indhold: User-agent: * Disallow:. Dette fortæller alle webcrawlere, at de kan få adgang til alt.
⛔ Hvad tillader ikke alle at gøre i robots.txt?
Når du indstiller en robots.txt til “Tillad alle”, er du fortæller i det væsentlige alle crawlere at holde sig ude. Ingen crawlere, inklusive Google, har adgang til dit websted. Dette betyder, at de ikke vil være i stand til at gennemgå, indeksere og rangere dit websted. Dette vil føre til et massivt fald i organisk trafik.
✅ Hvad gør Tillad, at alle gør i robots.txt?
Når du indstiller en robots.txt til “Tillad alle”, fortæller du enhver webcrawler, at de kan få adgang til hver URL på webstedet. Der er simpelthen ingen regler for engagement. Bemærk, at dette svarer til at have en tom robots.txt eller slet ikke have nogen robots.txt.
🤔 Hvor vigtig er robots.txt for SEO?
I generelt er robots.txt-filen meget vigtig til SEO-formål. For større websteder er robots.txt afgørende for at give søgemaskiner meget klare instruktioner om, hvilket indhold der ikke er adgang til.