La función de ventana ROW_NUMBER tiene numerosas aplicaciones prácticas, mucho más allá de las obvias necesidades de clasificación. La mayoría de las veces, cuando calcula números de fila, necesita calcularlos en función de algún orden y proporciona la especificación de orden deseada en la cláusula de orden de ventana de la función. Sin embargo, hay casos en los que es necesario calcular los números de fila sin ningún orden en particular; en otras palabras, basado en un orden no determinista. Esto podría ocurrir en todo el resultado de la consulta o dentro de las particiones. Los ejemplos incluyen la asignación de valores únicos a las filas de resultados, la deduplicación de datos y la devolución de cualquier fila por grupo.
Tenga en cuenta que la necesidad de asignar números de fila según un orden no determinista es diferente a la necesidad de asignarlos según un orden aleatorio. Con el primero, no le importa en qué orden se asignan y si las ejecuciones repetidas de la consulta siguen asignando los mismos números de fila a las mismas filas o no. Con este último, espera que las ejecuciones repetidas sigan cambiando qué filas se asignan con qué números de fila. Este artículo explora diferentes técnicas para calcular números de fila con orden no determinista. La esperanza es encontrar una técnica que sea confiable y óptima.
¡Un agradecimiento especial a Paul White por el consejo sobre el plegado constante, por la técnica de tiempo de ejecución constante y por ser siempre una gran fuente de información!
Cuando el orden importa
Comenzaré con casos en los que el orden del número de fila sí importa.
Usaré una tabla llamada T1 en mis ejemplos. Utilice el siguiente código para crear esta tabla y completarla con datos de muestra:
Considere la siguiente consulta (la llamaremos Consulta 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Aquí desea que se asignen números de fila dentro de cada grupo identificado por la columna grp, ordenados por la columna datacol. Cuando ejecuté esta consulta en mi sistema, obtuve el siguiente resultado:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Los números de fila se asignan aquí en un orden parcialmente determinista y parcialmente no determinista. Lo que quiero decir con esto es que tiene la seguridad de que dentro de la misma partición, una fila con un valor de columna de datos mayor obtendrá un valor de número de fila mayor. Sin embargo, dado que datacol no es único dentro de la partición grp, el orden de asignación de números de fila entre filas con los mismos valores de grp y datacol no es determinista. Tal es el caso de las filas con los valores de identificación 2 y 11. Ambas tienen el valor de grp A y el valor de columna de datos 50. Cuando ejecuté esta consulta en mi sistema por primera vez, la fila con la identificación 2 obtuvo la fila número 2 y el la fila con la identificación 11 obtuvo la fila número 3. No importa la probabilidad de que esto suceda en la práctica en SQL Server; si vuelvo a ejecutar la consulta, teóricamente, la fila con la identificación 2 podría asignarse con la fila número 3 y la fila con la identificación 11 podría asignarse con la fila número 2.
Si necesita asignar números de fila basados en un orden completamente determinista, garantizando resultados repetibles en las ejecuciones de la consulta siempre que los datos subyacentes no cambien, necesita que la combinación de elementos en las cláusulas de ordenación y partición de ventanas sea única. Esto podría lograrse en nuestro caso agregando el ID de la columna a la cláusula de orden de ventana como un desempate. La cláusula OVER sería entonces:
OVER (PARTITION BY grp ORDER BY datacol, id)
En cualquier caso, cuando se calculan los números de fila en función de alguna especificación de orden significativa como en la Consulta 1, SQL Server necesita procesar el filas ordenadas por la combinación de elementos de ordenación y división de ventanas. Esto se puede lograr extrayendo los datos preordenados de un índice o clasificando los datos. Por el momento, no hay un índice en T1 que admita el cálculo ROW_NUMBER en la Consulta 1, por lo que SQL Server tiene que optar por ordenar los datos. Esto se puede ver en el plan para la Consulta 1 que se muestra en la Figura 1.
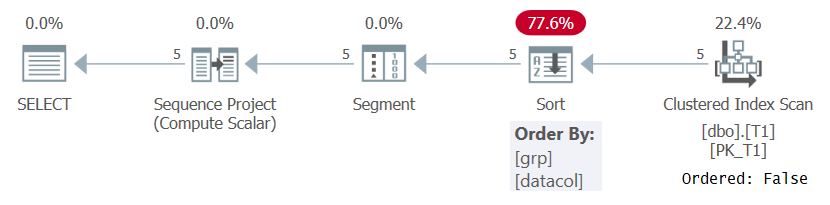 Figura 1: Plan para la Consulta 1 sin un índice de apoyo
Figura 1: Plan para la Consulta 1 sin un índice de apoyo
Observe que el plan escanea los datos del índice agrupado con una propiedad Ordered: False. Esto significa que el escaneo no necesita devolver las filas ordenadas por la clave de índice. Ese es el caso, ya que el índice agrupado se usa aquí solo porque cubre la consulta y no debido a su orden de claves. Luego, el plan aplica una clasificación, lo que genera un costo adicional, una escala de N Log N y un retraso en el tiempo de respuesta. El operador de segmento produce una bandera que indica si la fila es la primera en la partición o no. Por último, el operador Proyecto de secuencia asigna números de fila que comienzan con 1 en cada partición.
Si desea evitar la necesidad de ordenar, puede preparar un índice de cobertura con una lista de claves que se base en los elementos de partición y ordenación, y una lista de inclusión basada en los elementos de cobertura.Me gusta pensar en este índice como un índice POC (para particionar, ordenar y cubrir). Aquí está la definición del POC que apoya nuestra consulta:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Ejecute la Consulta 1 de nuevo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
El plan para esta ejecución se muestra en la Figura 2.
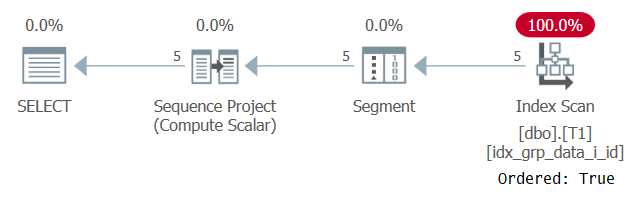 Figura 2: Plan para la Consulta 1 con un índice POC
Figura 2: Plan para la Consulta 1 con un índice POC
Observe que esta vez el plan escanea el índice POC con una propiedad Ordered: True. Esto significa que el escaneo garantiza que las filas se devolverán en el orden de clave de índice. Dado que los datos se extraen preordenados del índice como lo necesita la función de ventana, no hay necesidad de una clasificación explícita. La escala de este plan es lineal y el tiempo de respuesta es bueno.
Cuando el orden no importa
Las cosas se complican un poco cuando necesitas asignar números de fila con un número completamente no determinista orden. Lo natural que se quiere hacer en tal caso es usar la función ROW_NUMBER sin especificar una cláusula de orden de ventana. Primero, verifiquemos si el estándar SQL permite esto. Aquí está la parte relevante del estándar que define las reglas de sintaxis para ventana funciones:
Observe que el elemento 6 enumera las funciones < ntile function >, < función de adelanto o retraso >, < tipo de función de rango > o ROW_NUMBER, y luego el elemento 6a dice que para las funciones < ntile function >, < función de adelanto o retraso >, RANK o DENSE_RANK la cláusula de orden de ventana debe b e presente. No hay un lenguaje explícito que indique si ROW_NUMBER requiere una cláusula de orden de ventana o no, pero la mención de la función en el elemento 6 y su omisión en 6a podría implicar que la cláusula es opcional para esta función. Es bastante obvio por qué funciones como RANK y DENSE_RANK requerirían una cláusula de orden de ventana, ya que estas funciones se especializan en el manejo de vínculos, y los vínculos solo existen cuando hay una especificación de pedido. Sin embargo, ciertamente podría ver cómo la función ROW_NUMBER podría beneficiarse de una cláusula de orden de ventana opcional.
Entonces, intentémoslo e intentemos calcular números de fila sin orden de ventana en SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Este intento da como resultado el siguiente error:
La función «ROW_NUMBER» debe tener una cláusula OVER con ORDER BY.
De hecho, si comprueba la documentación de SQL Server de la función ROW_NUMBER, encontrará el siguiente texto:
El ORDER La cláusula BY determina la secuencia en la que se asigna a las filas su ROW_NUMBER único dentro de una partición especificada. Es obligatorio ”.
Por lo tanto, aparentemente la cláusula de orden de ventana es obligatoria para la función ROW_NUMBER en SQL Server . Ese también es el caso en Oracle, por cierto.
Tengo que decir que no estoy seguro de entender el motivo. ng detrás de este requisito. Recuerde que está permitiendo definir números de fila basados en un orden parcialmente no determinista, como en la Consulta 1. Entonces, ¿por qué no permitir el no determinismo hasta el final? Quizás haya alguna razón en la que no estoy pensando. Si puede pensar en una razón así, por favor comparta.
En cualquier caso, podría argumentar que si no le importa el orden, dado que la cláusula de orden de ventana es obligatoria, puede especificar cualquier orden. El problema con este enfoque es que si ordena por alguna columna de la (s) tabla (s) consultadas, esto podría implicar una penalización de rendimiento innecesaria. Cuando no existe un índice de respaldo, pagará por una clasificación explícita. Cuando existe un índice compatible, está limitando el motor de almacenamiento a una estrategia de escaneo de orden de índice (siguiendo la lista vinculada al índice). No le permite más flexibilidad como suele tener cuando el orden no importa al elegir entre un escaneo de orden de índice y un escaneo de orden de asignación (basado en páginas de IAM).
Una idea que vale la pena intentar es especificar una constante, como 1, en la cláusula de orden de ventana. Si es compatible, es de esperar que el optimizador sea lo suficientemente inteligente como para darse cuenta de que todas las filas tienen el mismo valor, por lo que no hay una relevancia de orden real y, por lo tanto, no es necesario forzar una clasificación o un análisis de orden de índice. Aquí hay una consulta que intenta este enfoque:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Desafortunadamente, SQL Server no es compatible con esta solución. Genera el siguiente error:
Las funciones en ventana, los agregados y las funciones NEXT VALUE FOR no admiten índices enteros como expresiones de cláusula ORDER BY.
Aparentemente, SQL Server asume que si está usando una constante entera en la cláusula de orden de ventana, representa una posición ordinal de un elemento en la lista SELECT, como cuando especifica un número entero en la presentación ORDER BY cláusula. Si ese es el caso, otra opción que vale la pena intentar es especificar una constante no entera, así:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Resulta que esta solución tampoco es compatible. SQL Server genera el siguiente error:
Las funciones con ventana, los agregados y las funciones NEXT VALUE FOR no admiten constantes como expresiones de cláusula ORDER BY.
Aparentemente, la cláusula de orden de ventana no admite ningún tipo de constante.
Hasta ahora hemos aprendido lo siguiente sobre la relevancia del orden de ventana de la función ROW_NUMBER en SQL Server:
- ORDER BY es obligatorio.
- No se puede ordenar por una constante entera ya que SQL Server cree que está tratando de especificar una posición ordinal en SELECT.
- No se puede ordenar por cualquier tipo de constante.
La conclusión es que se supone que debe ordenar por expresiones que no son constantes. Obviamente, puede ordenar por una lista de columnas de las tablas consultadas. Pero estamos en una búsqueda para encontrar una solución eficiente donde el optimizador pueda darse cuenta de que no hay relevancia para ordenar.
Plegado constante
La conclusión hasta ahora es que no se pueden usar constantes en la La cláusula de orden de ventana de ROW_NUMBER, pero ¿qué pasa con las expresiones basadas en constantes, como en la siguiente consulta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Sin embargo, este intento es víctima de un proceso conocido como constante plegable, que normalmente tiene un impacto positivo en el rendimiento de las consultas. La idea detrás de esta técnica es mejorar el rendimiento de la consulta al plegar alguna expresión basada en constantes a sus constantes de resultado en una etapa temprana del procesamiento de la consulta. Puede encontrar detalles sobre qué tipos de expresiones se pueden plegar constantemente aquí. Nuestra expresión 1 + 0 se dobla a 1, lo que da como resultado el mismo error que obtuviste al especificar la constante 1 directamente:
Funciones en ventana, Los agregados y las funciones NEXT VALUE FOR no admiten índices enteros como expresiones de cláusula ORDER BY.
Se enfrentaría a una situación similar al intentar concatenar dos cadenas de caracteres literales, así:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Obtiene el mismo error que obtuvo al especificar el literal «Sin orden» directamente:
Windowed las funciones, los agregados y las funciones NEXT VALUE FOR no admiten constantes como expresiones de cláusula ORDER BY.
Mundo extraño: errores que evitan errores
La vida está llena de sorpresas…
Una cosa que evita el plegado constante es cuando la expresión normalmente resultaría en un error. Por ejemplo, la expresión 2147483646 + 1 se puede plegar constantemente, ya que da como resultado un valor válido con tipo INT. En consecuencia, un intento de ejecutar la siguiente consulta falla:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Funciones en ventana, agregados y SIGUIENTE VALOR Las funciones FOR no admiten índices enteros como expresiones de cláusula ORDER BY.
Sin embargo, la expresión 2147483647 + 1 no se puede plegar de forma constante porque tal intento habría resultado en un error de desbordamiento INT. La implicación en el pedido es bastante interesante. Pruebe la siguiente consulta (a esta la llamaremos Consulta 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
¡Curiosamente, esta consulta se ejecuta correctamente! Lo que pasa es que, por un lado, SQL Server no aplica el plegado constante y, por tanto, el ordenamiento se basa en una expresión que no es una única constante. Por otro lado, el optimizador calcula que el valor de orden es el mismo para todas las filas, por lo que ignora la expresión de orden por completo. Esto se confirma al examinar el plan para esta consulta como se muestra en la Figura 3.
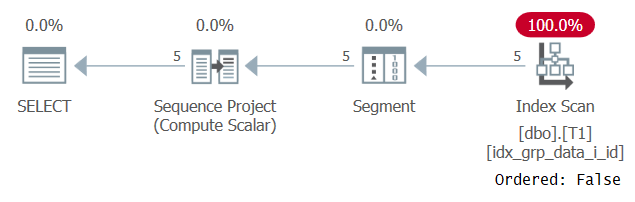 Figura 3: Plan para la Consulta 2
Figura 3: Plan para la Consulta 2
Observe que el plan escanea algún índice de cobertura con una propiedad Ordered: False. Este era exactamente nuestro objetivo de rendimiento.
De manera similar, la siguiente consulta implica un intento de plegado constante exitoso y, por lo tanto, falla:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Las funciones en ventana, los agregados y las funciones NEXT VALUE FOR no admiten índices enteros como expresiones de cláusula ORDER BY.
La siguiente consulta implica un intento fallido de plegado constante y, por lo tanto, tiene éxito, generando el plan mostrado anteriormente en la Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Lo siguiente La consulta implica un intento de plegado constante exitoso (VARCHAR literal «1» se convierte implícitamente en INT 1, y luego 1 + 1 se dobla a 2) y, por lo tanto, falla:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Las funciones en ventana, los agregados y las funciones NEXT VALUE FOR no admiten índices enteros como expresiones de cláusula ORDER BY.
La siguiente consulta implica una intento fallido de plegado constante (no se puede convertir «A» a INT), y por lo tanto tiene éxito, generando el plan que se muestra anteriormente en la Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Para ser honesto, aunque esta técnica extraña logra nuestro objetivo de rendimiento original, no puedo decir que la considere segura y, por lo tanto, no me siento tan cómodo confiando en ella.
Constantes de tiempo de ejecución basadas en funciones
Continuando con la búsqueda de una buena solución para calcular números de fila con orden no determinista, hay algunas técnicas que parecen más seguras que la última solución peculiar: usar constantes de tiempo de ejecución basadas en funciones, usar una subconsulta basada en una constante, usar una columna con alias basada en una constante y usando una variable.
Como explico en T-SQL errores, trampas y mejores prácticas: determinismo, la mayoría de las funciones en T-SQL se evalúan solo una vez por referencia en la consulta, no una vez por fila. Este es el caso incluso con la mayoría de funciones no deterministas como GETDATE y RAND. Hay muy pocas excepciones a esta regla, como las funciones NEWID y CRYPT_GEN_RANDOM, que se evalúan una vez por fila. La mayoría de las funciones, como GETDATE, @@ SPID y muchas otras, se evalúan una vez al comienzo de la consulta y sus valores se consideran constantes de tiempo de ejecución. Una referencia a tales funciones no se dobla constantemente. Estas características hacen que una constante de tiempo de ejecución basada en una función sea una buena elección como elemento de ordenación de ventanas y, de hecho, parece que T-SQL la admite. Al mismo tiempo, el optimizador se da cuenta de que, en la práctica, no hay relevancia para ordenar, lo que evita penalizaciones de rendimiento innecesarias.
Aquí hay un ejemplo con la función GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Esta consulta obtiene el mismo plan mostrado anteriormente en la Figura 3.
Aquí hay otro ejemplo usando la función @@ SPID (devolviendo el ID de sesión actual):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
¿Qué pasa con la función PI? Pruebe la siguiente consulta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Este falla con el siguiente error:
Las funciones en ventana, los agregados y las funciones NEXT VALUE FOR no admiten constantes como expresiones de cláusula ORDER BY.
Las funciones como GETDATE y @@ SPID se reevalúan una vez por ejecución del plan, por lo que no pueden obtener doblado constante. PI representa la misma constante siempre y, por lo tanto, se dobla constantemente.
Como se mencionó anteriormente, hay muy pocas funciones que se evalúen una vez por fila, como NEWID y CRYPT_GEN_RANDOM. Esto los convierte en una mala elección como elemento de ordenación de ventanas si necesita un orden no determinista, no confundir con el orden aleatorio. ¿Por qué pagar una multa de clasificación innecesaria?
Aquí hay un ejemplo usando la función NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
El plan para esta consulta se muestra en la Figura 4, confirmando que SQL Server agregó explícitamente ordenación según el resultado de la función.
 Figura 4: Plan para la consulta 3
Figura 4: Plan para la consulta 3
Si desea que se asignen los números de fila en orden aleatorio, por supuesto, esa es la técnica que desea utilizar. Solo debe tener en cuenta que incurre en el costo de clasificación.
Uso de una subconsulta
También puede usar una subconsulta basada en una constante como expresión de orden de ventana (por ejemplo, ORDER BY (SELECCIONE «Sin pedido»)). Además, con esta solución, el optimizador de SQL Server reconoce que no hay relevancia de ordenamiento y, por lo tanto, no impone una ordenación innecesaria ni limita las opciones del motor de almacenamiento a aquellas que deben garantizar el orden. Intente ejecutar la siguiente consulta como ejemplo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Obtienes el mismo plan que se mostró anteriormente en la Figura 3.
Uno de los grandes beneficios de esta técnica es que puedes agregar tu propio toque personal.Quizás te gusten mucho los NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Tal vez realmente te guste cierto número:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Tal vez quieras enviarle un mensaje a alguien:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Entiendes el punto.
Es factible, pero incómodo
Hay un par de técnicas que funcionan, pero son un poco incómodas. Una es definir un alias de columna para una expresión basada en una constante y luego usar ese alias de columna como el elemento de orden de la ventana. Puede hacer esto usando una expresión de tabla o con el operador CROSS APPLY y un constructor de valor de tabla. Aquí hay un ejemplo para este último:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Obtiene el mismo plan que se mostró anteriormente en la Figura 3.
Otra opción es usar una variable como elemento de orden de la ventana:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Esta consulta también obtiene el plan que se mostró anteriormente en la Figura 3.
¿Qué sucede si uso mi propia UDF? ?
Podría pensar que usar su propia UDF que devuelve una constante podría ser una buena elección como elemento de orden de ventana cuando desee un orden no determinista, pero no lo es. Considere la siguiente definición de UDF como ejemplo:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Intente usar la UDF como la cláusula de ordenación de ventanas, así (llamaremos a esta consulta 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Antes de SQL Server 2019 (o nivel de compatibilidad paralelo < 150), las funciones definidas por el usuario se evalúan por fila . Incluso si devuelven una constante, no se alinean. En consecuencia, por un lado, puede utilizar una UDF como elemento de ordenación de ventanas, pero por otro lado, esto da como resultado una penalización de clasificación. Esto se confirma al examinar el plan para esta consulta, como se muestra en la Figura 5.
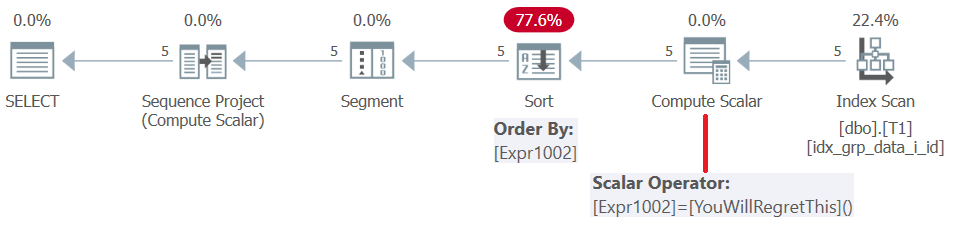 Figura 5: Plan para la Consulta 4
Figura 5: Plan para la Consulta 4
A partir de SQL Server 2019, en el nivel de compatibilidad > = 150, estas funciones definidas por el usuario se integran, lo que es algo muy bueno, pero en nuestro caso da como resultado un error:
Las funciones en ventana, los agregados y las funciones NEXT VALUE FOR no admiten constantes como expresiones de cláusula ORDER BY.
Por lo tanto, el uso de una UDF basada en una constante como elemento de orden de la ventana fuerza una clasificación o un error según la versión de SQL Server que esté utilizando y el nivel de compatibilidad de su base de datos. En resumen, no haga esto.
Números de fila particionados con orden no determinista
Un caso de uso común para números de fila particionados basados en orden no determinista es devolver cualquier fila por grupo. Dado que, por definición, existe un elemento de partición en este escenario, pensaría que una técnica segura en tal caso sería utilizar el elemento de partición de ventana también como elemento de ordenación de ventana. Como primer paso, calcula los números de fila así:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
El plan para esta consulta se muestra en la Figura 6.
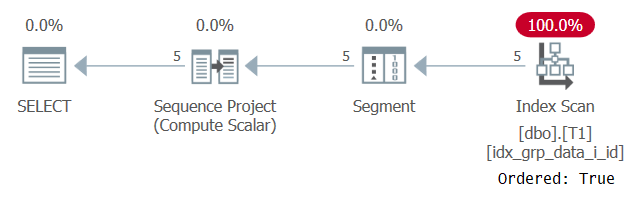 Figura 6: Plan para la consulta 5
Figura 6: Plan para la consulta 5
La razón por la que nuestro índice de apoyo se escanea con una propiedad Ordered: True es porque SQL Server necesita procesar las filas de cada partición como un Unidad singular. Ese es el caso antes del filtrado. Si filtra solo una fila por partición, tiene como opciones algoritmos basados en orden y hash.
El segundo paso es colocar la consulta con el cálculo del número de fila en una expresión de tabla, y en la consulta externa filtra la fila con la fila número 1 en cada partición, así:
Teóricamente se supone que esta técnica es segura, pero Paul White encontró un error que muestra que usando este método puedes obtener atributos de diferentes filas de origen en la fila de resultados devueltos por partición. Usar una constante de tiempo de ejecución basada en una función o una subconsulta basada en una constante, ya que el elemento de orden parece ser seguro incluso con este escenario, así que asegúrese de usar una solución como la siguiente en su lugar:
Nadie pasará de esta manera sin mi permiso
Tratar de calcular los números de fila basándose en un orden no determinista es una necesidad común. Hubiera sido bueno si T-SQL simplemente hiciera opcional la cláusula de orden de ventana para la función ROW_NUMBER, pero no es así. De lo contrario, habría sido bueno si al menos permitiera el uso de una constante como elemento de pedido, pero esa tampoco es una opción compatible.Pero si lo solicita amablemente, en forma de una subconsulta basada en una constante o una constante de tiempo de ejecución basada en una función, SQL Server lo permitirá. Estas son las dos opciones con las que me siento más cómodo. Realmente no me siento cómodo con las extravagantes expresiones erróneas que parecen funcionar, así que no puedo recomendar esta opción.