A robots El archivo .txt contiene directivas para motores de búsqueda. Puede usarlo para evitar que los motores de búsqueda rastreen partes específicas de su sitio web y para brindarles consejos útiles sobre cómo pueden rastrear mejor su sitio web. El archivo robots.txt juega un papel importante en SEO.
Al implementar robots.txt, tenga en cuenta las siguientes prácticas recomendadas:
- Tenga cuidado al realizar cambios en su robots.txt: este archivo tiene el potencial de hacer que gran parte de su sitio web sea inaccesible para los motores de búsqueda.
- El archivo robots.txt debe residir en la raíz de su sitio web (p. ej.,
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpohttps). - Los diferentes motores de búsqueda interpretan las directivas de manera diferente. De forma predeterminada, la primera directiva coincidente siempre gana. Pero, con Google y Bing, gana la especificidad.
- Evite usar la directiva de retraso de rastreo para los motores de búsqueda tanto como sea posible.
¿Qué es un ¿Archivo robots.txt?
Un archivo robots.txt le dice a los motores de búsqueda cuáles son las reglas de interacción de su sitio web. Una gran parte de hacer SEO consiste en enviar las señales correctas a los motores de búsqueda, y el archivo robots.txt es una de las formas de comunicar sus preferencias de rastreo a los motores de búsqueda.
En 2019, hemos visto bastante algunos desarrollos en torno al estándar robots.txt: Google propuso una extensión para el Protocolo de exclusión de robots y abrió su analizador de robots.txt de código abierto.
TL; DR
- Los robots de Google El intérprete de .txt es bastante flexible y sorprendentemente indulgente.
- En caso de directivas de confusión, Google se equivoca y asume que las secciones deben estar restringidas en lugar de irrestrictas.
Los motores de búsqueda revisan periódicamente el archivo robots.txt de un sitio web para ver si hay instrucciones para rastrear el sitio web. A estas instrucciones las denominamos directivas.
Si no hay un archivo robots.txt presente o si no hay directivas aplicables, los motores de búsqueda rastrearán todo el sitio web.
Aunque todos los principales motores de búsqueda respetan el archivo robots.txt, los motores de búsqueda pueden optar por ignorar (partes de) su archivo robots.txt. Si bien las directivas en el archivo robots.txt son una señal sólida para los motores de búsqueda, es importante recordar que el archivo robots.txt es un conjunto de directivas opcionales para los motores de búsqueda en lugar de un mandato.

El archivo robots.txt es el archivo más sensible del universo SEO. Un solo carácter puede romper todo un sitio.
Terminología sobre el archivo robots.txt
El archivo robots.txt es la implementación del estándar de exclusión de robots, o también llamado el protocolo de exclusión de robots.
¿Por qué debería preocuparte por robots.txt?
El robots.txt juega un papel fundamental desde el punto de vista de SEO. Le dice a los motores de búsqueda cómo pueden rastrear mejor su sitio web.
Con el archivo robots.txt, puede evitar que los motores de búsqueda accedan a ciertas partes de su sitio web, evitar el contenido duplicado y brindar a los motores de búsqueda consejos útiles sobre cómo puede rastrear su sitio web de manera más eficiente.
Sin embargo, tenga cuidado al realizar cambios en su archivo robots.txt: este archivo tiene el potencial de hacer que gran parte de su sitio web sea inaccesible para los motores de búsqueda.

Robots.txt a menudo se usa en exceso para reducir el contenido duplicado, por lo que matando los enlaces internos, así que ten mucho cuidado con eso. Mi consejo es que lo use solo para archivos o páginas que los motores de búsqueda nunca deberían ver, o que pueden afectar significativamente el rastreo si se les permite ingresar. Ejemplos comunes: áreas de inicio de sesión que generan muchas URL diferentes, áreas de prueba o donde pueden existir múltiples facetas de navegación. Y asegúrese de controlar su archivo robots.txt para detectar cualquier problema o cambio.

La mayoría de los problemas que veo con los archivos robots.txt se dividen en tres grupos:
- El mal manejo de los comodines. Es bastante común ver partes del sitio bloqueadas que estaban destinadas a estar bloqueadas. A veces, si no tiene cuidado, las directivas también pueden entrar en conflicto entre sí.
- Alguien, como un desarrollador, ha realizado un cambio de la nada (a menudo al introducir un código nuevo) y ha modificado inadvertidamente el archivo robots.txt sin su conocimiento.
- La inclusión de directivas que no pertenecen a un archivo robots.txt. Robots.txt es estándar web y es algo limitado. A menudo veo a los desarrolladores crear directivas que simplemente no funcionan (al menos para la mayoría de los rastreadores). A veces eso es inofensivo, a veces no tanto.
Ejemplo
Veamos un ejemplo para ilustrar esto:
Usted tiene un sitio web de comercio electrónico y los visitantes pueden usar un filtro para buscar rápidamente sus productos. Este filtro genera páginas que básicamente muestran el mismo contenido que otras páginas. Esto funciona muy bien para los usuarios, pero confunde a los motores de búsqueda porque crea contenido duplicado.
No desea que los motores de búsqueda indexen estas páginas filtradas y pierdan su valioso tiempo en estas URL con contenido filtrado. Por lo tanto, debe configurar Disallow reglas para que los motores de búsqueda no accedan a estas páginas de productos filtradas.
También puede evitar el contenido duplicado mediante la URL canónica o la metaetiqueta robots, sin embargo, no se trata de permitir que los motores de búsqueda solo rastreen las páginas que importan.
El uso de una URL canónica o una metaetiqueta robots no evitará que los motores de búsqueda rastreen estas páginas. Solo evitará que los motores de búsqueda muestren estas páginas en los resultados de búsqueda. Dado que los motores de búsqueda tienen un tiempo limitado para rastrear un sitio web, este tiempo debe dedicarse a las páginas que desea que aparezcan en los motores de búsqueda.
Un archivo robots.txt configurado incorrectamente puede estar frenando su rendimiento de SEO. ¡Compruebe si este es el caso de su sitio web de inmediato!

Es una herramienta muy simple, pero un archivo robots.txt puede causar muchos problemas si no está configurado correctamente, especialmente para sitios web más grandes. Es muy fácil cometer errores, como bloquear todo un sitio después de implementar un nuevo diseño o CMS, o no bloquear secciones de un sitio que deberían ser privadas. Para los sitios web más grandes, es muy importante asegurarse de que Google rastree de manera eficiente y un archivo robots.txt bien estructurado es una herramienta esencial en ese proceso.
Debe tomarse un tiempo para comprender qué secciones de su sitio se mantienen mejor alejadas de Google para que gasten la mayor cantidad de recursos posibles rastreando las páginas que realmente te interesan.
¿Cómo se ve un archivo robots.txt?
Un ejemplo de cómo puede ser un archivo robots.txt simple para un sitio web de WordPress parecerse a:
Expliquemos la anatomía de un archivo robots.txt según el ejemplo anterior:
- User-agent: el
user-agentindica para qué búsqueda motores, las directivas que siguen están destinadas. -
*: esto indica que las directivas están destinadas a todos los motores de búsqueda. -
Disallow: esta es una directiva que indica qué contenido no es accesible parauser-agent. -
/wp-admin/: este es elpathque es inaccesible para eluser-agent.
En resumen: este archivo robots.txt le dice a todos los motores de búsqueda que se mantengan fuera del directorio /wp-admin/.
Analicemos los diferentes componentes de los archivos robots.txt con más detalle:
- User-agent
- No permitir
- Permitir
- Mapa del sitio
- Retraso de rastreo
Agente de usuario en robots.txt
Cada motor de búsqueda debe identificarse con un user-agent. Los robots de Google se identifican como Googlebot, por ejemplo, los robots de Yahoo como Slurp y el robot de Bing como BingBot y así sucesivamente.
El registro user-agent define el inicio de un grupo de directivas. Todas las directivas entre el primer user-agent y el siguiente user-agent registro se tratan como directivas para el primer user-agent.
Las directivas pueden aplicarse a agentes de usuario específicos, pero también pueden aplicarse a todos los agentes de usuario. En ese caso, se utiliza un comodín: User-agent: *.
Disallow directiva en robots.txt
Puede decirle a los motores de búsqueda que no accedan determinados archivos, páginas o secciones de su sitio web. Esto se hace usando la directiva Disallow. La directiva Disallow va seguida de la path a la que no se debe acceder. Si no se define ningún path, la directiva se ignora.
Ejemplo
En este ejemplo, a todos los motores de búsqueda se les dice que no accedan al directorio /wp-admin/.
La directiva Allow en robots.txt
La directiva Allow se usa para contrarrestar una directiva Disallow. La directiva Allow es compatible con Google y Bing. Usando las directivas Allow y Disallow juntas, puede decirle a los motores de búsqueda que pueden acceder a un archivo o página específicos dentro de un directorio que de otro modo no estaría permitido. La directiva Allow es seguida por la path a la que se puede acceder. Si no se define path, la directiva se ignora.
Ejemplo
En el ejemplo anterior, todos los motores de búsqueda no pueden acceder a /media/ directorio, excepto por el archivo /media/terms-and-conditions.pdf.
Importante: al usar Allow y Disallow directivas juntas, asegúrese de no usar comodines ya que esto puede llevar a directivas en conflicto.
Ejemplo de directivas en conflicto
Los motores de búsqueda no sabrán qué hacer con la URL . No les queda claro si pueden acceder. Cuando las directivas no son claras para Google, optarán por la directiva menos restrictiva, lo que en este caso significa que de hecho accederían a
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt es una de las características que más comúnmente veo implementadas incorrectamente, por lo que no bloquea lo que querían bloquear o bloquea más de lo que esperaban y tiene un impacto negativo en su sitio web. Robots.txt es una herramienta muy poderosa, pero con demasiada frecuencia se configura incorrectamente.
Uso de comodines *
No solo se puede usar el comodín para definir el user-agent, también se puede usar para coincide con las URL. El comodín es compatible con Google, Bing, Yahoo y Ask.
Ejemplo
En el ejemplo anterior, todos los motores de búsqueda no pueden acceder a URL que incluyan un signo de interrogación (?).

Desarrolladores o los propietarios de sitios a menudo parecen pensar que pueden utilizar todo tipo de expresiones regulares en un archivo robots.txt, mientras que solo una cantidad muy limitada de coincidencia de patrones es realmente válida, por ejemplo, comodines (
*). Parece haber una confusión entre los archivos .htaccess y los archivos robots.txt de vez en cuando.
Usando el final de la URL $
Para indicar el final de una URL, puede usar el signo de dólar ($) al final de path.
Ejemplo
En el ejemplo anterior, los motores de búsqueda no pueden acceder a todas las URL que terminan en .php . URL con parámetros, p. Ej. no se rechazaría, ya que la URL no termina después de .php.
Agregar mapa del sitio a robots. txt
Aunque el archivo robots.txt se inventó para indicar a los motores de búsqueda qué páginas no deben rastrear, el archivo robots.txt también se puede utilizar para dirigir a los motores de búsqueda al mapa del sitio XML. Esto es compatible con Google, Bing, Yahoo y Ask.
Se debe hacer referencia al mapa del sitio XML como una URL absoluta. La URL no tiene que estar en el mismo host que el archivo robots.txt.
Hacer referencia al mapa del sitio XML en el archivo robots.txt es una de las mejores prácticas que le recomendamos que haga siempre, aunque es posible que ya haya enviado su mapa del sitio XML en Google Search Console o Bing Webmaster Tools. Recuerde que existen más motores de búsqueda.
Tenga en cuenta que es posible hacer referencia a varios mapas de sitio XML en un archivo robots.txt.
Ejemplos
Varios Mapas del sitio XML definidos en un archivo robots.txt:
Un solo mapa de sitio XML definido en un archivo robots.txt archivo:
El ejemplo anterior le dice a todos los motores de búsqueda que no accedan al directorio /wp-admin/ y que el mapa del sitio XML se puede encontrar en
Comments are preceded by a # y puede estar al principio de una línea o después de una directiva en la misma línea. Todo lo que esté después de # se ignorará. Estos comentarios son solo para humanos.
Ejemplo 1
Ejemplo 2
Los ejemplos anteriores comunican el mismo mensaje.
Rastreo-retraso en robots.txt
El Crawl-delay directiva es una directiva no oficial que se utiliza para evitar la sobrecarga de servidores con demasiadas solicitudes. Si los motores de búsqueda pueden sobrecargar un servidor, agregar Crawl-delay a su archivo robots.txt es solo una solución temporal. El hecho es que su sitio web se está ejecutando en un entorno de alojamiento deficiente y / o su sitio web está configurado incorrectamente, y debe solucionarlo lo antes posible.
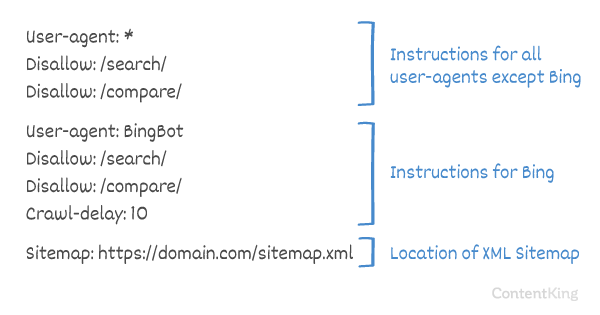
La forma en que los motores de búsqueda manejan Crawl-delay es diferente. A continuación, explicamos cómo lo manejan los principales motores de búsqueda.
Crawl-delay y Google
El rastreador de Google, Googlebot, no es compatible con Crawl-delay directiva, por lo que no se moleste en definir un retraso de rastreo de Google.
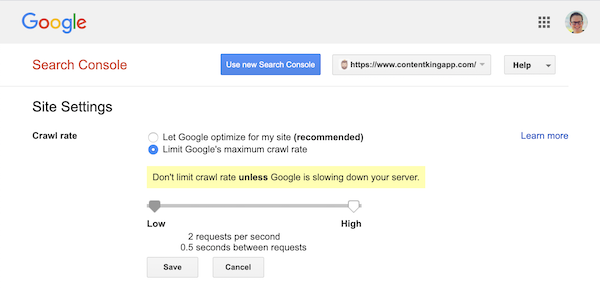
Sin embargo, Google admite la definición de una frecuencia de rastreo (o «tasa de solicitud» si lo desea ) en Google Search Console.
- Inicie sesión en la antigua Google Search Console.
- Elija el sitio web que desea definir la frecuencia de rastreo.
- Solo hay una configuración que puede modificar:
Crawl rate, con un control deslizante donde puede establecer la frecuencia de rastreo preferida. De forma predeterminada la frecuencia de rastreo está configurada en «Permitir que Google optimice mi sitio (recomendado)».
Así es como se ve en Google Search Console:
Rastreo-retraso y Bing, Yahoo y Yandex
Bing, Yahoo y Yandex todos apoyan el Crawl-delay directiva para acelerar el rastreo de un sitio web. Sin embargo, su interpretación del retraso de rastreo es ligeramente diferente, así que asegúrese de verificar su documentación:
- Bing y Yahoo
- Yandex
La directiva Crawl-delay debe colocarse justo después de las directivas Disallow o Allow.
Ejemplo:
Crawl-delay y Baidu
Baidu no es compatible con la directiva crawl-delay, sin embargo, es posible registrar una cuenta de Baidu Webmaster Tools en que puede controlar la frecuencia de rastreo, similar a Google Search Console.
¿Cuándo usar un archivo robots.txt?
Recomendamos utilizar siempre un archivo robots.txt. No hay nada de malo en tener uno, y es un gran lugar para entregar directivas a los motores de búsqueda sobre cómo pueden rastrear mejor su sitio web.

El archivo robots.txt puede resultar útil para evitar que determinadas áreas o documentos de su sitio sean rastreados e indexados. Algunos ejemplos son, por ejemplo, el sitio de ensayo o los archivos PDF. Planifique cuidadosamente lo que los motores de búsqueda deben indexar y tenga en cuenta que los rastreadores de motores de búsqueda aún pueden encontrar contenido que se ha hecho inaccesible a través de robots.txt si está vinculado desde otras áreas del sitio web.
Mejores prácticas de Robots.txt
Las mejores prácticas de robots.txt se clasifican de la siguiente manera:
- Ubicación y nombre de archivo
- Orden de precedencia
- Solo un grupo de directivas por robot
- Sea lo más específico posible
- Directivas para todos los robots y al mismo tiempo incluya directivas para un robot específico
- Archivo Robots.txt para cada (sub) dominio.
- Directrices contradictorias: robots.txt frente a Google Search Console
- Supervise su archivo robots.txt
- No utilice noindex en su archivo robots.txt
- Evitar UTF-8 BOM en el archivo robots.txt
Ubicación y nombre de archivo
El archivo robots.txt siempre debe colocarse en th e root de un sitio web (en el directorio de nivel superior del host) y llevan el nombre de archivo robots.txt, por ejemplo: . Tenga en cuenta que la URL del archivo robots.txt, como cualquier otra URL, distingue entre mayúsculas y minúsculas.
Si el archivo robots.txt no se puede encontrar en la ubicación predeterminada, los motores de búsqueda asumirán que no hay directivas y se arrastrarán por su sitio web.
Orden de precedencia
Es importante tener en cuenta que los motores de búsqueda manejan los archivos robots.txt de manera diferente. De forma predeterminada, la primera directiva coincidente siempre gana.
Sin embargo, con Google y Bing, la especificidad gana. Por ejemplo: una directiva Allow gana sobre una directiva Disallow si la longitud de sus caracteres es mayor.
Ejemplo
En el Por ejemplo, todos los motores de búsqueda, incluidos Google y Bing, no pueden acceder al directorio /about/, excepto al subdirectorio /about/company/.
Ejemplo
En el ejemplo anterior, todos los motores de búsqueda, excepto Google y Bing, no tienen acceso al directorio /about/. Eso incluye el directorio /about/company/.
Google y Bing tienen permitido el acceso, porque la directiva Allow es más larga que la Disallow directiva.
Solo un grupo de directivas por robot
Solo puede definir un grupo de directivas por motor de búsqueda. Tener varios grupos de directivas para un motor de búsqueda los confunde.
Sea lo más específico posible
La directiva Disallow se activa en coincidencias parciales como bien. Sea lo más específico posible al definir la directiva Disallow para evitar denegar involuntariamente el acceso a los archivos.
Ejemplo:
El ejemplo anterior no permite que los motores de búsqueda accedan a:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Directivas para todos los robots y también incluyen directivas para un robot específico
Para un robot solo un grupo de directivas es válido. En caso de que las directivas destinadas a todos los robots se sigan con directivas para un robot específico, solo se tendrán en cuenta estas directivas específicas. Para que el robot específico también siga las directivas para todos los robots, debe repetir estas directivas para el robot específico.
Veamos un ejemplo que lo aclarará:
Ejemplo
Si no desea que el robot de Google acceda a /secret/ y /not-launched-yet/, debe repetir estas directivas para googlebot específicamente:
Tenga en cuenta que su archivo robots.txt está disponible públicamente. Las personas con intenciones malintencionadas pueden utilizar como vector de ataque las secciones del sitio web que no se permiten.

Robots.txt puede ser peligroso. No solo le estás diciendo a los motores de búsqueda dónde no quieres que miren, le estás diciendo a la gente dónde escondes tus secretos sucios.
Archivo Robots.txt para cada (sub) dominio
Solo directivas Robots.txt se aplica al (sub) dominio en el que está alojado el archivo.
Ejemplos
es válido para , pero no para o
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Creamos el seguimiento de cambios y las alertas de robots.txt por este motivo.
Lo vemos todo el tiempo: los archivos robots.txt cambian sin conocimiento del marketing digital equipo. No seas esa persona. ¡Comience a monitorear su archivo robots.txt ahora reciba alertas cuando cambie!
No use noindex en su archivo robots.txt
Durante años, Google ya recomendaba abiertamente no utilizar la directiva noindex no oficial. Sin embargo, a partir del 1 de septiembre de 2019, Google dejó de admitirlo por completo.
La directiva noindex no oficial nunca funcionó en Bing, como lo confirma Frédéric Dubut en este tweet:
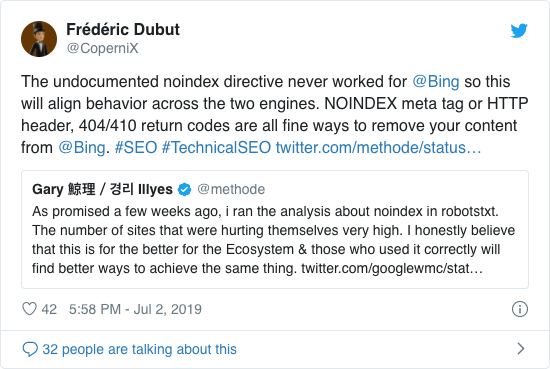
La mejor manera de indicar a los motores de búsqueda que las páginas no deben indexarse es utilizando la etiqueta meta robots o X-Robots-Tag .
Evitar UTF-8 BOM en el archivo robots.txt
BOM significa marca de orden de bytes, un carácter invisible al principio de un archivo utilizado para indicar la codificación Unicode de un archivo de texto.
Si bien Google afirma que ignora la marca de orden de bytes Unicode opcional al comienzo del archivo robots.txt, recomendamos evitar la «UTF-8 BOM» porque hemos visto que causa problemas con la interpretación de el archivo robots.txt por los motores de búsqueda.
Aunque Google dice que pueden manejarlo, aquí hay dos razones para evitar la BOM UTF-8:
- No No quiero que haya ninguna ambigüedad sobre sus preferencias en cuanto al rastreo de los motores de búsqueda.
- Existen otros motores de búsqueda que pueden no ser tan indulgentes como Google afirma ser.
Ejemplos de Robots.txt
En este capítulo cubriremos una amplia gama de ejemplos de archivos robots.txt:
- Permitir que todos los robots accedan a todo
- No permitir que todos los robots accedan a todo
- Todos los bots de Google no tienen acceso
- Todos los bots de Google, excepto las noticias de Googlebot, no tienen acceso
- Googlebot y Slurp no tienen acceso
- Todos los robots no tienen acceso a dos directorios
- Todos los robots no tienen acceso a un archivo específico
- Googlebot no tiene acceso a / admin / y Slurp no tiene acceso a / private /
- Archivo Robots.txt para WordPress
- Archivo Robots.txt para Magento
Permitir que todos los robots accedan a todo
Hay varias formas para indicarle a los motores de búsqueda que pueden acceder a todos los archivos:
O tener un archivo robots.txt vacío o no tener ningún archivo robots.txt.
No permitir que todos los robots accedan a todo
El ejemplo El archivo robots.txt a continuación indica a todos los motores de búsqueda que no accedan a todo el sitio:
Tenga en cuenta que solo UN carácter adicional puede marcar la diferencia.
No todos los bots de Google tienen acceso
Tenga en cuenta que al rechazar Googlebot, esto se aplica a todos los Googlebots. Eso incluye robots de Google que buscan, por ejemplo, noticias (googlebot-news) e imágenes (googlebot-images).
Todos Los bots de Google, excepto Googlebot News, no tienen acceso
Googlebot y Slurp no tienen acceso
Todos los robots no tienen acceso a dos directorios
Todos los robots no tienen acceso a un archivo específico
Googlebot no tiene acceso a / admin / y Slurp no tienen acceso a / private /
Robots.txt archivo para WordPress
El archivo robots.txt a continuación está optimizado específicamente para WordPress, asumiendo:
- No desea que se rastree su sección de administración.
- No desea que se rastreen sus páginas de resultados de búsqueda internos.
- No desea que se rastreen sus páginas de etiquetas y autor.
- No No desea que se rastree su página 404.
Tenga en cuenta que este archivo robots.txt funcionará en la mayoría de los casos, pero siempre debe ajustarlo y probarlo para asegurarse de que se aplique a su situación exacta.
Archivo Robots.txt para Magento
El archivo robots.txt a continuación está optimizado específicamente para Magento y generará resultados de búsqueda internos, páginas de inicio de sesión, identificadores de sesión y resultado filtrado conjuntos que contienen price, color, material y size criterios inaccesibles para los rastreadores.
Tenga en cuenta que este archivo robots.txt funcionará para la mayoría de las tiendas Magento, pero usted siempre debe ajustarlo y probarlo para asegurarse de que se aplique a su situación exacta.
Siempre buscaría bloquear los resultados de búsqueda internos en robots.txt en cualquier sitio porque estos tipos de URL de búsqueda son espacios infinitos y sin fin. Hay muchas posibilidades de que el robot de Google caiga en una trampa de rastreo.
¿Cuáles son las limitaciones del archivo robots.txt?
El archivo Robots.txt contiene directivas
Aunque el archivo robots.txt es muy respetado por las búsquedas motores, sigue siendo una directiva y no un mandato.
Páginas que siguen apareciendo en los resultados de búsqueda
Páginas que son inaccesibles para los motores de búsqueda debido a los robots.txt, pero tienen enlaces a ellos, pueden aparecer en los resultados de búsqueda si están enlazados desde una página que se rastrea. Un ejemplo de cómo se ve esto:

Es posible eliminar estas URL de Google mediante la herramienta de eliminación de URL de Google Search Console. Tenga en cuenta que estas URL solo se «ocultarán» temporalmente. Para que permanezcan fuera de las páginas de resultados de Google, debe enviar una solicitud para ocultar las URL cada 180 días.

Utilice robots.txt para bloquear los backlinks de afiliados no deseados y probablemente dañinos. no use robots.txt para evitar que los motores de búsqueda indexen el contenido, ya que esto inevitablemente fallará. En su lugar, aplique la directiva de robots noindex cuando sea necesario.
El archivo Robots.txt se almacena en caché hasta 24 horas
Google ha indicado que un archivo robots El archivo .txt generalmente se almacena en caché por hasta 24 horas. Es importante tener esto en cuenta cuando realiza cambios en su archivo robots.txt.
No está claro cómo otros motores de búsqueda manejan el almacenamiento en caché de robots.txt. , pero en general es mejor evitar almacenar en caché el archivo robots.txt en av oid, los motores de búsqueda tardan más de lo necesario en detectar los cambios.
Tamaño del archivo Robots.txt
Para los archivos robots.txt, Google admite actualmente un límite de tamaño de archivo de 500 kibibytes (512 kilobytes). Cualquier contenido después de este tamaño máximo de archivo puede ser ignorado.
No está claro si otros motores de búsqueda tienen un máximo de archivos robots.txt.
Preguntas frecuentes sobre robots.txt
🤖 ¿Cómo se ve un ejemplo de robots.txt?
Aquí hay un ejemplo del contenido de un robots.txt: User-agent: * Disallow:. Esto les dice a todos los rastreadores que pueden acceder a todo.
⛔ ¿Qué hace No permitir todos en robots.txt?
Cuando configura un archivo robots.txt en «No permitir todos», Básicamente, les dice a todos los rastreadores que se mantengan fuera. Ningún rastreador, incluido Google, puede acceder a su sitio. Esto significa que no podrán rastrear, indexar ni clasificar su sitio. Esto provocará una caída masiva del tráfico orgánico.
✅ ¿Qué hace Permitir todo en robots.txt?
Cuando configura un archivo robots.txt en «Permitir todo», le dice a cada rastreador que puede acceder a todas las URL del sitio. Simplemente no hay reglas de participación. Tenga en cuenta que esto equivale a tener un archivo robots.txt vacío o no tener ningún archivo robots.txt.
🤔 ¿Qué importancia tiene el robots.txt para SEO?
En En general, el archivo robots.txt es muy importante para fines de SEO. Para sitios web más grandes, el archivo robots.txt es esencial para dar a los motores de búsqueda instrucciones muy claras sobre a qué contenido no acceder.