A ROW_NUMBER ablakfunkciónak számos gyakorlati alkalmazása van, jóval túl a nyilvánvaló rangsorolási igényeken. A sorszámok kiszámításakor legtöbbször valamilyen sorrend alapján kell kiszámítani őket, és a függvény ablakrendelési záradékában meg kell adni a kívánt sorrendspecifikációt. Vannak azonban esetek, amikor a sorszámokat külön sorrendben kell kiszámítani; más szavakkal, a nemdeterminisztikus rend alapján. Ez lehet a teljes lekérdezés eredménye, vagy partíciók között. Ilyen például az egyedi értékek hozzárendelése az eredménysorokhoz, az adatok deduplikálása és bármely csoport visszatérése csoportonként.
Ne feledje, hogy nem sorozatos sorrend alapján kell sorszámokat rendelni, mint véletlenszerű sorrend alapján. Az előbbieknél csak nem érdekli, hogy milyen sorrendben vannak hozzárendelve, és hogy a lekérdezés ismételt végrehajtása ugyanazokat a sorokat rendeli-e ugyanazokhoz a sorokhoz, vagy sem. Ez utóbbinál az ismételt végrehajtásokra számít, hogy folyamatosan változik, hogy mely sorokat mely sorszámokhoz rendelik hozzá. Ez a cikk különféle módszereket tár fel a sorszámok nemdeterminisztikus sorrendben történő kiszámítására. A remény egy megbízható és optimális technika megtalálása.
Külön köszönet Paul White-nak az állandó hajtogatással kapcsolatos tippért, a futásidejű állandó technikáért és azért, hogy mindig nagyszerű információforrás volt!
Ha fontos a megrendelés
Kezdem olyan esetekkel, amikor a sorszámok rendezése számít.
A T1 nevű táblázatot használom a példáimban. A következő kód használatával hozza létre ezt a táblázatot, és töltse fel mintaadatokkal:
Vegye figyelembe a következő lekérdezést (ezt 1. lekérdezésnek hívjuk):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Itt azt szeretné, hogy sorszámok legyenek kijelölve minden csoportban, amelyeket az grp oszlop azonosít, az oszlop datacol sorrendjében. Amikor futtattam ezt a lekérdezést a rendszeremen, a következő kimenetet kaptam:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
A sorszámokat itt részben determinisztikus, részben nemdeterminisztikus sorrendben rendelték hozzá. Ezzel azt akarom mondani, hogy biztos abban, hogy ugyanazon a partíción belül egy nagyobb datacol értékű sor nagyobb sorszám értéket kap. Mivel azonban a datacol nem egyedi a grp partíción belül, a sorszámok kiosztásának sorrendje azonos grp és datacol értékekkel rendelkező sorok között nem meghatározó. Ez a helyzet a 2-es és 11-es id értékű sorokkal. Mindkettőnek van A grp értéke és 50 datacol értéke. Amikor először hajtottam végre ezt a lekérdezést a rendszeremen, a 2. azonosítóval rendelkező sor megkapta a 2. sorszámot és a A 11. azonosítójú sor megkapta a 3. sorszámot. Ne feledje, hogy ez a gyakorlatban bekövetkezhet az SQL Serverben; ha újra lefuttatom a lekérdezést, elméletileg a 2. azonosítóval rendelkező sort a 3. sorhoz lehet rendelni, a 11. azonosítóval rendelkező sort a 2. sorhoz.
Ha sorszámokat kell rendelnie teljesen determinisztikus sorrendben, garantálva a megismételhető eredményeket a lekérdezés végrehajtásakor, mindaddig, amíg az alapul szolgáló adatok nem változnak, az ablakpartíciós és rendezési záradékok kombinációjának egyedinek kell lennie. Ez a mi esetünkben úgy érhető el, hogy az oszlopazonosítót az ablakrendelési záradékhoz tiebreakerként hozzáadjuk. Az OVER záradék a következő lenne:
OVER (PARTITION BY grp ORDER BY datacol, id)
Mindenesetre, amikor a sorszámokat valamilyen értelmes sorrendspecifikáció alapján számoljuk ki, például az 1. lekérdezésben, az SQL Server-nek feldolgoznia kell a az ablakok particionálása és a sorrend elemei kombinációjával rendezett sorok. Ezt úgy érhetjük el, hogy vagy előhívjuk az indexből az előrendelt adatokat, vagy az adatok rendezésével. Jelenleg a T1-en nincs index, amely támogatná a ROW_NUMBER számítást az 1. lekérdezésben, ezért az SQL Server-nek választania kell az adatok rendezését. Ez látható az 1. lekérdezés 1. ábrán látható tervén.
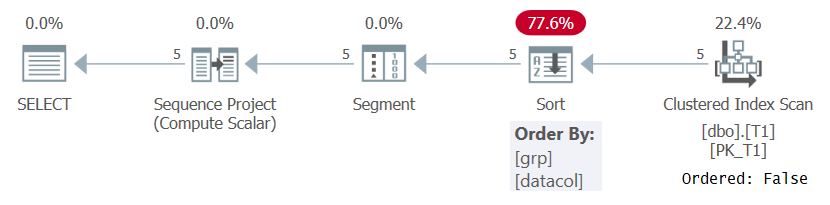 1. ábra: Az 1. lekérdezés terve támogató index nélkül
1. ábra: Az 1. lekérdezés terve támogató index nélkül
Figyeljük meg, hogy a terv a fürtözött indexből származó adatokat rendezi: Hamis tulajdonsággal. Ez azt jelenti, hogy a beolvasásnak nem kell visszaadnia az indexkulccsal rendezett sorokat. Ez a helyzet, mivel a fürtözött indexet itt csak azért használjuk, mert véletlenül lefedi a lekérdezést, és nem a kulcsrendje miatt. Ezután a terv egyfajta rendszert alkalmaz, ami extra költségeket, N Log N méretezést és késleltetett válaszidőt eredményez. A Szegmens operátor létrehoz egy jelzőt, amely jelzi, hogy a sor az első-e a partícióban, vagy sem. Végül a Sequence Project operátor minden partícióban 1-vel kezdődő sorszámokat rendel.
Ha el akarja kerülni a rendezés szükségességét, elkészíthet egy fedőindexet egy kulcslistával, amely a particionálási és rendezési elemeken alapul, valamint egy olyan bevonási listát, amely a fedőelemeken alapul.Szeretem ezt az indexet POC indexként gondolni (particionálásra, rendezésre és fedésre). A lekérdezésünket támogató POC meghatározása:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Futtassa újra az 1. kérdést:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
A végrehajtás terve a 2. ábrán látható.
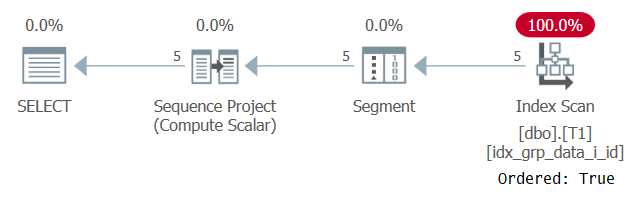 2. ábra: Az 1. lekérdezés terve POC index segítségével
2. ábra: Az 1. lekérdezés terve POC index segítségével
Figyelje meg, hogy ezúttal a terv a POC indexet egy Rendezett: Igaz tulajdonsággal vizsgálja. Ez azt jelenti, hogy a beolvasás garantálja, hogy a sorok indexkulcs sorrendben kerülnek visszaadásra. Mivel az adatokat előre rendezik az indexből, ahogy az ablakfunkciónak szüksége van, nincs szükség explicit rendezésre. Ennek a tervnek a méretaránya lineáris, a válaszidő pedig jó.
Ha a sorrend nem számít
A dolgok kissé bonyolultabbá válnak, ha teljesen nem determinisztikus sorszámokat kell hozzárendelni. sorrend. Ilyen esetben a ROW_NUMBER függvény természetes használata az ablak sorrendjének megadása nélkül. Először ellenőrizzük, hogy az SQL szabvány ezt megengedi-e. Itt található a szabvány megfelelő része, amely meghatározza az ablak szintaxis szabályait függvények:
Vegye figyelembe, hogy a 6. tétel felsorolja a < ntile függvényeket >, < lead vagy lag függvény >, < rangfüggvény típusa > vagy ROW_NUMBER, majd a 6a. Tétel azt mondja, hogy a < ntile függvényhez >, < lead vagy lag függvény >, RANK vagy DENSE_RANK, az ablakrendi záradék b e jelen van. Nincs kifejezett nyelv, amely megadná, hogy a ROW_NUMBER megköveteli-e az ablakrendi záradékot vagy sem, de a 6. tételben szereplő függvény megemlítése és a 6a. Pontban való kihagyása azt jelentheti, hogy a záradék opcionális ehhez a függvényhez. Nagyon nyilvánvaló, hogy a RANK és a DENSE_RANK funkciókhoz miért lenne szükség ablakrendi záradékra, mivel ezek a függvények a kapcsolatok kezelésére szakosodtak, és a kapcsolatok csak akkor léteznek, ha vannak rendelési előírások. Mindazonáltal biztosan láthatja, hogy a ROW_NUMBER függvény milyen előnyökkel járhat egy opcionális ablakrendezési záradékban.
Tehát tegyünk egy próbát, és próbáljuk meg kiszámolni a sorszámokat ablakrendezés nélkül az SQL Serverben:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Ez a kísérlet a következő hibát eredményezi:
A “ROW_NUMBER” függvény tartalmaznia kell egy OVER záradékot ORDER BY-vel.
Ha valóban megnézi az SQL Server ROW_NUMBER függvény dokumentációját, a következő szöveget találja:
A RENDELÉS A BY záradék határozza meg azt a sorrendet, amelyben a sorok egyedi ROW_NUMBER számot kapnak egy megadott partíción belül. Szükséges. ”
Tehát nyilvánvaló, hogy az ablakrendi záradék kötelező az SQL Server ROW_NUMBER függvényéhez. . Egyébként ez az Oracle esetében is.
Azt kell mondanom, hogy nem vagyok biztos abban, hogy értem az indoklást ng mögött ez a követelmény. Ne feledje, hogy engedélyezi a sorszámok meghatározását részben nemdeterminisztikus sorrend alapján, mint például az 1. lekérdezésben. Akkor miért nem engedi meg a nemdeterminizmust? Talán van valami oka, amire nem gondolok. Ha eszébe jut ilyen ok, kérjük, ossza meg.
Mindenesetre azt állíthatja, hogy ha nem érdekel a megrendelés, mivel az ablakrendelési klauzula kötelező, akkor megadhat rendelés. Ezzel a megközelítéssel az a probléma, hogy ha valamelyik oszlop alapján megrendel a lekérdezett táblázat (ok) ból, ez szükségtelen teljesítménybüntetést von maga után. Ha nincs támogató index a helyén, akkor fizetnie kell az explicit rendezésért. Ha van egy támogató index a helyén, akkor a tárolómotort egy index-rendelés beolvasási stratégiára korlátozza (az indexhez kapcsolt listát követve). Nem engedi meg nagyobb rugalmasságot, mint általában, amikor a sorrendnek nincs jelentősége az index-sorrend-beolvasás és a kiosztási sorrend-vizsgálat között (az IAM-oldalak alapján).
Egy ötlet, amelyet érdemes kipróbálni egy konstans megadása, például 1, az ablakrendelési záradékban. Ha támogatott, akkor remélné, hogy az optimalizáló elég okos ahhoz, hogy rájöjjön, hogy minden sornak ugyanaz az értéke, tehát nincs valós megrendelési relevancia, és ezért nem kell kényszeríteni egy rendezés vagy egy index sorrend beolvasását. Itt van egy lekérdezés, amely megpróbálja ezt a megközelítést:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Sajnos az SQL Server nem támogatja ezt a megoldást. A következő hibát generálja:
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az egész indexeket ORDER BY tagmondatként.
Nyilvánvaló, hogy az SQL Server feltételezi, hogy ha egész szám konstansot használ az ablakrendelési záradékban, akkor ez a SELECT lista egy elemének rendes helyzetét képviseli, például amikor egész számot ad meg a prezentáció ORDER-ben BY záradék. Ebben az esetben egy másik lehetőség, amelyet érdemes kipróbálni, egy nemintegrációs konstans megadása, például:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Kiderült, hogy ez a megoldás sem támogatott. Az SQL Server a következő hibát generálja:
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az állandókat ORDER BY tagmondatként.
Nyilvánvaló, hogy az ablakrendezési záradék nem támogat semmiféle állandót.
Eddig a következőket tudtuk meg a ROW_NUMBER függvény ablakrendezési relevanciájáról az SQL Server rendszerben:
- ORDER BY szükséges.
- Nem lehet egész konstanssal rendezni, mivel az SQL Server úgy gondolja, hogy megpróbál egy sorszámot megadni a SELECT-ben.
- Nem lehet bármilyen konstans.
A következtetés az, hogy állítólag nem konstans kifejezésekkel kell rendezni. Nyilvánvaló, hogy oszloplista alapján is rendelhet a lekérdezett táblákból. De arra törekszünk, hogy olyan hatékony megoldást találjunk, ahol az optimalizáló rájön, hogy nincs relevancia a megrendelés szempontjából.
Állandó hajtogatás
Eddig az a következtetés, hogy nem használhat konstansokat a a A ROW_NUMBER ablak sorrendje, de mi a helyzet az állandókon alapuló kifejezésekkel, például a következő lekérdezéssel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Ez a kísérlet azonban egy állandónak nevezett folyamat áldozatává válik összecsukás, amelynek általában pozitív teljesítménye van a lekérdezésekre. Ennek a technikának az az ötlete, hogy javítsa a lekérdezés teljesítményét azáltal, hogy az állandókon alapuló kifejezéseket az eredményállandóikra hajtja a lekérdezés feldolgozásának korai szakaszában. Itt talál részleteket arról, hogy milyen típusú kifejezések állandóan hajtogathatók. Az 1 + 0 kifejezés 1-re van hajtva, ami ugyanazt a hibát eredményezi, amelyet az 1 konstans közvetlen megadásakor kapott:
ablakos függvények, Az aggregátumok és a NEXT VALUE FOR függvények nem támogatják az egész indexeket ORDER BY záradékkifejezésekként.
Hasonló helyzetbe kerülne, amikor két karakterlánc-literált összefűzni próbál, például:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Ugyanazt a hibát kapja, amelyet a szó szerinti “No Order” közvetlen megadásakor kapott:
ablakos A függvények, aggregátumok és a NEXT VALUE FOR függvények nem támogatják az állandókat ORDER BY tagmondatként.
Bizarro világ – hibák, amelyek megakadályozzák a hibákat
Az élet tele van meglepetésekkel …
Egyetlen dolog megakadályozza az állandó hajtogatást, amikor a kifejezés általában hibát eredményez. Például a 2147483646 + 1 kifejezés állandóan hajtogatható, mivel érvényes INT-típusú értéket eredményez. Következésképpen a következő lekérdezés futtatásának sikertelensége meghiúsul:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Ablakos függvények, összesítők és KÖVETKÖZŐ ÉRTÉK A FOR függvények nem támogatják az egész indexeket ORDER BY tagmondatként.
A 2147483647 + 1 kifejezés azonban nem lehet állandóan hajtogatható, mert egy ilyen kísérlet INT-túlcsordulási hibát eredményezett. A megrendelésre gyakorolt hatás meglehetősen érdekes. Próbálja ki a következő lekérdezést (ezt 2. lekérdezésnek hívjuk):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Furcsa módon ez a lekérdezés sikeresen fut! Az történik, hogy egyrészt az SQL Server nem képes állandó hajtogatást alkalmazni, ezért a sorrendezés olyan kifejezésen alapul, amely nem egyetlen állandó. Másrészt az optimalizáló úgy gondolja, hogy a sorrend értéke minden sorban megegyezik, ezért teljesen figyelmen kívül hagyja a sorrend kifejezését. Ezt megerősítik a lekérdezés tervének a 3. ábra szerinti vizsgálata során.
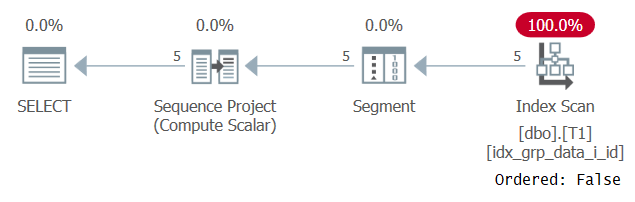 3. ábra: A 2. lekérdezés terve
3. ábra: A 2. lekérdezés terve
Figyelje meg hogy a terv néhány lefedett indexet egy Rendezett: Hamis tulajdonsággal vizsgál. Pontosan ez volt a teljesítménycélunk.
Hasonló módon a következő lekérdezés sikeres állandó hajtogatási kísérletet is magában foglal, ezért kudarcot vall:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az egész indexeket ORDER BY tagmondatként.
A következő lekérdezés sikertelen állandó hajtogatási kísérletet tartalmaz, és ezért sikeres, előállítva a 3. ábrán korábban bemutatott tervet:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
A következők a lekérdezés sikeres állandó hajtogatási kísérletet foglal magában (a VARCHAR szó szerinti “1” szó implicit módon konvertálódik az INT 1-be, majd az 1 + 1-et 2-re hajtja), és ezért sikertelen:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az egész indexeket ORDER BY tagmondatként.
A következő lekérdezés egy sikertelen állandó hajtogatási kísérlet (az “A” nem konvertálható INT-be), ezért sikeres, a 3. ábrán korábban bemutatott terv létrehozásával:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Hogy őszinte legyek, annak ellenére, hogy ez a bizarr technika eléri az eredeti teljesítménycélunkat, nem mondhatom, hogy biztonságosnak tartanám, és ezért nem vagyok olyan kényelmesen támaszkodni rá.
Futásidejű konstansok függvények alapján
Folytatva a jó megoldás keresését a sorszámok nemdeterminisztikus sorrendben történő kiszámításához, van néhány olyan technika, amely biztonságosabbnak tűnik, mint az utolsó furcsa megoldás: függvényeken alapuló futásidejű konstansok használata, konstanson alapuló részlekérdezés használata álneves oszlop konstans alapján és változó segítségével.
Amint azt a T-SQL hibáival, buktatóival és bevált gyakorlataival – a determinizmussal – elmagyarázom, a T-SQL legtöbb funkcióját a lekérdezésben szereplő referenciánként csak egyszer értékelik – nem soronként. Ez a helyzet a legtöbb nemdeterminista funkcióval is, például a GETDATE és a RAND. Nagyon kevés kivétel van ennél a szabálynál, mint például a NEWID és a CRYPT_GEN_RANDOM függvények, amelyeket soronként egyszer értékelünk. A legtöbb függvényt, mint például a GETDATE, @@ SPID és még sok más, a lekérdezés elején egyszer kiértékelik, és ezek értékeit futásidejű állandónak tekintik. Az ilyen funkciókra való hivatkozás nem lesz állandóan összehajtva. Ezek a jellemzők a függvényen alapuló futási állandót jó választássá teszik az ablakrendező elemként, és úgy tűnik, hogy a T-SQL támogatja. Az optimalizáló ugyanakkor rájön, hogy a gyakorlatban nincs relevancia a megrendelésre, elkerülve a felesleges teljesítménybüntetéseket.
Íme egy példa a GETDATE függvény használatára:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Ez a lekérdezés ugyanazt a tervet kapja, amelyet a 3. ábra korábban bemutatott.
Íme egy másik példa a @@ SPID függvény használatával (az aktuális munkamenet-azonosító visszaadása):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Mi a helyzet a PI függvénnyel? Próbálja ki a következő lekérdezést:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Ez a következő hibával bukik meg:
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az állandókat ORDER BY tagmondatként.
A GETDATE és a @@ SPID függvényeket a terv végrehajtása során egyszer értékeljük át, így nem tudnak állandó hajtogatott. A PI mindig ugyanazt az állandót képviseli, ezért állandóan hajtogatva van.
Amint azt korábban említettük, nagyon kevés olyan funkció van, amelyet soronként egyszer értékelünk, mint például a NEWID és a CRYPT_GEN_RANDOM. Ez rossz választás az ablakrendezési elemként, ha nemdeterminisztikus sorrendre van szükséged – ne keverd össze a véletlenszerű sorrenddel. Miért fizetne felesleges büntetést?
Íme egy példa a NEWID függvény használatával:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
A lekérdezés terve a 4. ábrán látható, megerősítve, hogy az SQL Server kifejezett rendezés a függvény eredménye alapján.
 4. ábra: A 3. lekérdezés megtervezése
4. ábra: A 3. lekérdezés megtervezése
Ha szeretné, hogy a sorszámok hozzárendelésre kerüljenek véletlenszerű sorrendben, mindenképpen ezt a technikát szeretné használni. Csak tisztában kell lennie azzal, hogy a rendezési költség felmerül.
Allekérdezés használata
Ablak-rendezési kifejezésként használhat egy konstanson alapuló lekérdezést is (pl. ORDER BY (SELECT “Nincs megrendelés”). Szintén ezzel a megoldással az SQL Server optimalizálója felismeri, hogy nincs relevancia a megrendelés szempontjából, ezért nem szab felesleges rendezést, és nem korlátozza a tároló motor választásait azokra, amelyeknek garantálniuk kell a megrendelést. Próbálkozzon példaként a következő lekérdezéssel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Ugyanazt a tervet kapja, mint a 3. ábrán.
Az egyik nagy előny ennek a technikának az a sajátja, hogy hozzáadhatja saját személyes vonásait.Talán nagyon kedveled a NULL-okat:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Talán nagyon tetszik egy bizonyos szám:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Talán üzenetet akar küldeni valakinek:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Érted a lényeget.
Megvalósítható, de kínos
Van néhány technika, amely működik, de kissé kínos. Az egyik az, hogy egy konstans alapján megadunk egy oszlop álnevet egy kifejezéshez, majd ezt az oszlop álnevet használjuk ablakrendezési elemként. Ezt megteheti akár egy táblázatkifejezéssel, akár a CROSS APPLY operátorral és egy táblázatérték-konstruktorral. Íme egy példa az utóbbira:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Ugyanazt a tervet kapja, amely a 3. ábrán látható.
Egy másik lehetőség egy változó használata ablakrendező elemként:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Ez a lekérdezés megkapja a 3. ábrán korábban bemutatott tervet is.
Mi van, ha saját UDF-et használok ?
Gondolhatja, hogy a saját UDF-je, amely állandót ad vissza, jó választás lehet ablakrendező elemként, ha nemdeterminisztikus sorrendet szeretne, de nem az. Tekintsük példaként az alábbi UDF definíciót:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Próbálja meg használni az UDF-et ablakrendelési záradékként, így (ezt hívjuk 4. lekérdezésnek):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Az SQL Server 2019 (vagy párhuzamos kompatibilitási szint < 150) előtt a felhasználó által definiált függvényeket soronként értékelik . Még akkor is, ha állandó értéket adnak vissza, nem kerülnek beillesztésre. Következésképpen egyrészt használhat egy ilyen UDF-et ablakrendező elemként, másrészt ez egyfajta büntetést von maga után. Ezt megerősíti a lekérdezés tervének vizsgálata, az 5. ábra szerint.
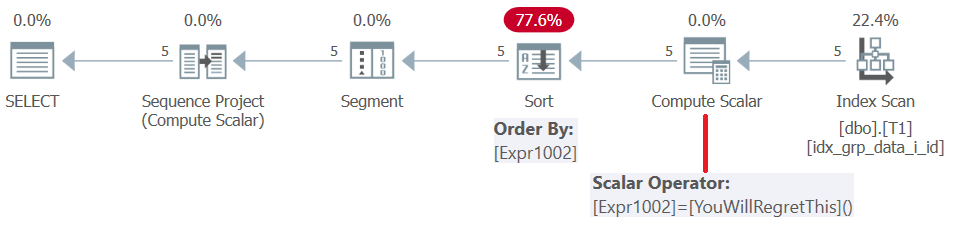 5. ábra: A 4. lekérdezés terve
5. ábra: A 4. lekérdezés terve
Az SQL Server 2019-től kezdődően > = 150 kompatibilitási szint alatt az ilyen felhasználó által definiált függvények beilleszkednek, ami többnyire nagyszerű dolog, de esetünkben hibát eredményez:
Az ablakos függvények, összesítők és a NEXT VALUE FOR függvények nem támogatják az állandókat ORDER BY tagmondatként.
Tehát egy UDF használata a konstans, mivel az ablakrendező elem rendezést vagy hibát kényszerít az SQL Server használt verziójától és az adatbázis-kompatibilitási szinttől függően. Röviden, ne tegye ezt.
Particionált sorszámok nemdeterminisztikus sorrendben
A nemdeterminisztikus sorrend alapján partíciózott sorszámok gyakori használata esetenként bármelyik sort visszaadja. Tekintettel arra, hogy definíció szerint ebben a forgatókönyvben létezik particionáló elem, úgy gondolja, hogy ilyen esetben biztonságos technika az, ha az ablak particionáló elemet is használja ablak rendezési elemként. Első lépésként a következőképpen számolja ki a sorszámokat:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
A lekérdezés terve a 6. ábrán látható.
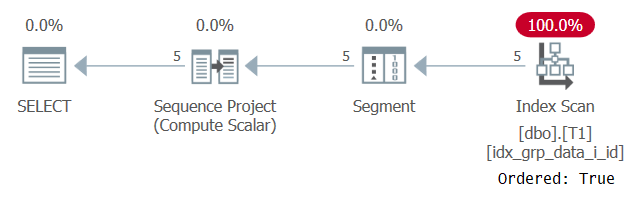 6. ábra: Az 5. lekérdezés terve
6. ábra: Az 5. lekérdezés terve
Az oka annak, hogy támogató indexünket Rendezett: Igaz tulajdonsággal vizsgáljuk, az az oka, hogy az SQL Server-nek minden partíció sorát egy egyetlen egység. Ez a helyzet a szűrés előtt. Ha partíciónként csak egy sort szűr, akkor a rendelésalapú és a hash-alapú algoritmusok is választhatók.
A második lépés a lekérdezés sorszámítással való elhelyezése egy tábla kifejezésben a külső lekérdezés minden partícióban kiszűri az 1. sor sorát, így:
Elméletileg ez a technika állítólag biztonságos, de Paul White talált egy hibát, amely azt mutatja, hogy ezzel a módszerrel attribútumokat kaphat különböző forrássorok a visszatérő eredménysorban partíciónként. A függvényen alapuló futásidejű állandó vagy konstanson alapuló részlekérdezés használata, mivel a rendelési elem még ebben a forgatókönyvben is biztonságosnak tűnik, ezért győződjön meg róla, hogy inkább a következő megoldást használja:
Senki engedélyem nélkül át kell haladnom ezen az úton
A sorszámok nemdeterminisztikus sorrend alapján történő kiszámításának megkísérlése általános igény. Jó lett volna, ha a T-SQL egyszerűen opcionálissá teszi az ablakrendelési záradékot a ROW_NUMBER függvényhez, de nem teszi meg. Ha nem, akkor jó lett volna, ha legalább megengedi a konstans használatát rendelési elemként, de ez sem támogatott opció.De ha szépen kérdezel, konstanson alapuló részlekérdezés vagy egy függvény alapján futásidejű állandó formájában, akkor az SQL Server megengedi. Ez a két lehetőség, amivel a legkényelmesebb vagyok. Nem igazán érzem jól magam a mókás hibás kifejezésekkel, amelyek úgy tűnik működnek, ezért nem tudom ajánlani ezt a lehetőséget.