A robotok A .txt fájl tartalmaz utasításokat a keresők számára. Használhatja annak megakadályozására, hogy a keresőmotorok feltérképezzék webhelye bizonyos részeit, és hasznos tippeket adjon a keresőmotoroknak arra vonatkozóan, hogy miként tudják a legjobban feltérképezni a webhelyet. A robots.txt fájl nagy szerepet játszik a SEO-ban.
A robots.txt telepítésekor tartsa szem előtt a következő bevált módszereket:
- Legyen óvatos, amikor módosítja a robots.txt: ez a fájl lehetővé teheti a webhely nagy részeinek hozzáférhetetlenségét a keresőmotorok számára.
- A robots.txt fájlnak a webhely gyökérzetében kell lennie (pl.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpvagyhttps). - A különböző keresőmotorok eltérően értelmezik az irányelveket. Alapértelmezés szerint mindig az első egyező irányelv nyer. De a Google és a Bing esetében a specifikusság nyer.
- Kerülje a feltérképezés késleltetésének irányát a keresőmotorok számára.
Mi az a robots.txt fájl?
A robots.txt fájl elmondja a keresőmotoroknak, hogy mik az Ön webhelyének elköteleződési szabályai. A SEO elvégzésének nagy része a megfelelő jelek küldése a keresőmotoroknak, a robots.txt pedig az egyik módja annak, hogy kommunikálják a feltérképezési beállításokat a keresők felé.
2019-ben már eléggé láthattuk néhány fejlesztés a robots.txt szabvány körül: A Google a Robots Exclusion Protocol kiterjesztését javasolta, és nyílt forráskódú a robots.txt elemzőjét.
TL; DR
- A Google robotjai A .txt tolmács meglehetősen rugalmas és meglepően elnéző.
- Zavaros irányelvek esetén a Google hibát követ el a biztonságos oldalon, és feltételezi, hogy a szakaszokat korlátozás helyett korlátozni kell.
A keresőmotorok rendszeresen ellenőrzik a webhely robots.txt fájlját, hogy vannak-e útmutatások a webhely feltérképezéséhez. Ezeket az utasításokat direktíváknak hívjuk.
Ha nincs robots.txt fájl, vagy ha nincsenek alkalmazható irányelvek, akkor a keresőmotorok az egész webhelyet feltérképezik.
Bár az összes nagy keresőmotor tiszteletben tartja a robots.txt fájlt, a keresőmotorok dönthetnek úgy, hogy figyelmen kívül hagyják a robots.txt fájlt (egyes részeit). Míg a robots.txt fájlban található irányelvek erős jelet jelentenek a keresőmotorok számára, fontos megjegyezni, hogy a robots.txt fájl opcionális irányelvek halmaza a keresők számára, nem pedig megbízás.

A robots.txt a legérzékenyebb fájl a SEO univerzumban. Egyetlen karakter egy egész webhelyet felbonthat.
Terminológia a robots.txt fájl körül
A robots.txt fájl a robotkizárási szabvány megvalósítása, vagy más néven a robotok kizárási protokollja.
Miért érdekelne a robots.txt?
A robots.txt SEO szempontból alapvető szerepet játszik. Megmondja a keresőmotoroknak, hogyan tudják a legjobban feltérképezni az Ön webhelyét.
A robots.txt fájl használatával megakadályozhatja, hogy a keresőmotorok hozzáférjenek a webhely bizonyos részeihez, megakadályozza az ismétlődő tartalmat, és hasznos tippeket adjon a keresőmotoroknak. hatékonyabban tudja feltérképezni a webhelyét.
Legyen óvatos, ha változtat a robots.txt fájlon: ennek a fájlnak az lehet a lehetősége, hogy webhelyének nagy részét elérhetetlenné tegye a keresők számára.

A Robots.txt fájlt gyakran használják az ismétlődő tartalmak csökkentésére, ezáltal megölve a belső linkelést, ezért legyen nagyon óvatos vele. Azt tanácsolom, hogy csak olyan fájlokhoz vagy oldalakhoz használja, amelyeket a keresőmotoroknak soha nem szabad látniuk, vagy ha jelentősen befolyásolhatják a feltérképezést, ha beengedik őket. Gyakori példák: olyan bejelentkezési területek, amelyek sok különböző URL-t generálnak, tesztelési területek, vagy ahol többféle szempontú navigáció létezhet. És ügyeljen arra, hogy a robots.txt fájlban ellenőrizze az esetleges problémákat vagy változásokat.

A robots.txt fájlokkal látott problémák nagy része három csoportba esik:
- A helyettesítő karakterek helytelen kezelése. Meglehetősen gyakran előfordul, hogy a webhely olyan részeit zárják le, amelyeket le akartak zárni. Néha, ha nem vagy óvatos, az irányelvek is ütközhetnek egymással.
- Valaki, például egy fejlesztő, kék színből változtatott (gyakran új kód megnyomásakor), és akaratlanul is megváltozott a robotok.txt az ön tudta nélkül.
- Olyan irányelvek felvétele, amelyek nem tartoznak a robots.txt fájlba. A Robots.txt webes szabvány, és kissé korlátozott. Gyakran látom, hogy a fejlesztők olyan irányelveket készítenek, amelyek egyszerűen nem fognak működni (legalábbis a bejárók tömeges többsége számára). Néha ez ártalmatlan, néha nem annyira.
példa
Nézzünk meg egy példát ennek szemléltetésére:
Ön e-kereskedelmi webhelyet üzemeltet, és a látogatók egy szűrővel gyorsan kereshetnek a termékeiben. Ez a szűrő olyan oldalakat hoz létre, amelyek alapvetően ugyanazt a tartalmat mutatják, mint a többi oldal. Ez kiválóan működik a felhasználók számára, de összezavarja a keresőmotorokat, mert duplikált tartalmat hoz létre.
Nem szeretné, hogy a keresőmotorok indexeljék ezeket a szűrt oldalakat, és értékes idejüket pazarolják ezekre az URL-ekre szűrt tartalommal. Ezért be kell állítania a Disallow szabályokat, hogy a keresőmotorok ne férjenek hozzá ezekhez a szűrt termékoldalakhoz.
Az ismétlődő tartalmak megakadályozása a gyűjtő URL-vel vagy a meta robot címke, azonban ezek nem foglalkoznak azzal, hogy a keresőmotorok csak a fontos oldalakat tudják feltérképezni.
A gyűjtő URL vagy a meta robot címke használata nem fogja megakadályozni, hogy a keresőmotorok feltérképezzék ezeket az oldalakat. Csak megakadályozza, hogy a keresőmotorok megjelenítsék ezeket az oldalakat a keresési eredmények között. Mivel a keresőmotoroknak korlátozott idő áll rendelkezésre egy webhely feltérképezésére, ezt az időt olyan oldalakra kell fordítani, amelyeken meg akarnak jelenni a keresőmotorokban.
A helytelenül beállított robots.txt fájl hátráltathatja SEO teljesítményét. Azonnal ellenőrizze, hogy ez a helyzet-e a webhelyén!

Ez egy nagyon egyszerű eszköz, de a robots.txt fájl sok problémát okozhat, ha nincs megfelelően konfigurálva, különösen nagyobb weboldalakhoz. Nagyon könnyű hibákat elkövetni, például blokkolni egy teljes webhelyet egy új terv vagy a CMS bevezetése után, vagy nem blokkolni a webhely azon részeit, amelyeknek privátnak kell lenniük. Nagyobb webhelyeknél nagyon fontos a Google hatékony feltérképezése, és a jól strukturált robots.txt fájl elengedhetetlen eszköz ebben a folyamatban.
Időt kell szánnia annak megértésére, hogy a webhely mely szakaszait lehet a legjobban távol tartani. a Google-tól, hogy az erőforrásuk lehető legnagyobb részét az Ön számára igazán fontos oldalak feltérképezésével töltsék el.
Hogyan néz ki egy robots.txt fájl?
Példa arra, hogy milyen lehet egy egyszerű robots.txt fájl egy WordPress webhelyhez kinézet:
Magyarázzuk el a robots.txt fájl anatómiáját a fenti példa alapján:
- User-agent: a
user-agentjelzi, hogy melyik keresésre van szükség a következő irányelveket jelentik. -
*: ez azt jelzi, hogy az irányelveket az összes keresőmotor számára jelentik. -
Disallow: ez egy olyan irányelv, amely jelzi, hogy milyen tartalom nem érhető el auser-agentszámára. -
/wp-admin/: ez az apath, amely auser-agentszámára nem érhető el.
Összefoglalva: ez a robots.txt fájl azt mondja az összes keresőmotornak, hogy maradjanak távol a /wp-admin/ könyvtárból.
Elemezzük a különböző A robots.txt fájlok összetevői részletesebben:
- User-agent
- Letiltás
- Engedélyezés
- Webhelytérkép
- Feltérképezési késleltetés
User-agent a robots.txt fájlban
Minden keresőmotornak azonosítania kell magát egy user-agent. A Google robotjai például Googlebot, a Yahoo robotjai Slurp és Bing robotjai BingBot és így tovább.
A user-agent rekord meghatározza egy irányelvcsoport kezdetét. Az első user-agent és a következő user-agent rekord között lévő összes irányelv az első user-agent.
Az irányelvek vonatkozhatnak bizonyos felhasználói ügynökökre, de alkalmazhatók minden felhasználói ügynökre is. Ebben az esetben helyettesítő karaktert használunk: User-agent: *.
Az irányelv tiltása a robots.txt fájlban
Megmondhatja a keresőmotoroknak, hogy ne férjenek hozzá webhelyének bizonyos fájljai, oldalai vagy szakaszai. Ez a Disallow irányelv használatával történik. A Disallow irányelvet követi a path, amelyhez nem szabad hozzáférni. Ha nincs megadva path, az irányelv figyelmen kívül marad.
Példa
Ebben a példában az összes keresőmotornak azt mondják, hogy ne lépjen be a /wp-admin/ könyvtárba.
Irányelv engedélyezése a robots.txt fájlban
A Allow irányelv egy Disallow irányelv ellensúlyozására szolgál. A Allow irányelvet a Google és a Bing támogatja. A Allow és a Disallow irányelvek együttes használatával elmondhatja a keresőmotoroknak, hogy hozzáférhetnek egy adott fájlhoz vagy oldalhoz egy könyvtárban, amelyet egyébként nem engedélyeztek. A Allow irányelvet követi a hozzáférhető path. Ha nincs megadva path, az irányelv figyelmen kívül marad.
Példa
A fenti példában minden keresőmotor nem férhet hozzá a /media/ könyvtár, kivéve a /media/terms-and-conditions.pdf fájlt.
Fontos: Allow és Disallow irányelveket együtt, ügyeljen arra, hogy ne használjon helyettesítő karaktereket, mivel ez ellentmondó irányelvekhez vezethet.
Példa ellentmondó irányelvekre
A keresőmotorok nem tudják, mit kezdjenek az URL-lel . Számukra nem világos, hogy hozzáférhetnek-e hozzájuk. Ha az irányelvek nem világosak a Google számára, akkor a legkevésbé korlátozó irányelveket alkalmazzák, ami ebben az esetben azt jelenti, hogy valójában hozzáférnének a
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
A Robots.txt egyike azoknak a funkcióknak, amelyeket a leggyakrabban helytelenül hajtottam végre, tehát nem blokkolja azt, amit blokkolni akartak, vagy többet blokkol, mint várták, és negatív hatással van a weboldalukra. A Robots.txt egy nagyon hatékony eszköz, de túl gyakran hibásan állítja be.
Helyettesítő karakter használata *
A helyettesítő karakter nemcsak a user-agent meghatározásához használható, hanem egyezik az URL-ekkel. A helyettesítő karaktert a Google, a Bing, a Yahoo és az Ask támogatja.
Példa
A fenti példában az összes keresőmotor nem engedélyez hozzáférést kérdőjelet tartalmazó URL-ekhez (?).

Fejlesztők vagy a webhelytulajdonosok gyakran úgy gondolják, hogy a robots.txt fájlban mindenféle szabályos kifejezést felhasználhatnak, míg a mintaillesztésnek csak nagyon korlátozott része érvényes – például helyettesítő karakterek >). Úgy tűnik, hogy a .htaccess fájlok és a robots.txt fájlok időnként összetéveszthetők.
Az URL végének használata $
Az URL végének megjelölésére használhatja a dollárjelet ($) a path végén.
Példa
A fenti példában a keresőmotorok nem férhetnek hozzá az összes .php végződésű URL-hez . URL-ek paraméterekkel, pl. A nem lenne tiltva, mivel az URL nem ér véget a .php után.
Webhelytérkép hozzáadása a robotokhoz. txt
Annak ellenére, hogy a robots.txt fájlt azért találták ki, hogy a keresőmotoroknak megmondja, milyen oldalakat nem szabad feltérképeznie, a robots.txt fájlt arra is felhasználhatja, hogy a keresőmotorokat az XML-webhelytérképre irányítsa. Ezt támogatja a Google, a Bing, a Yahoo és az Ask.
Az XML-webhelytérképre abszolút URL-ként kell hivatkozni. Az URL-nek nem feltétlenül ugyanazon a gazdagépen kell lennie, mint a robots.txt fájl.
Az XML-webhelytérképre való hivatkozás a robots.txt fájlban az egyik legjobb gyakorlat, amelyet mindig javasoljuk, annak ellenére, hogy lehet, hogy már elküldte XML-webhelytérképét a Google Search Console-ban vagy a Bing Webmestereszközökben. Ne feledje, hogy vannak további keresőmotorok.
Felhívjuk figyelmét, hogy a robots.txt fájlban több XML-webhelytérképre is hivatkozhatunk.
Példák
Többszörös A robots.txt fájlban definiált XML-webhelytérképek:
Egyetlen XML-webhelytérkép, amelyet egy robotok határoztak meg.txt fájl:
A fenti példa azt mondja az összes keresőnek, hogy ne érjék el a /wp-admin/ könyvtárat, és hogy az XML-webhelytérkép megtalálható a
Comments are preceded by a # címen, és vagy a vonal elejére, vagy az ugyanazon a vonalon található irányelv után helyezhető el. A # után mindent figyelmen kívül hagyunk. Ezek a megjegyzések csak emberek számára szólnak.
1. Példa
2. példa
A fenti példák ugyanazt az üzenetet közlik.
Feltérképezési késleltetés a robots.txt fájlban
A Crawl-delay irányelv egy nem hivatalos irányelv, amely megakadályozza a túl sok kéréssel rendelkező szerverek túlterhelését. Ha a keresőmotorok képesek túlterhelni egy szervert, az Crawl-delay hozzáadása a robots.txt fájlhoz csak ideiglenes javítás. A helyzet az, hogy webhelye gyenge tárhelykörnyezetben működik, és / vagy webhelye nincs megfelelően konfigurálva, és ezt a lehető leghamarabb meg kell javítania.
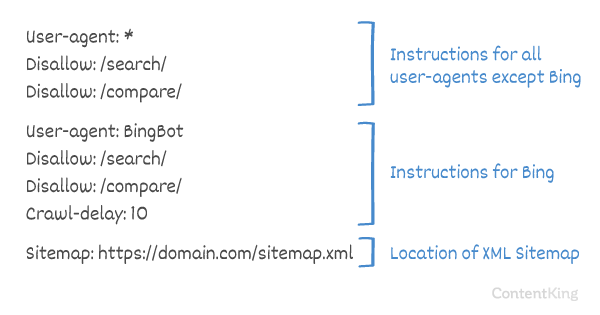
A keresőmotorok által az Crawl-delay kezelésének módja eltér. Az alábbiakban elmagyarázzuk, hogyan kezelik a nagy keresők.
Feltérképezés késleltetése és a Google
A Google robotja, a Googlebot nem támogatja a Crawl-delay irányelv, ezért ne foglalkozzon a Google feltérképezési késleltetésének meghatározásával.
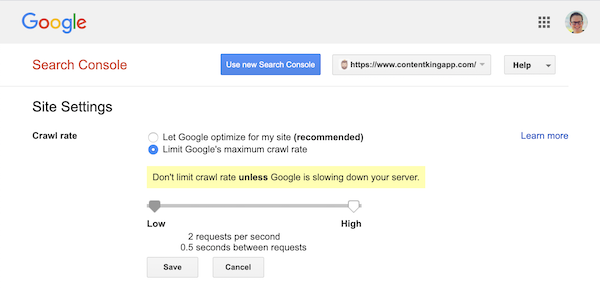
A Google azonban támogatja a feltérképezési gyakoriság (vagy a „kérési arány”) meghatározását, ha úgy akarja ) a Google Search Console-ban.
- Jelentkezzen be a régi Google Search Console-ba.
- Válassza ki a kívánt webhelyet meg szeretné határozni a feltérképezési sebességet.
- Csak egy beállítást módosíthat:
Crawl rate, egy csúszkával, ahol beállíthatja a preferált feltérképezési sebességet. Alapértelmezés szerint a feltérképezés gyakorisága “Hagyja, hogy a Google optimalizáljon a webhelyemre (ajánlott)” értékre van állítva.
Így néz ki a Google Search Console:
Feltérképezés késleltetése és Bing, Yahoo és Yandex
Bing, Yahoo és Yandex mind támogatják a Crawl-delay irányelv a weboldal feltérképezésének fojtására. A bejárási késés értelmezése azonban kissé eltér, ezért mindenképpen ellenőrizze dokumentációjukat:
- Bing és Yahoo
- Yandex
A Crawl-delay irányelvet közvetlenül a Disallow vagy Allow irányelvek után kell elhelyezni.
Példa:
Feltérképezés-késleltetés és a Baidu
A Baidu nem támogatja a crawl-delay irányelvet, azonban lehetséges a Baidu Webmestereszközök-fiók regisztrálása amely a feltérképezés gyakoriságát szabályozhatja, hasonlóan a Google Search Console-hoz.
Mikor kell használni a robots.txt fájlt?
Javasoljuk, hogy mindig használjon robots.txt fájlt. Abszolút nem árt, ha van ilyen, és remek hely a keresőmotorok irányelveinek átadására, hogy miként tudják a legjobban feltérképezni az Ön webhelyét.

A robots.txt hasznos lehet annak megakadályozására, hogy a webhely bizonyos területeit vagy dokumentumait feltérképezzék és indexeljék. Ilyenek például az átmeneti webhely vagy a PDF-fájlok. Gondosan tervezze meg, hogy mit kell indexelnie a keresőmotoroknak, és ne feledje, hogy a robots.txt fájlon keresztül elérhetetlenné tett tartalmat továbbra is megtalálhatják a keresőmotorok robotjai, ha a webhely más területeiről vannak linkelve. “00b8013abe”>
Robots.txt bevált gyakorlatok
A robots.txt bevált módszereit az alábbiak szerint osztályozzuk:
- Hely és fájlnév
- Elsőbbségi sorrend
- Robotonként csak egy irányelvcsoport
- Legyen a lehető legpontosabb
- Az összes robotra vonatkozó irányelv, ugyanakkor tartalmazzon egy adott robotra vonatkozó irányelveket is.
- Robots.txt fájl minden (al) tartományhoz.
- ütköző irányelvek: robots.txt és Google Search Console
- Figyelje a robots.txt fájlt
- Ne használja a noindex-et a robots.txt fájlban
- Az UTF-8 BOM megakadályozása a robots.txt fájlban
Hely és fájlnév
A robots.txt fájlt mindig a th e root egy webhelyen (a gazdagép legfelső szintű könyvtárában), és a robots.txt fájlnevet viseli, például: . Vegye figyelembe, hogy a robots.txt fájl URL-je, mint bármely más URL, megkülönbözteti a kis- és nagybetűket.
Ha a robots.txt fájl nem található az alapértelmezett helyen, a keresőmotorok feltételezik, hogy nincsenek irányelvek, és feltérképezik az Ön webhelyét.
Elsőbbségi sorrend
Fontos megjegyezni, hogy a keresőmotorok eltérően kezelik a robots.txt fájlokat. Alapértelmezés szerint mindig az első egyező irányelv nyer.
A Google és a Bing esetében azonban a specifitás nyer. Például: egy Allow irányelv nyer egy Disallow direktívát, ha a karakterhossza hosszabb.
Példa
A Az összes keresőmotor fölött a példa, beleértve a Google-t és a Binget sem, hozzáférhet a /about/ könyvtárhoz, kivéve a /about/company/ alkönyvtárat.
példa
A fenti példában a Google és a Bing kivételével az összes keresőmotor nem férhet hozzá a /about/ könyvtárhoz. Ez tartalmazza a /about/company/ könyvtárat.
A Google és a Bing hozzáférése engedélyezett, mert a Allow irányelv hosszabb, mint a Disallow irányelv.
Robotonként csak egy irányelvcsoport
Keresőmotoronként csak egy irányelvcsoportot határozhat meg. Ha egy keresőmotorhoz több irányelvcsoport tartozik, megzavarja őket.
Legyen a lehető legkonkrétabb
A Disallow irányelv részleges egyezéseket vált ki, mivel jól. Legyen a lehető legpontosabb a Disallow irányelv meghatározásakor, hogy megakadályozza a fájlokhoz való hozzáférés akaratlan tiltását.
Példa:
A fenti példa nem engedélyezi a keresőmotorok hozzáférését a következőkhöz:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Irányelvek minden robot számára, beleértve az adott robotra vonatkozó irányelveket is
Robot esetén csak az irányelvek egy csoportja érvényes. Ha az összes robot számára szánt irányelveket egy adott robotra vonatkozó irányelvek követik, akkor csak ezeket a speciális irányelveket veszik figyelembe. Ahhoz, hogy az adott robot az összes robotra vonatkozó irányelveket is kövesse, meg kell ismételnie ezeket az irányelveket az adott robotra vonatkozóan.
Nézzünk meg egy példát, amely ezt világossá teszi:
Példa
Ha nem szeretné, hogy a googlebot hozzáférjen a /secret/ és a /not-launched-yet/ fájlokhoz, akkor meg kell ismételnie ezeket az irányelveket a googlebot konkrétan:
Felhívjuk figyelmét, hogy a robots.txt fájlja nyilvánosan elérhető. Az ott található webhelyrészek letiltását támadási vektorként használhatják rosszindulatú szándékkal rendelkező emberek.

A Robots.txt fájl veszélyes lehet. Nem csak a keresőmotoroknak mondod, ahol nem akarod, hogy megnézzék őket, hanem azt is, hogy hol rejtegeted a piszkos titkaid.
Robots.txt fájl minden (al) tartományhoz
Csak a Robots.txt irányelvekhez alkalmazza azt az (al) tartományt, amelyen a fájlt tárolják.
Példák
érvényes a , de vagy
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / esetén nem
Ezért létrehoztuk a robots.txt változáskövetését és riasztását.
Mindig látjuk: a robots.txt fájlok a digitális marketing ismerete nélkül változnak csapat. Ne légy az a személy. Kezdje figyelemmel kísérni a robots.txt fájlt, és most figyelmeztetéseket kap, ha megváltozik!
Ne használja a noindexet a robots.txt fájlban
Évek óta a Google már nyíltan ajánlotta a nem hivatalos noindex irányelv alkalmazását. 2019. szeptember 1-jétől azonban a Google abbahagyta teljes támogatását.
A nem hivatalos noindex irányelv soha nem működött a Bingben, amit Frédéric Dubut megerősített ebben a tweetben:
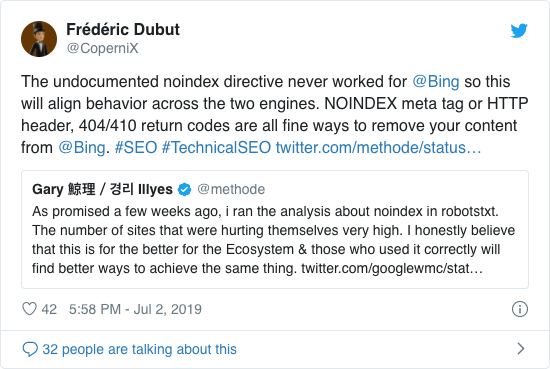
A keresőmotoroknak az a legjobb módja, hogy jelezzük az oldalakat nem indexeljük, ha a meta robots taget vagy az X-Robots-Tag-et használjuk .
Az UTF-8 BOM megakadályozása a robots.txt fájlban
A BOM a bájt sorrendet jelöli, egy láthatatlan karaktert egy a szöveges fájl Unicode kódolásának jelzésére használt fájl.
Bár a Google kijelenti, hogy figyelmen kívül hagyja az opcionális Unicode bájt sorrendjelet a robots.txt fájl elején, javasoljuk, hogy akadályozza meg az “UTF-8 BOM” -ot, mert láttuk, hogy ez problémát okoz a a robots.txt fájlt a keresőmotorok.
Annak ellenére, hogy a Google azt mondja, hogy tudnak vele megbirkózni, az alábbi két oka van az UTF-8 BOM megakadályozásának:
- Ön nem nem akarja, hogy bármilyen kétség merüljön fel a keresőmotorok felé történő feltérképezéssel kapcsolatos preferenciáiról.
- Vannak más keresőmotorok is, amelyek nem biztos, hogy olyan elnézőek, mint a Google állítja.
Robots.txt példák
Ebben a fejezetben a robots.txt fájl példák széles skáláját ismertetjük:
- Minden robotnak hozzáférést kell engedélyeznie mindenhez
- Minden robot hozzáférésének megtiltása mindenhez
- Az összes Google robotnak nincs hozzáférése
- Az összes Google robotnak, a Googlebot hírek kivételével, nincs hozzáférése
- A Googlebotnak és a Slurp-nak nincs hozzáférése
- Az összes robotnak nincs hozzáférése kettőhöz könyvtárak
- Az összes robotnak nincs hozzáférése egy adott fájlhoz
- A Googlebot nem fér hozzá az / admin / fájlhoz, a Slurp pedig nem fér hozzá a / private / li fájlhoz >
- Robots.txt fájl a WordPress számára
- Robots.txt fájl a Magento számára
Minden robot számára hozzáférés engedélyezése mindenhez
Többféle lehetőség van a keresőmotorok megadásához az összes fájlhoz hozzáférhetnek:
Vagy üres robots.txt fájl vagy egyáltalán nincs robots.txt fájl.
Tiltsa le az összes robot hozzáférését mindenhez
A példa Az alábbi robots.txt azt mondja az összes keresőmotornak, hogy ne érje el a teljes webhelyet:
Felhívjuk figyelmét, hogy csak EGY extra karakter jelentheti a különbséget.
Az összes Google robotnak nincs hozzáférése
Felhívjuk figyelmét, hogy a Googlebot letiltásakor ez az összes Googlebotra érvényes. Ez magában foglalja azokat a Google robotokat is, amelyek például híreket (googlebot-news) és képeket (googlebot-images) keresnek.
Mind A Google robotok, a Googlebot hírek kivételével, nem rendelkeznek hozzáféréssel
A Googlebotnak és a Slurp-nak nincs hozzáférése
Minden robotnak nincs hozzáférése két könyvtárhoz
Minden robotnak nincs hozzáférése egy adott fájlhoz
A Googlebot nem rendelkezik hozzáféréssel a / Az admin / és a Slurp nem fér hozzá a / private /
Robots.txt fájl a WordPress számára
Az alábbi robots.txt fájl kifejezetten a WordPress alkalmazásra van optimalizálva, feltételezve:
- Nem akarja, hogy feltérképezze az adminisztrátori szakaszát.
- Nem akarja, hogy a belső keresési eredményoldalait feltérképezze.
- Nem szeretné, hogy a címkéje és a szerzői oldalai feltérképezzék.
- Nem szabad ne akarja feltérképezni a 404-es oldalát.
Felhívjuk figyelmét, hogy ez a robots.txt fájl a legtöbb esetben működik, de mindig állítsa be és tesztelje, hogy biztosan megfelel-e az Ön pontos helyzet.
Robots.txt fájl a Magento számára
Az alábbi robots.txt fájl kifejezetten a Magento számára van optimalizálva, és belső keresési eredményeket, bejelentkezési oldalakat, munkamenet-azonosítókat és szűrt eredményeket készít price, color, material és size kritériumok nem érhetők el a robotok számára.
Felhívjuk figyelmét, hogy ez a robots.txt fájl a legtöbb Magento áruházban működik, de Ön mindig ki kell igazítania és tesztelnie, hogy megbizonyosodjon arról, hogy az megfelel-e az Ön helyzetének.
Mindig arra törekszem, hogy minden webhelyen letiltsam a belső keresési eredményeket a robots.txt fájlban, mert az ilyen típusú keresési URL-ek végtelen és végtelen szóközök. Nagyon sok lehetőség van arra, hogy a Googlebot bejárjon egy robotba.
Milyen korlátozások vannak a robots.txt fájlban?
A Robots.txt fájl irányelveket tartalmaz
Annak ellenére, hogy a keresés a robots.txt fájlt jól tiszteletben tartja motorok, ez még mindig irányelv és nem meghatalmazás.
A keresési eredmények között továbbra is megjelenő oldalak
Azok az oldalak, amelyek a robotok miatt a keresőmotorok számára nem elérhetők.txt, de vannak linkjeik, amelyek továbbra is megjelennek a keresési eredmények között, ha egy feltérképezett oldalról vannak linkelve. Példa erre:

Ezeket az URL-eket a Google Search Console URL-eltávolító eszközével lehet eltávolítani a Google-ból. Felhívjuk figyelmét, hogy ezeket az URL-eket csak ideiglenesen “rejtik”. Annak érdekében, hogy ne jelenjenek meg a Google eredményoldalain, 180 naponta kérelmet kell benyújtania az URL-ek elrejtésére.

A robots.txt segítségével blokkolhatja a nemkívánatos és valószínűleg káros társult taghivatkozásokat. ne használja a robots.txt fájlt annak megakadályozására, hogy a keresőmotorok indexeljék a tartalmat, mivel ez elkerülhetetlenül kudarcot vall. Ehelyett szükség esetén alkalmazza a noindex robot-irányelveket.
A Robots.txt fájl legfeljebb 24 órás gyorsítótárazott.
A Google jelezte, hogy egy robot A .txt fájl általában 24 órán keresztül van gyorsítótárban. Fontos, hogy ezt figyelembe vegye, amikor módosításokat hajt végre a robots.txt fájlban.
Nem világos, hogy más keresőmotorok hogyan kezelik a robots.txt fájl gyorsítótárát. , de általában a legjobb elkerülni a robots.txt fájl gyorsítótárazását oid keresőmotorok a szükségesnél hosszabb ideig tartanak ahhoz, hogy képesek legyenek változtatásokat felvenni.
Robots.txt fájlméret
A robots.txt fájlok esetében a Google jelenleg 500 kibibájtos fájlméret-korlátozást támogat (512 kilobájt). A maximális fájlméretet meghaladó tartalmat figyelmen kívül lehet hagyni.
Nem világos, hogy más keresőmotorok rendelkeznek-e maximális fájlmérettel a robots.txt fájlokhoz.
Gyakran feltett kérdések a robots.txt fájlról
🤖 Hogyan néz ki egy robots.txt példa?
Íme egy példa a robots.txt tartalmára: User-agent: * Disallow:. Ez azt mondja az összes robotnak, hogy mindenhez hozzáférhetnek.
⛔ Mit csinál a Disallow all művelet a robots.txt fájlban?
Amikor a robots.txt fájlt “Allallow all” -ra állítja, lényegében arra szólítja fel a robotokat, hogy tartsák távol magukat. Semmilyen robotnak, köztük a Google-nak sem engedélyezett a hozzáférése az Ön webhelyéhez. Ez azt jelenti, hogy nem fogják tudni feltérképezni, indexelni és rangsorolni az Ön webhelyét. Ez az organikus forgalom jelentős csökkenéséhez vezet.
✅ Mit csinál az All All engedélyezése a robots.txt fájlban?
Ha a robots.txt fájlt „Allow all” értékre állítja, akkor azt mondja minden robotnak, hogy hozzáférhetnek a webhely minden URL-jéhez. Egyszerűen nincsenek szabályok a végrehajtásra. Felhívjuk figyelmét, hogy ez egyenértékű azzal, ha üres a robots.txt fájl, vagy egyáltalán nincs robots.txt.
🤔 Mennyire fontos a robots.txt a SEO számára?
általában a robots.txt fájl nagyon fontos SEO célokból. Nagyobb weboldalak esetében a robots.txt elengedhetetlen ahhoz, hogy a keresőmotorok nagyon világos utasításokat adjanak arról, hogy milyen tartalomhoz ne férjenek hozzá.