Un robot Il file .txt contiene le direttive per i motori di ricerca. Puoi utilizzarlo per impedire ai motori di ricerca di eseguire la scansione di parti specifiche del tuo sito Web e per fornire ai motori di ricerca suggerimenti utili su come eseguire al meglio la scansione del tuo sito web. Il file robots.txt gioca un ruolo importante nella SEO.
Quando si implementa il file robots.txt, tenere a mente le seguenti best practice:
- Fai attenzione quando apporti modifiche al tuo robots.txt: questo file può potenzialmente rendere inaccessibili ai motori di ricerca gran parte del tuo sito web.
- Il file robots.txt dovrebbe risiedere nella radice del tuo sito web (ad es.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpohttps). - Diversi motori di ricerca interpretano le direttive in modo diverso. Per impostazione predefinita, la prima direttiva corrispondente vince sempre. Tuttavia, con Google e Bing, la specificità vince.
- Evita il più possibile di utilizzare la direttiva sul ritardo della scansione per i motori di ricerca.
Che cos’è un file robots.txt?
Un file robots.txt indica ai motori di ricerca quali sono le regole di coinvolgimento del tuo sito web. Una parte importante del fare SEO consiste nell’inviare i segnali giusti ai motori di ricerca e il file robots.txt è uno dei modi per comunicare le tue preferenze di scansione ai motori di ricerca.
Nel 2019, abbiamo visto abbastanza alcuni sviluppi intorno allo standard robots.txt: Google ha proposto un’estensione del Robots Exclusion Protocol e ha reso open source il suo parser robots.txt.
TL; DR
- I robot di Google L’interprete .txt è abbastanza flessibile e sorprendentemente indulgente.
- In caso di direttive di confusione, Google va sul sicuro e presume che le sezioni debbano essere limitate anziché illimitate.
I motori di ricerca controllano regolarmente il file robots.txt di un sito web per vedere se ci sono istruzioni per la scansione del sito web. Chiamiamo queste istruzioni direttive.
Se non è presente alcun file robots.txt o se non sono presenti direttive applicabili, i motori di ricerca eseguiranno la scansione dell’intero sito web.
Sebbene tutti i principali motori di ricerca rispettino il file robots.txt, i motori di ricerca possono scegliere di ignorare (parti del) file robots.txt. Sebbene le direttive nel file robots.txt siano un segnale forte per i motori di ricerca, è importante ricordare che il file robots.txt è un insieme di direttive facoltative per i motori di ricerca piuttosto che un mandato.

Il file robots.txt è il file più sensibile nell’universo SEO. Un singolo carattere può danneggiare un intero sito.
Terminologia relativa al file robots.txt
Il file robots.txt è l’implementazione dello standard di esclusione dei robot, o anche chiamato il protocollo di esclusione dei robot.
Perché dovrebbe interessarti al file robots.txt?
Il file robots.txt gioca un ruolo essenziale da un punto di vista SEO. Indica ai motori di ricerca come possono eseguire al meglio la scansione del tuo sito web.
Utilizzando il file robots.txt puoi impedire ai motori di ricerca di accedere a determinate parti del tuo sito web, impedire la duplicazione di contenuti e fornire ai motori di ricerca utili suggerimenti su come può eseguire la scansione del tuo sito web in modo più efficiente.
Fai attenzione quando apporti modifiche al tuo file robots.txt: questo file ha il potenziale per rendere gran parte del tuo sito web inaccessibile ai motori di ricerca.

Robots.txt è spesso sovrautilizzato per ridurre i contenuti duplicati, quindi uccidendo il collegamento interno quindi stai molto attento con esso. Il mio consiglio è di usarlo sempre e solo per file o pagine che i motori di ricerca non dovrebbero mai vedere o che possono avere un impatto significativo sulla scansione se autorizzati. Esempi comuni: aree di accesso che generano molti URL diversi, aree di test o dove può esistere una navigazione sfaccettata. E assicurati di monitorare il tuo file robots.txt per eventuali problemi o modifiche.

La maggior parte dei problemi riscontrati con i file robots.txt rientra in tre segmenti:
- La cattiva gestione dei caratteri jolly. È abbastanza comune vedere bloccate parti del sito che dovevano essere bloccate. A volte, se non stai attento, le direttive possono anche entrare in conflitto tra loro.
- Qualcuno, come uno sviluppatore, ha apportato una modifica improvvisa (spesso quando si inserisce un nuovo codice) e l’ha inavvertitamente alterata il file robots.txt a tua insaputa.
- L’inclusione di direttive che non appartengono a un file robots.txt. Robots.txt è uno standard web ed è piuttosto limitato. Spesso vedo sviluppatori creare direttive che semplicemente non funzionano (almeno per la maggior parte dei crawler). A volte è innocuo, a volte non così tanto.
Esempio
Diamo un’occhiata a un esempio per illustrare questo:
Tu stai eseguendo un sito di e-commerce ei visitatori possono utilizzare un filtro per cercare rapidamente tra i tuoi prodotti. Questo filtro genera pagine che sostanzialmente mostrano lo stesso contenuto di altre pagine. Funziona alla grande per gli utenti, ma confonde i motori di ricerca perché crea contenuti duplicati.
Non vuoi che i motori di ricerca indicizzino queste pagine filtrate e sprechino il loro tempo prezioso su questi URL con contenuti filtrati. Pertanto, dovresti impostare le Disallow regole in modo che i motori di ricerca non accedano a queste pagine di prodotto filtrate.
La prevenzione di contenuti duplicati può essere eseguita anche utilizzando l’URL canonico o il tag meta robots, tuttavia questi non indirizzano i motori di ricerca a eseguire la scansione solo delle pagine che contano.
L’uso di un URL canonico o di un tag meta robots non impedirà ai motori di ricerca di eseguire la scansione di queste pagine. Impedirà solo ai motori di ricerca di mostrare queste pagine nei risultati di ricerca. Poiché i motori di ricerca hanno un tempo limitato per eseguire la scansione di un sito web, questa volta dovrebbe essere dedicata alle pagine che desideri vengano visualizzate nei motori di ricerca.
Un file robots.txt configurato in modo errato potrebbe ostacolare le tue prestazioni SEO. Controlla subito se questo è il caso del tuo sito web!

È uno strumento molto semplice, ma un file robots.txt può causare molti problemi se non è configurato correttamente, in particolare per siti Web più grandi. È molto facile commettere errori come bloccare un intero sito dopo che è stato implementato un nuovo design o CMS o non bloccare sezioni di un sito che dovrebbero essere private. Per i siti web più grandi, è molto importante garantire la scansione efficiente di Google e un file robots.txt ben strutturato è uno strumento essenziale in questo processo.
È necessario dedicare tempo per capire quali sezioni del tuo sito è meglio tenere lontane da Google in modo che spendano la maggior parte delle loro risorse possibile per la scansione delle pagine che ti interessano veramente.
Che aspetto ha un file robots.txt?
Un esempio di cosa può fare un semplice file robots.txt per un sito Web WordPress ha questo aspetto:
Spieghiamo l’anatomia di un file robots.txt in base all’esempio precedente:
- User-agent:
user-agentindica per quale ricerca motori si intendono le direttive che seguono. -
*: questo indica che le direttive si intendono per tutti i motori di ricerca. -
Disallow: questa è una direttiva che indica quali contenuti non sono accessibili aluser-agent. -
/wp-admin/: questo èpathinaccessibile peruser-agent.
In sintesi: questo file robots.txt indica a tutti i motori di ricerca di rimanere fuori dalla directory /wp-admin/.
Analizziamo i diversi componenti dei file robots.txt in modo più dettagliato:
- User-agent
- Non consentire
- Consenti
- Sitemap
- Ritardo della scansione
Agente utente in robots.txt
Ogni motore di ricerca deve identificarsi con un user-agent. I robot di Google si identificano come Googlebot ad esempio, i robot di Yahoo come Slurp e il robot di Bing come BingBot e così via.
Il record user-agent definisce l’inizio di un gruppo di direttive. Tutte le direttive tra il primo user-agent e il successivo user-agent record vengono trattate come direttive per il primo user-agent.
Le direttive possono essere applicate a user-agent specifici, ma possono anche essere applicabili a tutti gli user-agent. In tal caso, viene utilizzato un carattere jolly: User-agent: *.
Direttiva Disallow in robots.txt
Puoi dire ai motori di ricerca di non accedere determinati file, pagine o sezioni del tuo sito web. Questa operazione viene eseguita utilizzando la direttiva Disallow. La direttiva Disallow è seguita dalla path a cui non è possibile accedere. Se non viene definito alcun path, la direttiva viene ignorata.
Esempio
In questo esempio a tutti i motori di ricerca viene detto di non accedere alla directory /wp-admin/.
Consenti direttiva in robots.txt
La direttiva Allow viene utilizzata per contrastare una direttiva Disallow. La direttiva Allow è supportata da Google e Bing. Utilizzando le direttive Allow e Disallow puoi indicare ai motori di ricerca che possono accedere a un file o a una pagina specifici all’interno di una directory altrimenti non consentita. La direttiva Allow è seguita dalla path a cui è possibile accedere. Se non è definito alcun path, la direttiva viene ignorata.
Esempio
Nell’esempio sopra tutti i motori di ricerca non sono autorizzati ad accedere a /media/ directory, ad eccezione del file /media/terms-and-conditions.pdf.
Importante: quando si utilizzano Allow e Disallow insieme, assicurati di non utilizzare caratteri jolly poiché ciò potrebbe portare a direttive in conflitto.
Esempio di direttive in conflitto
I motori di ricerca non sapranno cosa fare con l’URL . Non è chiaro se gli è consentito l’accesso. Quando le direttive non sono chiare per Google, andranno con la direttiva meno restrittiva, il che in questo caso significa che in realtà accederanno a
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt è una delle funzionalità che più comunemente vedo implementata in modo errato, quindi non blocca ciò che volevano bloccare o blocca più di quanto si aspettassero e ha un impatto negativo sul loro sito web. Robots.txt è uno strumento molto potente ma troppo spesso è configurato in modo errato.
Utilizzo del carattere jolly *
Il carattere jolly non solo può essere utilizzato per definire il user-agent, ma può anche essere utilizzato per corrispondenza URL. Il carattere jolly è supportato da Google, Bing, Yahoo e Ask.
Esempio
Nell’esempio sopra, a tutti i motori di ricerca non è consentito l’accesso a URL che includono un punto interrogativo (?).

Sviluppatori o i proprietari di siti spesso sembrano pensare di poter utilizzare ogni tipo di espressione regolare in un file robots.txt mentre solo una quantità molto limitata di corrispondenza di pattern è effettivamente valida, ad esempio i caratteri jolly (
*). Di tanto in tanto sembra esserci una confusione tra i file .htaccess e i file robots.txt.
Utilizzo della fine dell’URL $
Per indicare la fine di un URL, puoi utilizzare il simbolo del dollaro ($) alla fine di path.
Esempio
Nell’esempio sopra i motori di ricerca non sono autorizzati ad accedere a tutti gli URL che terminano con .php . URL con parametri, ad es. non verrebbe disabilitato, poiché l’URL non termina dopo .php.
Aggiungi la mappa del sito a robots. txt
Anche se il file robots.txt è stato inventato per indicare ai motori di ricerca quali pagine non sottoporre a scansione, il file robots.txt può essere utilizzato anche per indirizzare i motori di ricerca alla mappa del sito XML. Questo è supportato da Google, Bing, Yahoo e Ask.
La mappa del sito XML dovrebbe essere referenziata come un URL assoluto. L’URL non deve essere sullo stesso host del file robots.txt.
Fare riferimento alla sitemap XML nel file robots.txt è una delle best practice che ti consigliamo di fare sempre, anche se potresti aver già inviato la tua mappa del sito XML in Google Search Console o Bing Webmaster Tools. Ricorda, ci sono più motori di ricerca là fuori.
Tieni presente che è possibile fare riferimento a più sitemap XML in un file robots.txt.
Esempi
Più Sitemap XML definite in un file robots.txt:
Una singola mappa del sito XML definita in un file robots.txt:
L’esempio sopra indica a tutti i motori di ricerca di non accedere alla directory /wp-admin/ e che la mappa del sito XML può essere trovata in
Comments are preceded by a # e può essere posizionato all’inizio di una riga o dopo una direttiva sulla stessa riga. Tutto ciò che segue # verrà ignorato. Questi commenti sono destinati esclusivamente agli esseri umani.
Esempio 1
Esempio 2
Gli esempi precedenti comunicano lo stesso messaggio.
Ritardo della scansione in robots.txt
Il Crawl-delay direttiva è una direttiva non ufficiale utilizzata per prevenire il sovraccarico dei server con troppe richieste. Se i motori di ricerca sono in grado di sovraccaricare un server, l’aggiunta di Crawl-delay al file robots.txt è solo una soluzione temporanea. Il nocciolo della questione è che il tuo sito web è in esecuzione su un ambiente di hosting scadente e / o il tuo sito web non è configurato correttamente e dovresti risolverlo il prima possibile.
Il modo in cui i motori di ricerca gestiscono Crawl-delay è diverso. Di seguito spieghiamo come lo gestiscono i principali motori di ricerca.
Ritardo della scansione e Google
Il crawler di Google, Googlebot, non supporta Crawl-delay, quindi non preoccuparti di definire un ritardo di scansione di Google.
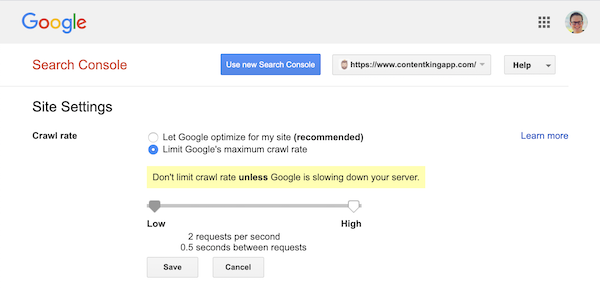
Tuttavia, Google supporta la definizione di una velocità di scansione (o “frequenza di richiesta” se vuoi ) in Google Search Console.
- Accedi alla vecchia Google Search Console.
- Scegli il sito web che desideri desidera definire la velocità di scansione per.
- C’è solo un’impostazione che puoi modificare:
Crawl rate, con un dispositivo di scorrimento in cui puoi impostare la velocità di scansione preferita. Per impostazione predefinita la velocità di scansione è impostata su “Consenti a Google di ottimizzare per il mio sito (consigliato)”.
Ecco come appare in Google Search Console:
Ritardo della scansione e Bing, Yahoo e Yandex
Bing, Yahoo e Yandex tutti supportano il Crawl-delay direttiva per limitare la scansione di un sito web. La loro interpretazione del ritardo della scansione è leggermente diversa, quindi assicurati di controllare la loro documentazione:
- Bing e Yahoo
- Yandex
La direttiva Crawl-delay deve essere collocata subito dopo le direttive Disallow o Allow.
Esempio:
Crawl-delay e Baidu
Baidu non supporta la direttiva crawl-delay, tuttavia è possibile registrare un account Baidu Webmaster Tools in di cui puoi controllare la frequenza di scansione, in modo simile a Google Search Console.
Quando utilizzare un file robots.txt?
Consigliamo di utilizzare sempre un file robots.txt. Non c’è assolutamente nulla di male nell’averne uno, ed è un ottimo posto in cui consegnare le direttive dei motori di ricerca su come possono meglio eseguire la scansione del tuo sito web.

Il file robots.txt può essere utile per impedire che determinate aree o documenti del tuo sito vengano scansionati e indicizzati. Ad esempio, il sito di staging oi PDF. Pianifica attentamente ciò che deve essere indicizzato dai motori di ricerca e tieni presente che i contenuti resi inaccessibili tramite robots.txt potrebbero comunque essere trovati dai crawler dei motori di ricerca se collegati da altre aree del sito web.
Best practice per Robots.txt
Le best practice del file robots.txt sono classificate come segue:
- Posizione e nome file
- Ordine di precedenza
- Solo un gruppo di direttive per robot
- Sii il più specifico possibile
- Direttive per tutti i robot includendo anche le direttive per un robot specifico
- File Robots.txt per ogni (sotto) dominio.
- Linee guida in conflitto: robots.txt e Google Search Console
- Monitora il tuo file robots.txt
- Non utilizzare noindex nel tuo file robots.txt
- Impedisci BOM UTF-8 nel file robots.txt
Posizione e nome file
Il file robots.txt deve essere sempre posizionato in th e root di un sito web (nella directory di primo livello dell’host) e portare il nome del file robots.txt, ad esempio: . Tieni presente che l’URL del file robots.txt, come qualsiasi altro URL, fa distinzione tra maiuscole e minuscole.
Se il file robots.txt non può essere trovato nella posizione predefinita, i motori di ricerca presumeranno che non ci siano direttive e scansioneranno il tuo sito web.
Ordine di precedenza
È importante notare che i motori di ricerca gestiscono i file robots.txt in modo diverso. Per impostazione predefinita, la prima direttiva corrispondente vince sempre.
Tuttavia, con la specificità di Google e Bing vince. Ad esempio: una direttiva Allow vince su una direttiva Disallow se la sua lunghezza in caratteri è maggiore.
Esempio
Nella esempio sopra tutti i motori di ricerca, inclusi Google e Bing, non sono autorizzati ad accedere alla directory /about/, ad eccezione della sottodirectory /about/company/.
Esempio
Nell’esempio sopra, a tutti i motori di ricerca ad eccezione di Google e Bing, non è consentito l’accesso alla directory /about/. Ciò include la directory /about/company/.
Google e Bing possono accedere, perché la direttiva Allow è più lunga della direttiva Disallow direttiva.
Solo un gruppo di direttive per robot
Puoi definire un solo gruppo di direttive per motore di ricerca. Avere più gruppi di direttive per un motore di ricerca li confonde.
Sii il più specifico possibile
La direttiva Disallow si attiva su corrispondenze parziali come bene. Sii il più specifico possibile quando definisci la direttiva Disallow per evitare di negare involontariamente l’accesso ai file.
Esempio:
L’esempio precedente non consente ai motori di ricerca di accedere a:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Direttive per tutti i robot includendo anche le direttive per un robot specifico
Per un robot solo un gruppo di direttive è valido. Nel caso in cui le direttive destinate a tutti i robot siano seguite da direttive per un robot specifico, verranno prese in considerazione solo queste direttive specifiche. Affinché il robot specifico segua anche le direttive per tutti i robot, è necessario ripetere queste direttive per il robot specifico.
Diamo un’occhiata a un esempio che lo chiarirà:
Esempio
Se non desideri che Googlebot acceda a /secret/ e /not-launched-yet/, devi ripetere queste istruzioni per googlebot in particolare:
Tieni presente che il tuo file robots.txt è disponibile pubblicamente. La disattivazione delle sezioni del sito web al suo interno può essere utilizzata come vettore di attacco da persone con intenti dannosi.

Robots.txt può essere pericoloso. Non stai solo dicendo ai motori di ricerca dove non vuoi che guardino, ma stai dicendo alle persone dove nascondi i tuoi sporchi segreti.
File Robots.txt per ogni (sotto) dominio
Solo direttive Robots.txt si applicano al (sotto) dominio in cui è ospitato il file.
Esempi
è valido per , ma non per o
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Abbiamo creato il monitoraggio delle modifiche e gli avvisi nel file robots.txt per questo motivo.
Lo vediamo continuamente: i file robots.txt cambiano senza la conoscenza del marketing digitale squadra. Non essere quella persona. Inizia a monitorare il tuo file robots.txt ora ricevi avvisi quando cambia!
Non utilizzare noindex nel tuo file robots.txt
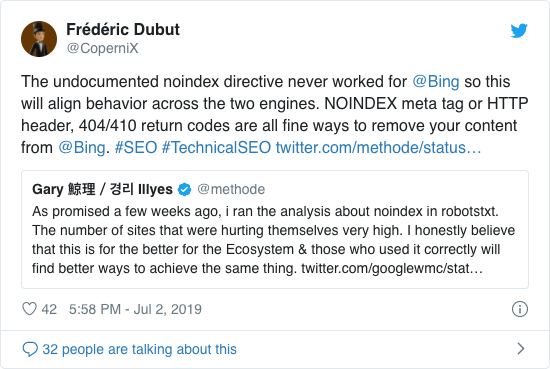
Per anni Google raccomandava già apertamente di non utilizzare la direttiva noindex non ufficiale. A partire dal 1 ° settembre 2019, tuttavia, Google ha smesso del tutto di supportarlo.
La direttiva noindex non ufficiale non ha mai funzionato in Bing, come confermato da Frédéric Dubut in questo tweet:
Il modo migliore per segnalare ai motori di ricerca che le pagine non devono essere indicizzate è utilizzare il tag meta robots o X-Robots-Tag .
Impedisci BOM UTF-8 nel file robots.txt
BOM sta per byte order mark, un carattere invisibile all’inizio di un file utilizzato per indicare la codifica Unicode di un file di testo.
Sebbene Google dichiari di ignorare il contrassegno facoltativo dell’ordine dei byte Unicode all’inizio del file robots.txt, consigliamo di impedire la “BOM UTF-8” perché abbiamo riscontrato che causa problemi con l’interpretazione di il file robots.txt dai motori di ricerca.
Anche se Google afferma di poterlo gestire, ecco due motivi per impedire la distinta materiali UTF-8:
- Non Non voglio che ci siano ambiguità sulle tue preferenze riguardo alla scansione dei motori di ricerca.
- Ci sono altri motori di ricerca là fuori che potrebbero non essere così indulgenti come Google sostiene di essere.
Esempi di robots.txt
In questo capitolo tratteremo un’ampia gamma di esempi di file robots.txt:
- Consenti a tutti i robot di accedere a tutto
- Impedisci a tutti i robot di accedere a tutto
- Tutti i robot di Google non hanno accesso
- Tutti i robot di Google, ad eccezione delle notizie di Googlebot, non hanno accesso
- Googlebot e Slurp non hanno accesso
- Tutti i robot non hanno accesso a due directory
- Tutti i robot non hanno accesso a un file specifico
- Googlebot non ha accesso a / admin / e Slurp non ha accesso a / private /
- File Robots.txt per WordPress
- File Robots.txt per Magento
Consenti a tutti i robot di accedere a tutto
Esistono diversi modi per dire ai motori di ricerca che possono accedere a tutti i file:
O avere un file robots.txt vuoto o non avere affatto un robots.txt.
Impedisci a tutti i robot di accedere a tutto
L’esempio Il file robots.txt di seguito indica a tutti i motori di ricerca di non accedere all’intero sito:
Tieni presente che solo UN carattere in più può fare la differenza.
Tutti i bot di Google non hanno accesso
Tieni presente che quando disabiliti Googlebot, questo vale per tutti i Googlebot. Ciò include i robot Google che cercano ad esempio notizie (googlebot-news) e immagini (googlebot-images).
Tutti I bot di Google, ad eccezione delle notizie di Googlebot, non hanno accesso
Googlebot e Slurp non hanno accesso
Tutti i robot non hanno accesso a due directory
Tutti i robot non hanno accesso a un file specifico
Googlebot non ha accesso a / admin / e Slurp non hanno accesso a / private /
Robots.txt file per WordPress
Il file robots.txt di seguito è specificamente ottimizzato per WordPress, supponendo che:
- Non desideri che la tua sezione di amministrazione venga sottoposta a scansione.
- Non vuoi che le tue pagine dei risultati di ricerca interna vengano sottoposte a scansione.
- Non vuoi che il tuo tag e le pagine dell’autore vengano scansionati.
- Non devi voglio che la tua pagina 404 venga sottoposta a scansione.
Tieni presente che questo file robots.txt funzionerà nella maggior parte dei casi, ma dovresti sempre modificarlo e testarlo per assicurarti che si applichi al tuo situazione esatta.
File Robots.txt per Magento
Il file robots.txt di seguito è specificamente ottimizzato per Magento e produrrà risultati di ricerca interni, pagine di accesso, identificatori di sessione e risultati filtrati set che contengono price, color, material e size criteri inaccessibili ai crawler.
Tieni presente che questo file robots.txt funzionerà per la maggior parte dei negozi Magento, ma tu dovresti sempre adattarlo e testarlo per assicurarti che si applichi alla tua situazione esatta.
Cercherò comunque di bloccare i risultati di ricerca interni nel file robots.txt su qualsiasi sito perché questi tipi di URL di ricerca sono spazi infiniti e infiniti. È molto probabile che Googlebot finisca in una trappola del crawler.
Quali sono i limiti del file robots.txt?
Il file robots.txt contiene direttive
Anche se il file robots.txt è ben rispettato dalla ricerca motori, è ancora una direttiva e non un mandato.
Pagine che appaiono ancora nei risultati di ricerca
Pagine che sono inaccessibili per i motori di ricerca a causa dei robot.txt, ma i link ad essi possono ancora apparire nei risultati di ricerca se sono collegati da una pagina sottoposta a scansione. Un esempio di come appare:

È possibile rimuovere questi URL da Google utilizzando lo strumento di rimozione degli URL di Google Search Console. Tieni presente che questi URL saranno solo temporaneamente “nascosti”. Affinché non vengano visualizzati nelle pagine dei risultati di Google, devi inviare una richiesta per nascondere gli URL ogni 180 giorni.

Utilizza il file robots.txt per bloccare i backlink di affiliazione indesiderabili e potenzialmente dannosi. non utilizzare robots.txt nel tentativo di impedire che i contenuti vengano indicizzati dai motori di ricerca, poiché ciò inevitabilmente fallirà. Applicare invece la direttiva robots noindex quando necessario.
Il file Robots.txt viene memorizzato nella cache fino a 24 ore
Google ha indicato che un robot Il file .txt viene generalmente memorizzato nella cache per un massimo di 24 ore. È importante tenerne conto quando apporti modifiche al file robots.txt.
Non è chiaro come gli altri motori di ricerca gestiscono la memorizzazione nella cache di robots.txt , ma in generale è meglio evitare di memorizzare nella cache il file robots.txt in av oid i motori di ricerca impiegano più tempo del necessario per essere in grado di rilevare le modifiche.
Dimensione file Robots.txt
Per i file robots.txt Google attualmente supporta un limite di dimensione file di 500 kibibyte (512 kilobyte). Qualsiasi contenuto dopo questa dimensione massima del file può essere ignorato.
Non è chiaro se altri motori di ricerca abbiano una dimensione massima del file per i file robots.txt.
Domande frequenti su robots.txt
🤖 Che aspetto ha un esempio di robots.txt?
Ecco un esempio del contenuto di un file robots.txt: User-agent: * Disallow:. Questo dice a tutti i crawler che possono accedere a tutto.
⛔ Che cosa fa Disallow all in robots.txt?
Quando imposti un file robots.txt su “Disallow all”, sei essenzialmente dicendo a tutti i crawler di stare alla larga. Nessun crawler, compreso Google, è autorizzato ad accedere al tuo sito. Ciò significa che non sarà in grado di eseguire la scansione, indicizzare e classificare il tuo sito. Ciò comporterà un notevole calo del traffico organico.
✅ Che cosa fa Consenti tutto in robots.txt?
Quando imposti un file robots.txt su “Consenti tutto”, dici a ogni crawler che può accedere a ogni URL del sito. Semplicemente non ci sono regole di ingaggio. Tieni presente che questo è l’equivalente di avere un file robots.txt vuoto o di non avere affatto robots.txt.
🤔 Quanto è importante il file robots.txt per la SEO?
In in generale, il file robots.txt è molto importante per scopi SEO. Per i siti web più grandi, il file robots.txt è essenziale per fornire ai motori di ricerca istruzioni molto chiare su quali contenuti non accedere.