A robots .txt-bestand bevat richtlijnen voor zoekmachines. U kunt het gebruiken om te voorkomen dat zoekmachines specifieke delen van uw website crawlen en om zoekmachines handige tips te geven over hoe ze uw website het beste kunnen crawlen. Het robots.txt-bestand speelt een grote rol bij SEO.
Houd bij het implementeren van robots.txt rekening met de volgende best practices:
- Wees voorzichtig bij het aanbrengen van wijzigingen in uw robots.txt: dit bestand kan grote delen van uw website ontoegankelijk maken voor zoekmachines.
- Het robots.txt-bestand moet in de root van uw website staan (bijv.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpofhttps). - Verschillende zoekmachines interpreteren richtlijnen op verschillende manieren. Standaard wint de eerste overeenkomende richtlijn altijd. Maar met Google en Bing wint specificiteit.
- Gebruik de crawl-delay-richtlijn zo veel mogelijk voor zoekmachines.
Wat is een robots.txt-bestand?
Een robots.txt-bestand vertelt zoekmachines wat de regels van uw website zijn. Een groot deel van het doen van SEO gaat over het sturen van de juiste signalen naar zoekmachines, en de robots.txt is een van de manieren om je crawlvoorkeuren aan zoekmachines door te geven.
In 2019 hebben we behoorlijk wat enkele ontwikkelingen rond de robots.txt-standaard: Google heeft een uitbreiding van het Robots Exclusion Protocol voorgesteld en de robots.txt-parser open source gemaakt.
TL; DR
- Google’s robots .txt-interpreter is vrij flexibel en verrassend vergevingsgezind.
- In het geval van verwarringrichtlijnen, vergist Google zich aan de veilige kanten en gaat ervan uit dat secties beperkt moeten zijn in plaats van onbeperkt.
Zoekmachines controleren regelmatig het robots.txt-bestand van een website om te zien of er instructies zijn voor het crawlen van de website. We noemen deze instructies richtlijnen.
Als er geen robots.txt-bestand aanwezig is of als er geen toepasselijke richtlijnen zijn, zullen zoekmachines de hele website doorzoeken.
Hoewel alle grote zoekmachines respecteren het robots.txt-bestand, kunnen zoekmachines ervoor kiezen om (delen van) uw robots.txt-bestand te negeren. Hoewel richtlijnen in het robots.txt-bestand een sterk signaal zijn voor zoekmachines, is het belangrijk om te onthouden dat het robots.txt-bestand een set optionele richtlijnen voor zoekmachines is en geen mandaat.

Het robots.txt-bestand is het meest gevoelige bestand in het SEO-universum. Een enkel teken kan een hele site breken.
Terminologie rond robots.txt-bestand
Het robots.txt-bestand is de implementatie van de robots-uitsluitingsstandaard, of wordt ook wel het robots-uitsluitingsprotocol.
Waarom zou u om robots.txt geven?
Het robots.txt-bestand speelt een essentiële rol vanuit SEO-oogpunt. Het vertelt zoekmachines hoe ze uw website het beste kunnen crawlen.
Met behulp van het robots.txt-bestand kunt u voorkomen dat zoekmachines toegang krijgen tot bepaalde delen van uw website, dubbele inhoud voorkomen en zoekmachines handige tips geven over hoe ze kan uw website efficiënter crawlen.
Wees echter voorzichtig wanneer u wijzigingen aanbrengt in uw robots.txt: dit bestand kan grote delen van uw website ontoegankelijk maken voor zoekmachines.

Robots.txt wordt vaak te veel gebruikt om dubbele inhoud te verminderen, waardoor het doden van interne links, dus wees er echt voorzichtig mee. Mijn advies is om het alleen te gebruiken voor bestanden of pagina’s die zoekmachines nooit zouden mogen zien, of die het crawlen aanzienlijk kunnen beïnvloeden door erin te worden toegelaten. Veelvoorkomende voorbeelden: inloggebieden die veel verschillende URL’s genereren, testgebieden of waar meerdere gefacetteerde navigatie kan bestaan. En zorg ervoor dat u uw robots.txt-bestand controleert op eventuele problemen of wijzigingen.

De meeste problemen die ik zie met robots.txt-bestanden vallen uiteen in drie categorieën:
- Het verkeerd omgaan met jokertekens. Het komt vrij vaak voor dat delen van de site worden geblokkeerd die bedoeld waren om te worden geblokkeerd. Soms, als je niet oppast, kunnen richtlijnen ook met elkaar in strijd zijn.
- Iemand, zoals een ontwikkelaar, heeft uit het niets een wijziging doorgevoerd (vaak bij het pushen van nieuwe code) en heeft deze per ongeluk gewijzigd de robots.txt zonder uw medeweten.
- Het opnemen van richtlijnen die niet thuishoren in een robots.txt-bestand. Robots.txt is een webstandaard en is enigszins beperkt. Ik zie vaak dat ontwikkelaars richtlijnen maken die gewoon niet werken (althans voor de meerderheid van de crawlers). Soms is dat onschadelijk, soms niet zozeer.
Voorbeeld
Laten we een voorbeeld bekijken om dit te illustreren:
Jij hebben een e-commerce website en bezoekers kunnen een filter gebruiken om snel door uw producten te zoeken. Dit filter genereert pagina’s die in principe dezelfde inhoud laten zien als andere pagina’s. Dit werkt prima voor gebruikers, maar brengt zoekmachines in de war omdat het dubbele inhoud creëert.
U wilt niet dat zoekmachines deze gefilterde pagina’s indexeren en hun kostbare tijd aan deze URL’s verspillen met gefilterde inhoud. Daarom moet u Disallow regels instellen zodat zoekmachines geen toegang krijgen tot deze gefilterde productpagina’s.
Het voorkomen van dubbele inhoud kan ook worden gedaan met behulp van de canonieke URL of de meta robots-tag, maar deze zijn niet bedoeld om zoekmachines alleen pagina’s te laten crawlen die er toe doen.
Het gebruik van een canonieke URL of meta-robots-tag zal niet voorkomen dat zoekmachines deze pagina’s crawlen. Het voorkomt alleen dat zoekmachines deze pagina’s in de zoekresultaten weergeven. Aangezien zoekmachines weinig tijd hebben om een website te crawlen, moet u deze tijd besteden aan pagina’s die u in zoekmachines wilt weergeven.
Een onjuist ingesteld robots.txt-bestand kan uw SEO-prestaties belemmeren. Controleer meteen of dit het geval is voor uw website!

Het is een heel eenvoudige tool, maar een robots.txt-bestand kan veel problemen veroorzaken als het niet correct is geconfigureerd, vooral voor grotere websites. Het is heel gemakkelijk om fouten te maken, zoals het blokkeren van een hele site nadat een nieuw ontwerp of CMS is uitgerold, of het niet blokkeren van delen van een site die privé zouden moeten zijn. Voor grotere websites is het erg belangrijk om ervoor te zorgen dat Google efficiënt crawlt, en een goed gestructureerd robots.txt-bestand is een essentieel hulpmiddel in dat proces.
U moet de tijd nemen om te begrijpen welke delen van uw site het beste weggehouden kunnen worden van Google, zodat ze zoveel mogelijk van hun middelen besteden aan het crawlen van de pagina’s die u echt belangrijk vindt.
Hoe ziet een robots.txt-bestand eruit?
Een voorbeeld van wat een eenvoudig robots.txt-bestand voor een WordPress-website kan zien eruit als:
Laten we de anatomie van een robots.txt-bestand uitleggen op basis van het bovenstaande voorbeeld:
- User-agent: de
user-agentgeeft aan voor welke zoekopdracht engines de richtlijnen die volgen zijn bedoeld. -
*: dit geeft aan dat de richtlijnen bedoeld zijn voor alle zoekmachines. -
Disallow: dit is een richtlijn die aangeeft welke inhoud niet toegankelijk is voor deuser-agent. -
/wp-admin/: dit is depathdie niet toegankelijk is voor deuser-agent.
Samengevat: dit robots.txt-bestand vertelt alle zoekmachines om uit de /wp-admin/ -directory te blijven.
Laten we de verschillende componenten van robots.txt-bestanden in meer detail:
- User-agent
- Disallow
- Toestaan
- Sitemap
- Crawlvertraging
User-agent in robots.txt
Elke zoekmachine moet zichzelf identificeren met een user-agent. De robots van Google identificeren zich als Googlebot, bijvoorbeeld Yahoo’s robots als Slurp en Bing’s robot als BingBot enzovoort.
Het user-agent record definieert het begin van een groep richtlijnen. Alle richtlijnen tussen de eerste user-agent en de volgende user-agent -record worden behandeld als richtlijnen voor de eerste user-agent.
Richtlijnen kunnen van toepassing zijn op specifieke user-agents, maar ze kunnen ook van toepassing zijn op alle user-agents. In dat geval wordt een jokerteken gebruikt: User-agent: *.
Disallow-instructie in robots.txt
Je kunt zoekmachines vertellen om geen toegang te krijgen tot bepaalde bestanden, pagina’s of secties van uw website. Dit wordt gedaan met behulp van de Disallow richtlijn. De Disallow -instructie wordt gevolgd door de path die niet mag worden geopend. Als er geen path is gedefinieerd, wordt de instructie genegeerd.
Voorbeeld
In dit voorbeeld wordt aan alle zoekmachines verteld dat ze geen toegang moeten krijgen tot de /wp-admin/ directory.
Sta instructie toe in robots.txt
De Allow richtlijn wordt gebruikt om een Disallow richtlijn tegen te gaan. De Allow -instructie wordt ondersteund door Google en Bing. Door de Allow en Disallow richtlijnen samen te gebruiken, kun je zoekmachines vertellen dat ze toegang hebben tot een specifiek bestand of pagina in een directory die anders niet is toegestaan. De Allow richtlijn wordt gevolgd door de path waartoe toegang kan worden verkregen. Als er geen path is gedefinieerd, wordt de richtlijn genegeerd.
Voorbeeld
In het bovenstaande voorbeeld hebben alle zoekmachines geen toegang tot de /media/ directory, behalve het bestand /media/terms-and-conditions.pdf.
Belangrijk: bij gebruik van Allow en Disallow richtlijnen samen, gebruik geen jokertekens, aangezien dit tot conflicterende richtlijnen kan leiden.
Voorbeeld van tegenstrijdige richtlijnen
Zoekmachines weten niet wat ze met de URL moeten doen . Het is voor hen niet duidelijk of ze er toegang toe hebben. Wanneer richtlijnen niet duidelijk zijn voor Google, gaan ze voor de minst beperkende richtlijn, wat in dit geval betekent dat ze in feite toegang hebben tot
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt is een van de functies die ik meestal verkeerd geïmplementeerd zie, dus het blokkeert niet wat ze wilden blokkeren of het blokkeert meer dan verwacht en heeft een negatieve impact op hun website. Robots.txt is een zeer krachtige tool, maar is maar al te vaak verkeerd ingesteld.
Jokerteken * gebruiken
Het jokerteken kan niet alleen worden gebruikt om de user-agent te definiëren, het kan ook worden gebruikt om match URL’s. Het jokerteken wordt ondersteund door Google, Bing, Yahoo en Ask.
Voorbeeld
In het bovenstaande voorbeeld hebben alle zoekmachines geen toegang tot URL’s die een vraagteken bevatten (?).

Ontwikkelaars of site-eigenaren lijken vaak te denken dat ze allerlei soorten reguliere expressies kunnen gebruiken in een robots.txt-bestand, terwijl slechts een zeer beperkte hoeveelheid patroonovereenkomst daadwerkelijk geldig is, bijvoorbeeld jokertekens (
*). Er lijkt van tijd tot tijd verwarring te bestaan tussen .htaccess-bestanden en robots.txt-bestanden.
Met einde van URL $
Om het einde van een URL aan te geven, kunt u het dollarteken ($) aan het einde van de path.
Voorbeeld
In het bovenstaande voorbeeld hebben zoekmachines geen toegang tot alle URL’s die eindigen op .php . URL’s met parameters, bijv. zou niet worden geweigerd, aangezien de URL niet eindigt na .php.
Voeg sitemap toe aan robots. txt
Hoewel het robots.txt-bestand is uitgevonden om zoekmachines te vertellen welke pagina’s niet moeten worden gecrawld, kan het robots.txt-bestand ook worden gebruikt om zoekmachines naar de XML-sitemap te verwijzen. Dit wordt ondersteund door Google, Bing, Yahoo en Ask.
Er moet naar de XML-sitemap worden verwezen als een absolute URL. De URL hoeft niet op dezelfde host te staan als het robots.txt-bestand.
Verwijzen naar de XML-sitemap in het robots.txt-bestand is een van de best practices die we je adviseren altijd te doen, ook al Mogelijk hebt u uw XML-sitemap al ingediend in Google Search Console of Bing Webmaster Tools. Onthoud dat er meer zoekmachines zijn.
Houd er rekening mee dat het mogelijk is om naar meerdere XML-sitemaps te verwijzen in een robots.txt-bestand.
Voorbeelden
Meerdere XML-sitemaps gedefinieerd in een robots.txt-bestand:
Een enkele XML-sitemap gedefinieerd in een robots.txt-bestand:
Het bovenstaande voorbeeld vertelt alle zoekmachines om de directory /wp-admin/ niet te openen en dat de XML-sitemap kan worden gevonden op
Comments are preceded by a # en ofwel aan het begin van een regel worden geplaatst of na een instructie op dezelfde regel. Alles na de # wordt genegeerd. Deze opmerkingen zijn alleen bedoeld voor mensen.
Voorbeeld 1
Voorbeeld 2
De bovenstaande voorbeelden brengen hetzelfde bericht over.
Crawlvertraging in robots.txt
De Crawl-delay richtlijn is een niet-officiële richtlijn die wordt gebruikt om overbelasting van servers met te veel verzoeken te voorkomen. Als zoekmachines een server kunnen overbelasten, is het toevoegen van Crawl-delay aan uw robots.txt-bestand slechts een tijdelijke oplossing. Het feit is dat uw website op een slechte hostingomgeving draait en / of uw website niet correct is geconfigureerd, en u moet dit zo snel mogelijk oplossen.
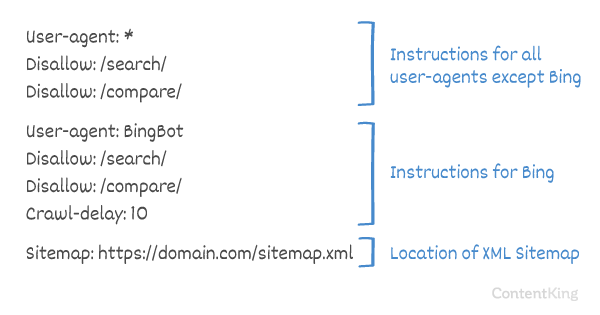
De manier waarop zoekmachines omgaan met Crawl-delay verschilt. Hieronder leggen we uit hoe grote zoekmachines hiermee omgaan.
Crawlvertraging en Google
De crawler van Google, Googlebot, ondersteunt de Crawl-delay richtlijn, dus doe geen moeite om een Google-crawlvertraging te definiëren.
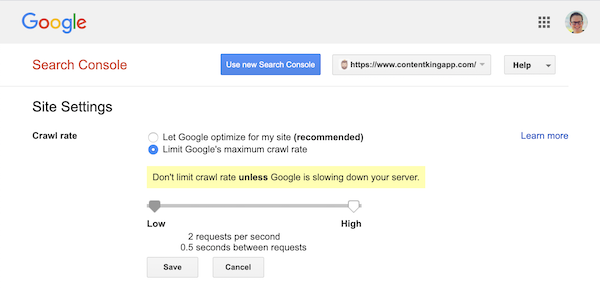
Google ondersteunt echter wel het definiëren van een crawlsnelheid (of “verzoeksnelheid” als je wilt ) in Google Search Console.
- Log in op de oude Google Search Console.
- Kies de website die u de crawlsnelheid wilt definiëren.
- Er is maar één instelling die u kunt aanpassen:
Crawl rate, met een schuifregelaar waarmee u de gewenste crawlsnelheid kunt instellen. Standaard de crawlsnelheid is ingesteld op “Laat Google optimaliseren voor mijn site (aanbevolen)”.
Zo ziet dat eruit in Google Search Console:
Crawlvertraging en Bing, Yahoo en Yandex
Bing, Yahoo en Yandex ondersteunen allemaal de Crawl-delay richtlijn om het crawlen van een website te vertragen. Hun interpretatie van de crawl-vertraging is echter iets anders, dus zorg ervoor dat je hun documentatie raadpleegt:
- Bing en Yahoo
- Yandex
De Crawl-delay richtlijn moet direct na de Disallow of Allow richtlijnen worden geplaatst.
Voorbeeld:
Crawl-delay en Baidu
Baidu ondersteunt de crawl-delay richtlijn niet, maar het is mogelijk om een Baidu Webmaster Tools-account te registreren in waarmee je de crawlfrequentie kunt regelen, vergelijkbaar met Google Search Console.
Wanneer moet je een robots.txt-bestand gebruiken?
We raden je aan altijd een robots.txt-bestand te gebruiken. Het kan absoluut geen kwaad om er een te hebben, en het is een geweldige plek om zoekmachines richtlijnen te geven over hoe ze uw website het beste kunnen crawlen.

Het robots.txt-bestand kan handig zijn om te voorkomen dat bepaalde gebieden of documenten op uw site worden gecrawld en geïndexeerd. Voorbeelden zijn bijvoorbeeld de staging-site of pdf’s. Plan zorgvuldig wat door zoekmachines moet worden geïndexeerd en houd er rekening mee dat inhoud die ontoegankelijk is gemaakt via robots.txt, nog steeds kan worden gevonden door crawlers van zoekmachines als er naar wordt gelinkt vanuit andere delen van de website.
Robots.txt praktische tips
De best practices van robots.txt zijn als volgt gecategoriseerd:
- Locatie en bestandsnaam
- Rangorde
- Slechts één groep richtlijnen per robot
- Wees zo specifiek mogelijk
- Richtlijnen voor alle robots en neem ook richtlijnen op voor een specifieke robot
- Robots.txt-bestand voor elk (sub) domein.
- Tegenstrijdige richtlijnen: robots.txt versus Google Search Console
- Controleer uw robots.txt-bestand
- Gebruik geen noindex in uw robots.txt
- Voorkom UTF-8 BOM in robots.txt-bestand
Locatie en bestandsnaam
Het robots.txt-bestand moet altijd in th e root van een website (in de hoofddirectory van de host) en draag de bestandsnaam robots.txt, bijvoorbeeld: . Houd er rekening mee dat de URL voor het robots.txt-bestand, net als elke andere URL, hoofdlettergevoelig is.
Als het robots.txt-bestand niet op de standaardlocatie kan worden gevonden, gaan zoekmachines ervan uit dat er geen richtlijnen zijn en kruipen ze weg op uw website.
Rangorde
Het is belangrijk op te merken dat zoekmachines robots.txt-bestanden anders behandelen. Standaard wint de eerste overeenkomende richtlijn altijd.
Echter, met Google en Bing wint specificiteit. Bijvoorbeeld: een Allow richtlijn wint van een Disallow richtlijn als de tekenlengte langer is.
Voorbeeld
In de voorbeeld bovenal hebben alle zoekmachines, inclusief Google en Bing, geen toegang tot de /about/ directory, behalve de subdirectory /about/company/.
Voorbeeld
In het bovenstaande voorbeeld hebben alle zoekmachines behalve Google en Bing geen toegang tot de /about/ directory. Dat omvat de directory /about/company/.
Google en Bing hebben toegang, omdat de Allow -instructie langer is dan de Disallow richtlijn.
Slechts één groep richtlijnen per robot
U kunt slechts één groep richtlijnen per zoekmachine definiëren. Het gebruik van meerdere groepen richtlijnen voor één zoekmachine verwart ze.
Wees zo specifiek mogelijk
De Disallow -instructie wordt geactiveerd bij gedeeltelijke overeenkomsten, aangezien goed. Wees zo specifiek mogelijk bij het definiëren van de Disallow -richtlijn om te voorkomen dat u per ongeluk de toegang tot bestanden weigert.
Voorbeeld:
In het bovenstaande voorbeeld hebben zoekmachines geen toegang tot:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Richtlijnen voor alle robots, maar ook richtlijnen voor een specifieke robot
Voor een robot slechts één groep richtlijnen is geldig. In het geval dat richtlijnen bedoeld voor alle robots worden gevolgd met richtlijnen voor een specifieke robot, zullen alleen deze specifieke richtlijnen in overweging worden genomen. Om ervoor te zorgen dat de specifieke robot ook de richtlijnen voor alle robots volgt, moet u deze richtlijnen herhalen voor de specifieke robot.
Laten we naar een voorbeeld kijken dat dit duidelijk zal maken:
Voorbeeld
Als u niet wilt dat Googlebot toegang heeft tot /secret/ en /not-launched-yet/, moet u deze richtlijnen herhalen voor googlebot specifiek:
Houd er rekening mee dat uw robots.txt-bestand openbaar beschikbaar is. Het niet toestaan van website-secties daarin kan worden gebruikt als een aanvalsvector door mensen met kwaadwillende bedoelingen.

Robots.txt kan gevaarlijk zijn. U vertelt zoekmachines niet alleen waar u niet wilt dat ze zoeken, u vertelt mensen ook waar u uw vuile geheimen verbergt.
Robots.txt-bestand voor elk (sub) domein
Alleen Robots.txt-richtlijnen zijn van toepassing op het (sub) domein waarop het bestand wordt gehost.
Voorbeelden
is geldig voor , maar niet voor of
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / We hebben om deze reden robots.txt-tracking en waarschuwingen voor wijzigingen gebouwd.
We zien het de hele tijd: robots.txt-bestanden veranderen zonder kennis van de digitale marketing team. Wees niet die persoon. Begin met het bewaken van uw robots.txt-bestand en ontvang nu waarschuwingen wanneer het verandert!
Gebruik geen noindex in uw robots.txt
Jarenlang raadde Google al openlijk af om de onofficiële noindex-richtlijn te gebruiken. Sinds 1 september 2019 ondersteunt Google het echter helemaal niet meer.
De onofficiële noindex-richtlijn werkte nooit in Bing, zoals bevestigd door Frédéric Dubut in deze tweet:
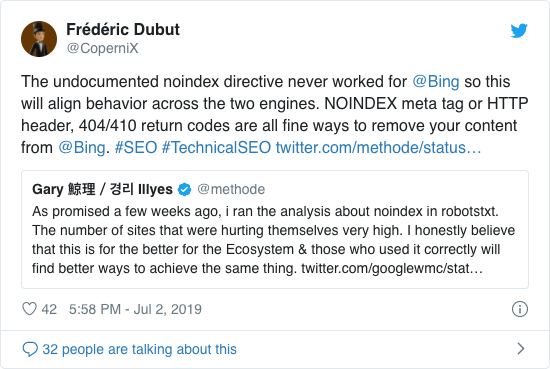
De beste manier om zoekmachines duidelijk te maken dat pagina’s niet moeten worden geïndexeerd, is door de meta robots-tag of X-Robots-Tag te gebruiken .
Voorkom UTF-8 BOM in robots.txt-bestand
BOM staat voor bytevolgordemarkering, een onzichtbaar teken aan het begin van een bestand dat wordt gebruikt om de Unicode-codering van een tekstbestand aan te geven.
Hoewel Google beweert dat ze de optionele Unicode-bytevolgordemarkering aan het begin van het robots.txt-bestand negeren, raden we aan de ‘UTF-8 BOM’ te voorkomen, omdat we hebben gezien dat deze problemen veroorzaakt met de interpretatie van het robots.txt-bestand door zoekmachines.
Hoewel Google zegt dat ze ermee kunnen omgaan, zijn er twee redenen om de UTF-8 BOM te voorkomen:
- U hoeft niet wil niet dat er enige onduidelijkheid bestaat over uw voorkeuren met betrekking tot het crawlen naar zoekmachines.
- Er zijn andere zoekmachines die misschien niet zo vergevingsgezind zijn als Google beweert te zijn.
Robots.txt-voorbeelden
In dit hoofdstuk behandelen we een groot aantal voorbeelden van robots.txt-bestanden:
- Geef alle robots toegang tot alles
- Alle robots toegang tot alles weigeren
- Alle Google-bots hebben geen toegang
- Alle Google-bots, behalve Googlebot-nieuws, hebben geen toegang
- Googlebot en Slurp hebben geen toegang
- Alle robots hebben geen toegang tot twee directories
- Alle robots hebben geen toegang tot één specifiek bestand
- Googlebot heeft geen toegang tot / admin / en Slurp heeft geen toegang tot / private /
- Robots.txt-bestand voor WordPress
- Robots.txt-bestand voor Magento
Geef alle robots toegang tot alles
Er zijn meerdere manieren om zoekmachines te vertellen dat ze toegang hebben tot alle bestanden:
Of je hebt een leeg robots.txt-bestand of helemaal geen robots.txt-bestand.
Sta alle robots geen toegang toe tot alles
Het voorbeeld Het onderstaande robots.txt-bestand vertelt alle zoekmachines om geen toegang te krijgen tot de hele site:
Houd er rekening mee dat slechts ÉÉN extra teken het verschil kan maken.
Alle Google-bots hebben geen toegang
Houd er rekening mee dat wanneer Googlebot niet is toegestaan, dit geldt voor alle Googlebots. Dat geldt ook voor Google-robots die bijvoorbeeld zoeken naar nieuws (googlebot-news) en afbeeldingen (googlebot-images).
Alle Google-bots, behalve Googlebot-nieuws, hebben geen toegang
Googlebot en Slurp hebben geen toegang
Alle robots hebben geen toegang tot twee mappen
Alle robots hebben geen toegang tot één specifiek bestand
Googlebot heeft geen toegang tot / admin / en Slurp hebben geen toegang tot / private /
Robots.txt bestand voor WordPress
Het onderstaande robots.txt-bestand is specifiek geoptimaliseerd voor WordPress, ervan uitgaande:
- U wilt niet dat uw beheerdersgedeelte wordt gecrawld.
- U wilt niet dat uw interne pagina’s met zoekresultaten worden gecrawld.
- U wilt niet dat uw tag- en auteurspagina’s worden gecrawld.
- Dat doet u niet ‘ Ik wil dat uw 404-pagina wordt gecrawld.
Houd er rekening mee dat dit robots.txt-bestand in de meeste gevallen zal werken, maar u moet het altijd aanpassen en testen om er zeker van te zijn dat het van toepassing is op uw exacte situatie.
Robots.txt-bestand voor Magento
Het robots.txt-bestand hieronder is specifiek geoptimaliseerd voor Magento en zal interne zoekresultaten, login-pagina’s, sessie-ID’s en gefilterde resultaten opleveren sets die price, color, material en size criteria die niet toegankelijk zijn voor crawlers.
Houd er rekening mee dat dit robots.txt-bestand zal werken voor de meeste Magento-winkels, maar jij moet het altijd aanpassen en testen om er zeker van te zijn dat het van toepassing is op uw exacte situatie.
Ik zou nog steeds altijd proberen interne zoekresultaten in robots.txt op elke site te blokkeren, omdat dit soort zoek-URL’s oneindig en eindeloos zijn. Er is veel kans dat Googlebot in een crawler-val terechtkomt.
Wat zijn de beperkingen van het robots.txt-bestand?
Robots.txt-bestand bevat richtlijnen
Hoewel het robots.txt-bestand goed wordt gerespecteerd door zoekopdrachten zoekmachines, het is nog steeds een richtlijn en geen mandaat.
Pagina’s die nog steeds verschijnen in zoekresultaten
Pagina’s die niet toegankelijk zijn voor zoekmachines vanwege de robots.txt, maar links naar hen hebben, kunnen nog steeds in zoekresultaten worden weergegeven als ze worden gelinkt vanaf een pagina die wordt gecrawld. Een voorbeeld van hoe dit eruit ziet:

Het is mogelijk om deze URL’s van Google te verwijderen met de tool voor het verwijderen van URL’s van Google Search Console. Houd er rekening mee dat deze URL’s slechts tijdelijk “verborgen” zijn. Om ervoor te zorgen dat ze niet op de resultaatpagina’s van Google blijven, moet u elke 180 dagen een verzoek indienen om de URL’s te verbergen.

Gebruik robots.txt om ongewenste en waarschijnlijk schadelijke partner-backlinks te blokkeren. gebruik geen robots.txt in een poging om te voorkomen dat inhoud wordt geïndexeerd door zoekmachines, aangezien dit onvermijdelijk zal mislukken. Pas in plaats daarvan de robots-richtlijn noindex toe wanneer dat nodig is.
Robots.txt-bestand wordt maximaal 24 uur in de cache opgeslagen
Google heeft aangegeven dat een robots .txt-bestand wordt over het algemeen maximaal 24 uur in de cache opgeslagen. Het is belangrijk om hier rekening mee te houden wanneer u wijzigingen aanbrengt in uw robots.txt-bestand.
Het is onduidelijk hoe andere zoekmachines omgaan met caching van robots.txt-bestanden. , maar over het algemeen is het het beste om uw robots.txt-bestand niet in de cache te plaatsen naar av oid zoekmachines er langer over doen dan nodig is om wijzigingen te kunnen herkennen.
Robots.txt-bestandsgrootte
Voor robots.txt-bestanden ondersteunt Google momenteel een maximale bestandsgrootte van 500 kibibytes (512 kilobytes). Alle inhoud na deze maximale bestandsgrootte kan worden genegeerd.
Het is onduidelijk of andere zoekmachines een maximale bestandsgrootte hebben voor robots.txt-bestanden.
Veelgestelde vragen over robots.txt
🤖 Hoe ziet een robots.txt-voorbeeld eruit?
Hier is een voorbeeld van de inhoud van een robots.txt-bestand: User-agent: * Disallow:. Dit vertelt alle crawlers dat ze overal toegang toe hebben.
⛔ Wat doet Disallow all in robots.txt?
Als je een robots.txt instelt op ‘Disallow all’, ben je in feite alle crawlers vertellen dat ze buiten moeten blijven. Geen enkele crawlers, inclusief Google, heeft toegang tot uw site. Dit betekent dat ze uw site niet kunnen crawlen, indexeren en rangschikken. Dit zal leiden tot een enorme daling van het organische verkeer.
✅ Wat doet Allow all in robots.txt?
Als je een robots.txt instelt op “Allow all”, laat je elke crawler weten dat ze toegang hebben tot elke URL op de site. Er zijn gewoon geen regels voor betrokkenheid. Houd er rekening mee dat dit het equivalent is van een leeg robots.txt-bestand of helemaal geen robots.txt-bestand.
🤔 Hoe belangrijk is het robots.txt-bestand voor SEO?
In Over het algemeen is het robots.txt-bestand erg belangrijk voor SEO-doeleinden. Voor grotere websites is de robots.txt essentieel om zoekmachines zeer duidelijke instructies te geven over welke inhoud ze niet mogen openen.