Funcția fereastră ROW_NUMBER are numeroase aplicații practice, mult dincolo de nevoile evidente de clasificare. De cele mai multe ori, atunci când calculați numerele de rând, trebuie să le calculați pe baza unei anumite ordini și furnizați specificația de comandă dorită în clauza de comandă a ferestrei a funcției. Cu toate acestea, există cazuri în care trebuie să calculați numerele rândurilor în nici o ordine specială; cu alte cuvinte, bazate pe ordine nedeterministe. Acest lucru ar putea fi pe întregul rezultat al interogării sau în partiții. Exemplele includ atribuirea de valori unice rândurilor de rezultate, deduplicarea datelor și returnarea oricărui rând pe grup.
Rețineți că necesitatea de a atribui numere de rând pe bază de ordine nedeterministă este diferită de necesitatea de a le atribui pe baza unei ordine aleatorii. Cu prima, nu vă pasă în ce ordine sunt atribuite și dacă executările repetate ale interogării continuă să aloce aceleași numere de rând acelorași rânduri sau nu. Cu acesta din urmă, vă așteptați ca execuțiile repetate să schimbe în continuare ce rânduri sunt atribuite cu numerele de rând. Acest articol explorează diferite tehnici pentru calculul numerelor de rânduri cu ordine nedeterministe. Speranța este de a găsi o tehnică care să fie fiabilă și optimă.
Mulțumiri speciale lui Paul White pentru sfatul referitor la plierea constantă, pentru tehnica constantă de rulare și pentru că a fost întotdeauna o sursă excelentă de informații!
Când ordinea contează
Voi începe cu cazurile în care contează numărul de rânduri.
Voi folosi un exemplu numit T1 în exemplele mele. Utilizați următorul cod pentru a crea acest tabel și completați-l cu date eșantion:
Luați în considerare următoarea interogare (o vom numi Interogarea 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Aici doriți ca numerele rândurilor să fie alocate în cadrul fiecărui grup identificat de coloana grp, ordonate după coloana datacol. Când am rulat această interogare pe sistemul meu, am obținut următoarea ieșire:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Numerele de rând sunt atribuite aici într-o ordine parțial deterministă și parțial nedeterministă. Ceea ce vreau să spun prin aceasta este că aveți siguranța că în cadrul aceleiași partiții, un rând cu o valoare mai mare a datacolului va obține o valoare mai mare a numărului de rânduri. Cu toate acestea, deoarece datacol nu este unic în partiția grp, ordinea de atribuire a numerelor rândurilor între rândurile cu aceleași valori grp și datacol este nedeterministă. Acesta este cazul rândurilor cu valorile id 2 și 11. Ambele au valoarea grp A și valoarea datacol 50. Când am executat această interogare pe sistemul meu pentru prima dată, rândul cu id 2 a obținut rândul 2 și rândul cu ID-ul 11 a primit numărul de rând 3. Nu contează probabilitatea ca acest lucru să se întâmple în practică în SQL Server; dacă execut din nou interogarea, teoretic, rândul cu id 2 ar putea fi atribuit cu numărul rând 3 și rândul cu id 11 ar putea fi atribuit cu numărul rândului 2.
Dacă trebuie să atribuiți numere de rând pe baza într-o ordine complet deterministă, garantând rezultate repetabile la toate execuțiile interogării, atâta timp cât datele subiacente nu se modifică, aveți nevoie ca combinația de elemente din clauzele de partiționare și ordonare a ferestrei să fie unică. Acest lucru ar putea fi realizat în cazul nostru prin adăugarea codului de coloană la clauza de comandă a ferestrei ca un tiebreaker. Clauza OVER ar fi atunci:
OVER (PARTITION BY grp ORDER BY datacol, id)
În orice caz, atunci când calculează numerele de rând pe baza unor specificații de ordonare semnificative, cum ar fi în interogarea 1, SQL Server trebuie să proceseze rânduri ordonate prin combinația de partiționare a ferestrei și elemente de comandă. Acest lucru poate fi realizat fie prin extragerea datelor precomandate dintr-un index, fie prin sortarea datelor. În prezent, nu există un index pe T1 care să susțină calculul ROW_NUMBER în interogarea 1, așa că SQL Server trebuie să opteze pentru sortarea datelor. Acest lucru poate fi văzut în planul pentru interogarea 1 prezentat în figura 1.
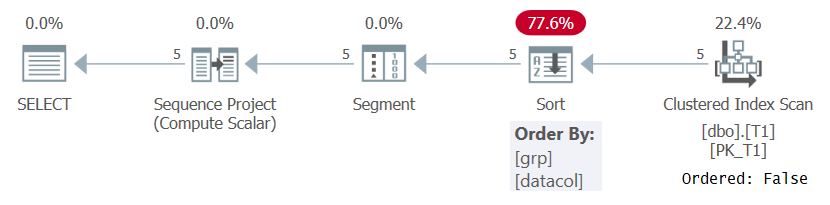 Figura 1: Planul pentru interogarea 1 fără un indice suport
Figura 1: Planul pentru interogarea 1 fără un indice suport
Observați că planul scanează datele din indexul grupat cu o proprietate Ordered: False. Aceasta înseamnă că scanarea nu trebuie să returneze rândurile ordonate de cheia index. Acesta este cazul, deoarece indexul grupat este utilizat aici doar pentru că se întâmplă să acopere interogarea și nu din cauza ordinii sale cheie. Planul aplică apoi o sortare, rezultând costuri suplimentare, scalare N Log N și timp de răspuns întârziat. Operatorul Segment produce un semn care indică dacă rândul este primul din partiție sau nu. În cele din urmă, operatorul Sequence Project atribuie numere de rând începând cu 1 în fiecare partiție.
Dacă doriți să evitați nevoia de sortare, puteți pregăti un index de acoperire cu o listă de chei bazată pe elementele de partiționare și ordonare și o listă de includere care se bazează pe elementele de acoperire.Îmi place să mă gândesc la acest index ca la un index POC (pentru partiționare, comandare și acoperire). Iată definiția POC care acceptă interogarea noastră:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Executați din nou interogarea 1:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Planul pentru această execuție este prezentat în Figura 2.
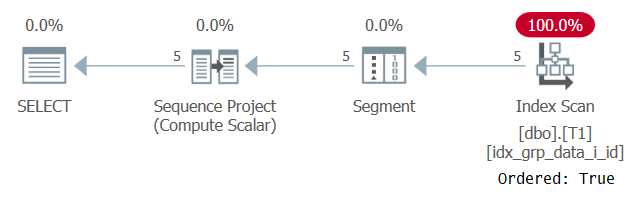 Figura 2: Plan pentru interogarea 1 cu un index POC
Figura 2: Plan pentru interogarea 1 cu un index POC
Rețineți că de data aceasta planul scanează indexul POC cu o proprietate Comandat: Adevărat. Aceasta înseamnă că scanarea garantează că rândurile vor fi returnate în ordinea cheilor index. Întrucât datele sunt extrase din comenzi, așa cum are nevoie funcția ferestrei, nu este nevoie de o sortare explicită. Scalarea acestui plan este liniară și timpul de răspuns este bun.
Când ordinea nu contează
Lucrurile devin un pic dificile atunci când trebuie să atribuiți numere de rând cu un caracter complet nedeterminist Ordine. Lucrul firesc pe care doriți să îl faceți într-un astfel de caz este să utilizați funcția ROW_NUMBER fără a specifica o clauză de ordine a ferestrei. Mai întâi, să verificăm dacă standardul SQL permite acest lucru. Iată partea relevantă a standardului care definește regulile de sintaxă pentru fereastră funcții:
Observați că elementul 6 listează funcțiile < funcție ntile >, < funcție lead sau lag >, < tip funcție de rang > sau ROW_NUMBER, iar apoi articolul 6a spune că pentru funcțiile < funcție ntile >, < funcția lead sau lag >, RANK sau DENSE_RANK clauza de comandă a ferestrei va fi b e prezent. Nu există un limbaj explicit care să indice dacă ROW_NUMBER necesită sau nu o clauză de comandă a ferestrei, dar menționarea funcției în articolul 6 și omiterea acesteia în 6a ar putea implica faptul că clauza este opțională pentru această funcție. Este destul de evident de ce funcții precum RANK și DENSE_RANK ar necesita o clauză de comandă a ferestrei, deoarece aceste funcții sunt specializate în gestionarea legăturilor, iar legăturile există numai atunci când există specificații de comandă. Cu toate acestea, ați putea vedea cu siguranță cum funcția ROW_NUMBER ar putea beneficia de o clauză opțională de comandă a ferestrei.
Deci, să încercăm și să încercăm să calculăm numerele de rând fără ordonarea ferestrelor în SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Această încercare are ca rezultat următoarea eroare:
Funcția „ROW_NUMBER” trebuie să aibă o clauză OVER cu ORDER BY.
Într-adevăr, dacă verificați documentația SQL Server despre funcția ROW_NUMBER, veți găsi următorul text:
ORDER Clauza BY determină secvența în care rândurilor li se atribuie ROW_NUMBER unic într-o partiție specificată. Este necesară. ”
Deci, se pare că clauza de comandă a ferestrei este obligatorie pentru funcția ROW_NUMBER din SQL Server . Apropo, acesta este și cazul în Oracle.
Trebuie să spun că nu sunt sigur că înțeleg reasonii în spatele acestei cerințe. Amintiți-vă că permiteți definirea numerelor de rând pe baza unei ordine parțial nedeterministe, ca în interogarea 1. Deci, de ce să nu permiteți nedeterminismul până la capăt? Poate că există un motiv la care nu mă gândesc. Dacă vă puteți gândi la un astfel de motiv, vă rugăm să împărtășiți.
În orice caz, ați putea susține că, dacă nu vă pasă de ordine, având în vedere că clauza de comandă a ferestrei este obligatorie, puteți specifica orice Ordin. Problema cu această abordare este că, dacă comandați în funcție de o coloană din tabelele solicitate, aceasta ar putea implica o penalizare de performanță inutilă. Atunci când nu există un index suport, veți plăti pentru sortare explicită. Atunci când există un index suport, limitați motorul de stocare la o strategie de scanare a comenzii indexului (urmând lista indexată cu indexuri). Nu îi permiteți o mai mare flexibilitate, așa cum se întâmplă de obicei atunci când ordinea nu contează în alegerea între o scanare a comenzilor indexate și o scanare a comenzilor de alocare (pe baza paginilor IAM).
O idee care merită încercată este de a specifica o constantă, cum ar fi 1, în clauza de ordine a ferestrei. Dacă este acceptat, ați spera că optimizatorul este suficient de inteligent pentru a realiza că toate rândurile au aceeași valoare, deci nu există o relevanță reală a comenzii și, prin urmare, nu este nevoie să forțați o scanare de sortare sau de indexare. Iată o interogare care încearcă această abordare:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Din păcate, SQL Server nu acceptă această soluție. Generează următoarea eroare:
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă indici întregi ca expresii de clauză ORDER BY.
Aparent, SQL Server presupune că, dacă utilizați o constantă de număr întreg în clauza de ordine a ferestrei, aceasta reprezintă o poziție ordinală a unui element din lista SELECT, ca atunci când specificați un număr întreg în prezentarea ORDINARE Clauza BY. Dacă acesta este cazul, o altă opțiune care merită încercată este să specificați o constantă care nu este completă, ca așa:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Se pare că și această soluție nu este acceptată. SQL Server generează următoarea eroare:
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă constante ca expresii de clauză ORDER BY.
Se pare că clauza de comandă a ferestrei nu acceptă niciun fel de constantă.
Până acum am aflat următoarele despre relevanța de ordonare a ferestrei funcției ROW_NUMBER în SQL Server:
- ORDER BY este obligatoriu.
- Nu se poate comanda după o constantă întreagă, deoarece SQL Server crede că încercați să specificați o poziție ordinală în SELECT.
- Nu se poate comanda după orice fel de constantă.
Concluzia este că ar trebui să ordonați după expresii care nu sunt constante. Evident, puteți comanda după o listă de coloane din tabelul (tabelele) interogat (e). Dar suntem într-o căutare de a găsi o soluție eficientă în care optimizatorul să poată realiza că nu există relevanță pentru ordonare.
Pliere constantă
Concluzia de până acum este că nu puteți utiliza constante înClauza de ordine a ferestrei ROW_NUMBER, dar ce se întâmplă cu expresiile bazate pe constante, cum ar fi în următoarea interogare:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Cu toate acestea, această încercare este victima unui proces cunoscut ca constant plierea, care are în mod normal un impact pozitiv asupra performanței asupra interogărilor. Ideea din spatele acestei tehnici este de a îmbunătăți performanța interogării prin plierea unor expresii bazate pe constante la constantele lor de rezultat într-un stadiu incipient al procesării interogării. Aici puteți găsi detalii despre ce tipuri de expresii pot fi pliate constant. Expresia noastră 1 + 0 este pliată la 1, rezultând în aceeași eroare pe care ați obținut-o când ați specificat direct constanta 1:
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă indici întregi ca expresii de clauză ORDER BY.
V-ați confrunta cu o situație similară atunci când încercați să concatenați două caractere de caractere șir, astfel:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Veți primi aceeași eroare pe care ați obținut-o atunci când ați specificat literal „Fără comandă” direct:
Windowed funcțiile, agregatele și funcțiile NEXT VALUE FOR nu acceptă constante ca expresii de clauză ORDER BY.
Lumea Bizarro – erori care previn erorile
Viața este plină de surprize …
Un lucru care împiedică plierea constantă este atunci când expresia ar duce în mod normal la o eroare. De exemplu, expresia 2147483646 + 1 poate fi pliată constant, deoarece rezultă o valoare validă de tip INT. În consecință, o încercare de a rula următoarea interogare nu reușește:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Funcții, agregate și valoare NEVOLUȚĂ Funcțiile FOR nu acceptă indici întregi ca expresii de clauză ORDER BY.
Cu toate acestea, expresia 2147483647 + 1 nu poate fi îndoită constant, deoarece o astfel de încercare ar fi dus la o eroare de depășire INT. Implicația asupra comenzii este destul de interesantă. Încercați următoarea interogare (o vom numi Interogarea 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
În mod ciudat, această interogare rulează cu succes! Ceea ce se întâmplă este că, pe de o parte, SQL Server nu reușește să aplice o pliere constantă și, prin urmare, ordonarea se bazează pe o expresie care nu este o singură constantă. Pe de altă parte, optimizatorul calculează că valoarea de comandă este aceeași pentru toate rândurile, deci ignoră expresia de comandă cu totul. Acest lucru este confirmat la examinarea planului pentru această interogare, așa cum se arată în Figura 3.
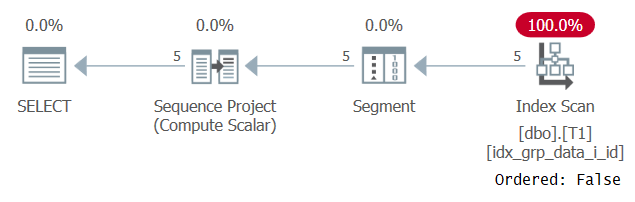 Figura 3: Planul pentru Interogarea 2
Figura 3: Planul pentru Interogarea 2
Respectați că planul scanează un indice de acoperire cu o proprietate Comandată: falsă. Acesta a fost exact obiectivul nostru de performanță.
În mod similar, următoarea interogare implică o încercare de pliere constantă reușită și, prin urmare, nu reușește:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă indici întregi ca expresii de clauză ORDER BY.
Următoarea interogare implică o încercare de pliere constantă eșuată și, prin urmare, reușește, generând planul prezentat anterior în Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Următoarele interogarea implică o încercare de pliere constantă de succes (VARCHAR literal „1” este implicit convertit în INT 1, iar apoi 1 + 1 este pliat la 2) și, prin urmare, nu reușește:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă indici întregi ca expresii de clauză ORDER BY.
Următoarea interogare implică o încercarea de pliere constantă eșuată (nu poate converti „A” în INT) și, prin urmare, reușește, generând planul prezentat anterior în Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Sincer să fiu, chiar dacă această tehnică bizarro ne atinge obiectivul de performanță inițial, nu pot spune că o consider sigură și, prin urmare, nu mă simt așa de confortabil bazându-mă pe ea. . coloană aliasată bazată pe o constantă și utilizând o variabilă.
După cum explic în bug-urile T-SQL, capcanele și cele mai bune practici – determinism, majoritatea funcțiilor din T-SQL sunt evaluate o singură dată pe referință în interogare – nu o dată pe rând. Acesta este cazul chiar și cu majoritatea funcțiilor nedeterministe precum GETDATE și RAND. Există foarte puține excepții de la această regulă, cum ar fi funcțiile NEWID și CRYPT_GEN_RANDOM, care sunt evaluate o dată pe rând. Majoritatea funcțiilor, cum ar fi GETDATE, @@ SPID și multe altele, sunt evaluate o dată la începutul interogării, iar valorile lor sunt apoi considerate constante de rulare. O referință la astfel de funcții nu se îndoaie constant. Aceste caracteristici fac ca o constantă de rulare care se bazează pe o funcție să fie o alegere bună ca element de comandă a ferestrei și, într-adevăr, se pare că T-SQL o acceptă. În același timp, optimizatorul își dă seama că, în practică, nu există nicio relevanță de ordonare, evitând penalizări de performanță inutile.
Iată un exemplu care utilizează funcția GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Această interogare primește același plan prezentat mai devreme în Figura 3.
Iată un alt exemplu care utilizează funcția @@ SPID (returnarea ID-ului sesiunii curente):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Cum rămâne cu funcția PI? Încercați următoarea interogare:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Acesta nu reușește cu următoarea eroare:
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă constante ca expresii de clauză ORDER BY.
Funcțiile precum GETDATE și @@ SPID sunt reevaluate o dată pe execuția planului, deci nu pot obține constant pliat. PI reprezintă întotdeauna aceeași constantă și, prin urmare, se îndoaie constant.
După cum sa menționat mai devreme, există foarte puține funcții care sunt evaluate o dată pe rând, cum ar fi NEWID și CRYPT_GEN_RANDOM. Acest lucru le face o alegere proastă ca element de comandă a ferestrei dacă aveți nevoie de o ordine nedeterministă – să nu vă confundați cu ordinea aleatorie. De ce să plătiți o penalitate de sortare inutilă?
Iată un exemplu care utilizează funcția NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Planul pentru această interogare este prezentat în Figura 4, confirmând că SQL Server a adăugat explicit sortare pe baza rezultatului funcției.
 Figura 4: Plan pentru interogarea 3
Figura 4: Plan pentru interogarea 3
Dacă doriți ca numerele rândurilor să fie atribuite în ordine aleatorie, prin toate mijloacele, aceasta este tehnica pe care doriți să o utilizați. Trebuie doar să fiți conștienți de faptul că acesta implică costul sortării.
Utilizarea unei subinterogări
De asemenea, puteți utiliza o subinterogare bazată pe o constantă ca expresie de ordonare a ferestrei (de exemplu, ORDER BY (SELECTAȚI „Fără comandă”)). De asemenea, cu această soluție, optimizatorul SQL Server recunoaște faptul că nu există relevanță pentru comandă și, prin urmare, nu impune o sortare inutilă sau limitează opțiunile motorului de stocare la cele care trebuie să garanteze ordinea. Încercați să rulați următoarea interogare ca exemplu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Obțineți același plan prezentat anterior în Figura 3.
Unul dintre marile beneficii din această tehnică este că puteți adăuga propria atingere personală.Poate vă plac foarte mult NULL-urile:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Poate că îți place foarte mult un anumit număr:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Poate doriți să trimiteți cuiva un mesaj:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Obțineți ideea.
Realizabil, dar incomod
Există câteva tehnici care funcționează, dar sunt puțin ciudate. Una este să definiți un alias de coloană pentru o expresie bazată pe o constantă și apoi să utilizați acel alias de coloană ca element de ordonare a ferestrei. Puteți face acest lucru fie utilizând o expresie de tabel, fie cu operatorul CROSS APPLY și un constructor de valori de tabel. Iată un exemplu pentru acesta din urmă:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Obțineți același plan prezentat anterior în Figura 3.
O altă opțiune este utilizarea unei variabile ca element de ordonare a ferestrei:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Această interogare primește și planul prezentat mai devreme în Figura 3.
Ce se întâmplă dacă folosesc propriul meu UDF ?
S-ar putea să credeți că utilizarea propriului UDF care returnează o constantă ar putea fi o alegere bună ca element de comandă a ferestrei atunci când doriți o ordine nedeterministă, dar nu este. Luați în considerare următoarea definiție UDF ca exemplu:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Încercați să utilizați UDF ca clauză de ordonare a ferestrei, așa (vom numi aceasta Interogarea 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Înainte de SQL Server 2019 (sau nivelul de compatibilitate paralel < 150), funcțiile definite de utilizator sunt evaluate pe rând . Chiar dacă întoarce o constantă, nu se aliniază. În consecință, pe de o parte puteți utiliza un astfel de UDF ca element de comandă a ferestrei, dar pe de altă parte, acest lucru are ca rezultat o pedeapsă de sortare. Acest lucru este confirmat prin examinarea planului pentru această interogare, așa cum se arată în Figura 5.
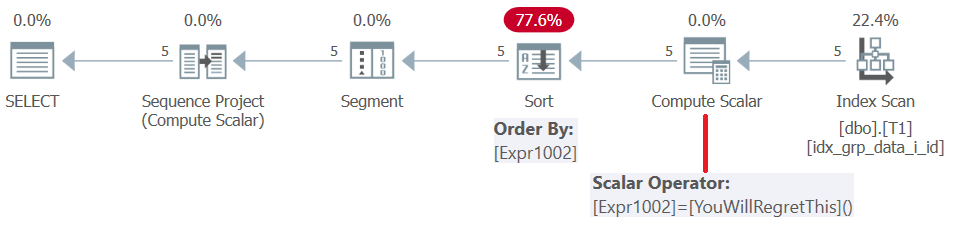 Figura 5: Planul pentru interogarea 4
Figura 5: Planul pentru interogarea 4
Începând cu SQL Server 2019, sub nivelul de compatibilitate > = 150, astfel de funcții definite de utilizator sunt aliniate, ceea ce este în mare parte un lucru grozav, dar în cazul nostru are ca rezultat o eroare:
Funcțiile Windowed, agregatele și funcțiile NEXT VALUE FOR nu acceptă constante ca expresii de clauză ORDER BY.
Deci, utilizând un UDF bazat pe o constantă ca element de comandă a ferestrei fie forțează o sortare, fie o eroare, în funcție de versiunea SQL Server pe care o utilizați și de nivelul de compatibilitate al bazei de date. Pe scurt, nu faceți acest lucru.
Numerele de rânduri partiționate cu ordine nedeterministică
Un caz de utilizare obișnuit pentru numerele de rânduri partiționate bazate pe ordinea nedeterministică este returnarea oricărui rând pe grup. Având în vedere că, prin definiție, există un element de partiționare în acest scenariu, ați crede că o tehnică sigură într-un astfel de caz ar fi utilizarea elementului de partiționare a ferestrei și ca element de ordonare a ferestrelor. Ca prim pas, calculați astfel de numere de rând:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Planul pentru această interogare este prezentat în Figura 6.
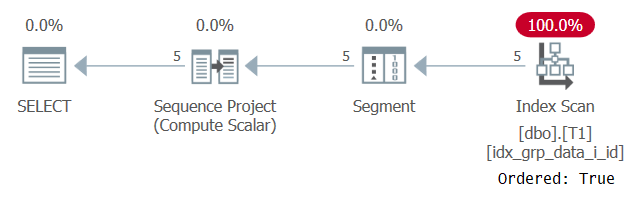 Figura 6: Planul pentru interogarea 5
Figura 6: Planul pentru interogarea 5
Motivul pentru care indexul nostru suport este scanat cu o proprietate Comandat: Adevărat se datorează faptului că SQL Server trebuie să proceseze rândurile fiecărei partiții ca o singură bucată. Acesta este cazul înainte de filtrare. Dacă filtrați un singur rând pe partiție, aveți opțiuni atât pentru algoritmi bazați pe comenzi, cât și pentru hash.
Al doilea pas este plasarea interogării cu calculul numărului de rând într-o expresie de tabel și în interogarea exterioară filtrează rândul cu rândul 1 în fiecare partiție, astfel:
Teoretic, această tehnică ar trebui să fie sigură, dar Paul White a găsit o eroare care arată că folosind această metodă puteți obține atribute de la diferite rânduri sursă în rândul rezultat returnat pe fiecare partiție. Utilizarea unei constante de runtime bazată pe o funcție sau o interogare bazată pe o constantă, deoarece elementul de comandă pare a fi sigur chiar și cu acest scenariu, așa că asigurați-vă că utilizați o soluție, cum ar fi următoarea:
Nimeni va trece pe aici fără permisiunea mea
Încercarea de a calcula numerele de rând pe baza unei ordini nedeterministe este o nevoie obișnuită. Ar fi fost bine dacă T-SQL ar fi făcut ca clauza de comandă a ferestrei să fie opțională pentru funcția ROW_NUMBER, dar nu o face. Dacă nu, ar fi fost bine dacă ar fi permis cel puțin utilizarea unei constante ca element de comandă, dar nici aceasta nu este o opțiune acceptată.Dar dacă întrebați frumos, sub forma unei subinterogări bazate pe o constantă sau o constantă de rulare bazată pe o funcție, SQL Server o va permite. Acestea sunt cele două opțiuni cu care mă simt cel mai confortabil. Nu prea mă simt confortabil cu expresiile eronate ciudate care par să funcționeze, așa că nu pot recomanda această opțiune.