A robots Fișierul .txt conține directive pentru motoarele de căutare. Puteți să-l utilizați pentru a împiedica motoarele de căutare să acceseze cu crawlere anumite părți ale site-ului dvs. web și pentru a oferi motoarelor de căutare sfaturi utile cu privire la modul în care acestea vă pot accesa cel mai bine site-ul. Fișierul robots.txt joacă un rol important în SEO.
Când implementați robots.txt, țineți cont de următoarele bune practici:
- Aveți grijă când faceți modificări robots.txt: acest fișier are potențialul de a face părți mari ale site-ului dvs. web inaccesibile pentru motoarele de căutare.
- Fișierul robots.txt ar trebui să se afle în rădăcina site-ului dvs. web (de ex.
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpsauhttps). - Diferite motoare de căutare interpretează directivele în mod diferit. În mod implicit, prima directivă de potrivire câștigă întotdeauna. Dar, cu Google și Bing, specificitatea câștigă.
- Evitați să utilizați directiva de întârziere cu crawlere pentru motoarele de căutare cât mai mult posibil.
Ce este un fișier robots.txt?
Un fișier robots.txt spune motoarelor de căutare care sunt regulile de implicare ale site-ului dvs. web. O mare parte a realizării SEO înseamnă trimiterea semnalelor potrivite către motoarele de căutare, iar robots.txt este una dintre modalitățile de a comunica preferințele dvs. de accesare cu crawlere către motoarele de căutare.
În 2019, am văzut destul de mult unele evoluții în jurul standardului robots.txt: Google a propus o extensie a Protocolului de excludere a roboților și a deschis parsorul său robots.txt.
TL; DR
- Roboții Google Interpretul .txt este destul de flexibil și surprinzător de iertător.
- În cazul directivelor de confuzie, Google greșește în siguranță și presupune că secțiunile ar trebui restricționate, mai degrabă decât nerestricționate.
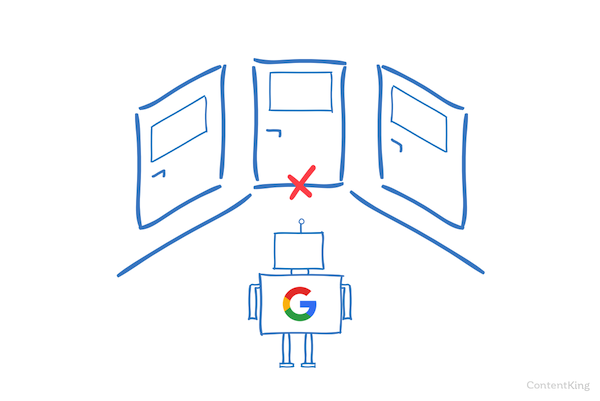
Motoarele de căutare verifică regulat fișierul robots.txt al unui site web pentru a vedea dacă există instrucțiuni pentru accesarea cu crawlere a site-ului web. Aceste instrucțiuni le numim directive.
Dacă nu există fișier robots.txt prezent sau dacă nu există directive aplicabile, motoarele de căutare vor accesa cu crawlere întregul site web.
Deși toate motoarele de căutare importante respectă fișierul robots.txt, motoarele de căutare pot alege să ignore (părți din) fișierul robots.txt. În timp ce directivele din fișierul robots.txt sunt un semnal puternic pentru motoarele de căutare, este important să ne amintim că fișierul robots.txt este mai degrabă un set de directive opționale pentru motoarele de căutare decât un mandat.

Robotul.txt este cel mai sensibil fișier din universul SEO. Un singur caracter poate sparge un întreg site.
Terminologia în jurul fișierului robots.txt
Fișierul robots.txt este implementarea standardului de excludere a roboților, sau denumit și protocolul de excludere a roboților.
De ce ar trebui să vă pese de robots.txt?
Robotii.txt joacă un rol esențial din punct de vedere SEO. Acesta le spune motoarelor de căutare cum pot să acceseze cu crawlere cel mai bine site-ul dvs. web.
Utilizând fișierul robots.txt puteți împiedica accesarea anumitor părți ale site-ului dvs. de către motoarele de căutare, preveni conținutul duplicat și le oferă motoarelor de căutare sfaturi utile despre vă poate accesa cu crawlere site-ul web mai eficient.
Cu toate acestea, aveți grijă când efectuați modificări la robot.txt: acest fișier are potențialul de a face părți mari ale site-ului dvs. web inaccesibile pentru motoarele de căutare.

Robots.txt este deseori folosit pentru a reduce conținutul duplicat, prin urmare uciderea legăturilor interne, așa că fii foarte atent cu el. Sfatul meu este să îl folosiți numai pentru fișiere sau pagini pe care motoarele de căutare nu ar trebui să le vadă niciodată sau care pot avea un impact semnificativ asupra accesării cu crawlere, permițându-le să intre. Exemple obișnuite: zone de conectare care generează multe adrese URL diferite, zone de testare sau unde poate exista o navigație cu mai multe fațete. Și asigurați-vă că vă monitorizați fișierul robots.txt pentru orice problemă sau modificare.

Majoritatea problemelor pe care le văd cu fișierele robots.txt se împart în trei compartimente:
- Manipularea greșită a metacaracterelor. Este destul de obișnuit să vezi părți ale site-ului blocate care au fost destinate blocării. Uneori, dacă nu sunteți atenți, directivele pot intra, de asemenea, în conflict unele cu altele.
- Cineva, cum ar fi un dezvoltator, a făcut o schimbare din senin (de multe ori atunci când împingeți un cod nou) și a modificat din greșeală robotul.txt fără știrea dvs.
- Includerea directivelor care nu aparțin unui fișier robots.txt. Robots.txt este standard web și este oarecum limitat. De multe ori văd dezvoltatorii care elaborează directive care pur și simplu nu vor funcționa (cel puțin pentru majoritatea masivă a crawlerelor). Uneori este inofensiv, uneori nu atât de mult.
Exemplu
Să vedem un exemplu pentru a ilustra acest lucru:
Tu Rulați un site de comerț electronic, iar vizitatorii pot folosi un filtru pentru a căuta rapid printre produsele dvs. Acest filtru generează pagini care prezintă practic același conținut ca și celelalte pagini. Acest lucru funcționează excelent pentru utilizatori, dar încurcă motoarele de căutare deoarece creează conținut duplicat.
Nu doriți ca motoarele de căutare să indexeze aceste pagini filtrate și să își piardă timpul valoros pe aceste adrese URL cu conținut filtrat. Prin urmare, ar trebui să configurați regulile Disallow, astfel încât motoarele de căutare să nu acceseze aceste pagini filtrate ale produselor.
Prevenirea conținutului duplicat se poate face și cu ajutorul adresei URL canonice sau eticheta meta-roboți, cu toate acestea acestea nu se adresează, permițând motoarelor de căutare să acceseze numai paginile care contează.
Utilizarea unei adrese URL canonice sau a etichetei meta-roboți nu va împiedica motoarele de căutare să acceseze cu crawlere aceste pagini. Acesta va împiedica motoarele de căutare să afișeze aceste pagini în rezultatele căutării. Deoarece motoarele de căutare au timp limitat pentru accesarea cu crawlere a unui site web, acest timp ar trebui să fie petrecut pe paginile pe care doriți să le apară în motoarele de căutare.
Este posibil ca un fișier robots.txt configurat incorect să vă împiedice performanța SEO. Verificați imediat dacă acesta este cazul site-ului dvs. web!

Este un instrument foarte simplu, dar un fișier robots.txt poate provoca o mulțime de probleme dacă nu este configurat corect, în special pentru site-uri web mai mari. Este foarte ușor să comiteți greșeli, cum ar fi blocarea unui întreg site după lansarea unui nou design sau CMS sau blocarea secțiunilor unui site care ar trebui să fie private. Pentru site-urile web mai mari, asigurarea eficientă a accesării cu crawlere a Google este foarte importantă, iar un fișier robots.txt bine structurat este un instrument esențial în acest proces.
Trebuie să vă alocați timp pentru a înțelege ce secțiuni ale site-ului dvs. sunt cel mai bine ținute la distanță. de la Google, astfel încât să cheltuiască cât mai mult din resursele lor accesând cu crawlere paginile care vă interesează cu adevărat.
Cum arată un fișier robots.txt?
Un exemplu despre cum poate fi un fișier simplu robots.txt pentru un site web WordPress arata ca:
Să explicăm anatomia unui fișier robots.txt pe baza exemplului de mai sus:
- User-agent:
user-agentindică pentru ce căutare motoare, directivele care urmează sunt menite. -
*: aceasta indică faptul că directivele sunt destinate tuturor motoarelor de căutare. -
Disallow: aceasta este o directivă care indică ce conținut nu este accesibiluser-agent. -
/wp-admin/: acesta estepathcare este inaccesibil pentruuser-agent.
În rezumat: acest fișier robots.txt le spune tuturor motoarelor de căutare să rămână în afara directorului /wp-admin/.
Să analizăm diferitele componentele fișierelor robots.txt mai detaliat:
- User-agent
- Nu permiteți
- Permiteți
- Sitemap
- Crawl-delay
User-agent în robots.txt
Fiecare motor de căutare trebuie să se identifice cu un user-agent. Roboții Google se identifică ca Googlebot de exemplu, roboții Yahoo ca Slurp și robotul lui Bing ca BingBot și așa mai departe.
Înregistrarea user-agent definește începutul unui grup de directive. Toate directivele dintre prima user-agent și următoarea înregistrare user-agent sunt tratate ca directive pentru prima user-agent.
Directivele se pot aplica anumitor agenți de utilizator, dar pot fi de asemenea aplicabile tuturor agenților de utilizatori. În acest caz, se folosește un wildcard: User-agent: *.
Directiva Disallow în robots.txt
Puteți spune motoarelor de căutare să nu acceseze anumite fișiere, pagini sau secțiuni ale site-ului dvs. web. Acest lucru se face folosind directiva Disallow. Directiva Disallow este urmată de path care nu ar trebui accesată. Dacă nu este definit niciun path, directiva este ignorată.
Exemplu
În acest exemplu, tuturor motoarelor de căutare li se spune să nu acceseze directorul /wp-admin/.
Permiteți directiva în robots.txt
Directiva Allow este utilizată pentru a contracara o directivă Disallow. Directiva Allow este acceptată de Google și Bing. Utilizând împreună directivele Allow și Disallow, puteți spune motoarelor de căutare că pot accesa un anumit fișier sau pagină dintr-un director care altfel nu este permis. Directiva Allow este urmată de path care poate fi accesată. Dacă nu este definit path, directiva este ignorată.
Exemplu
În exemplul de mai sus, toate motoarele de căutare nu au acces la /media/ director, cu excepția fișierului /media/terms-and-conditions.pdf.
Important: atunci când utilizați Allow și Disallow directivele împreună, asigurați-vă că nu utilizați metacaractere, deoarece acest lucru poate duce la directive conflictuale.
Exemplu de directive conflictuale
Motoarele de căutare nu vor ști ce să facă cu adresa URL . Nu le este clar dacă li se permite accesul. Atunci când directivele nu sunt clare pentru Google, vor merge cu cea mai puțin restrictivă directivă, ceea ce înseamnă că, în acest caz, ar avea acces la
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt este una dintre funcțiile pe care le văd cel mai frecvent implementate incorect, deci nu blochează ceea ce doreau să blocheze sau blochează mai mult decât se așteptau și are un impact negativ asupra site-ului lor web. Robots.txt este un instrument foarte puternic, dar prea des este configurat incorect.
Folosind metacaracticul *
Nu numai metacaracterul poate fi utilizat pentru definirea user-agent, dar poate fi folosit și pentru potrivesc adresele URL. Comodul este acceptat de Google, Bing, Yahoo și Ask.
Exemplu
În exemplul de mai sus, toate motoarele de căutare nu au acces la adrese URL care includ un semn de întrebare (?).

Dezvoltatori sau proprietarii de site-uri par să creadă că pot utiliza tot felul de expresii regulate într-un fișier robots.txt, în timp ce doar o cantitate foarte limitată de potrivire a modelelor este de fapt valabilă – de exemplu, metacaractere (
*). Se pare că există o confuzie între fișierele .htaccess și fișierele robots.txt din când în când.
Utilizarea sfârșitului URL-ului $
Pentru a indica sfârșitul unei adrese URL, puteți utiliza semnul dolar ($) la sfârșitul path.
Exemplu
În exemplul de mai sus motoarele de căutare nu au acces la toate adresele URL care se termină cu .php . Adrese URL cu parametri, de ex. nu ar fi respins, deoarece adresa URL nu se termină după .php.
Adăugați un sitemap la roboți. txt
Chiar dacă fișierul robots.txt a fost inventat pentru a spune motoarelor de căutare ce pagini nu trebuie accesate cu crawlere, fișierul robots.txt poate fi, de asemenea, utilizat pentru a direcționa motoarele de căutare către sitemap-ul XML. Acest lucru este acceptat de Google, Bing, Yahoo și Ask.
Sitemap-ul XML ar trebui să fie menționat ca o adresă URL absolută. Adresa URL nu trebuie să se afle pe aceeași gazdă ca fișierul robots.txt.
Referirea sitemap-ului XML în fișierul robots.txt este una dintre cele mai bune practici pe care vă sfătuim să o faceți întotdeauna, chiar dacă este posibil să fi trimis deja sitemap-ul XML în Google Search Console sau Bing Webmaster Tools. Nu uitați, există mai multe motoare de căutare acolo.
Vă rugăm să rețineți că este posibil să faceți referire la mai multe sitemap-uri XML într-un fișier robots.txt.
Exemple
Multiple Sitemap-uri XML definite într-un fișier robots.txt:
Un singur sitemap XML definit într-un robot.fișier txt:
Exemplul de mai sus spune tuturor motoarelor de căutare să nu acceseze directorul /wp-admin/ și că sitemap-ul XML poate fi găsit la
Comments are preceded by a # și poate fie să fie plasat la începutul unei linii, fie după o directivă pe aceeași linie. Totul după # va fi ignorat. Aceste comentarii sunt destinate numai oamenilor.
Exemplul 1
Exemplul 2
Exemplele de mai sus comunică același mesaj.
Crawl-delay în robots.txt
Crawl-delay este o directivă neoficială utilizată pentru a preveni supraîncărcarea serverelor cu prea multe solicitări. Dacă motoarele de căutare sunt capabile să suprasolicite un server, adăugarea Crawl-delay la fișierul dvs. robots.txt este doar o soluție temporară. Faptul este că site-ul dvs. rulează într-un mediu de găzduire slab și / sau site-ul dvs. web este configurat incorect și ar trebui să remediați acest lucru cât mai curând posibil.
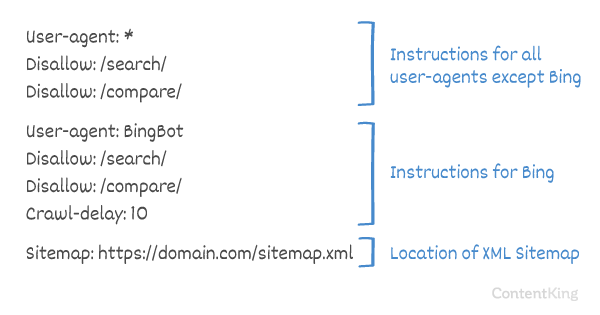
Modul în care motoarele de căutare gestionează Crawl-delay diferă. Mai jos vă explicăm modul în care motoarele de căutare majore îl gestionează.
Crawl-delay și Google
Crawlerul Google, Googlebot, nu acceptă Crawl-delay, așa că nu vă deranjați să definiți o întârziere cu crawlere Google.
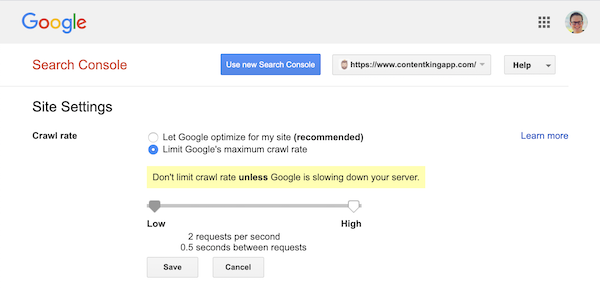
Cu toate acestea, Google acceptă definirea unei rate de accesare cu crawlere (sau „rată de solicitare”, dacă doriți ) în Google Search Console.
- Conectați-vă la vechea Consolă de căutare Google.
- Alegeți site-ul web doriți să definiți rata de accesare cu crawlere.
- Există o singură setare pe care o puteți modifica:
Crawl rate, cu un glisor în care puteți seta rata de accesare cu crawlere preferată. În mod implicit rata de accesare cu crawlere este setată la „Permiteți Google să optimizeze site-ul meu (recomandat)”.
Așa arată în Google Search Console:
Crawl-delay și Bing, Yahoo și Yandex
Bing, Yahoo și Yandex toți susțin Crawl-delay directivă pentru limitarea accesării cu crawlere a unui site web. Totuși, interpretarea lor cu privire la întârzierea cu crawlere este ușor diferită, așa că asigurați-vă că verificați documentația lor:
- Bing și Yahoo
- Yandex
Directiva Crawl-delay ar trebui plasată imediat după directivele Disallow sau Allow.
Exemplu:
Crawl-delay și Baidu
Baidu nu acceptă directiva crawl-delay, totuși este posibil să înregistrați un cont Baidu Webmaster Tools în pe care îl puteți controla frecvența de accesare cu crawlere, similar cu Google Search Console.
Când utilizați un fișier robots.txt?
Vă recomandăm să utilizați întotdeauna un fișier robots.txt. Nu aveți absolut nici un rău dacă aveți unul și este un loc minunat pentru a transmite directivelor motoarelor de căutare despre modul în care acestea pot să vă acceseze cu crawlere cel mai bine site-ul web.

Robotul.txt poate fi util pentru a împiedica accesarea cu crawlere și indexare a anumitor zone sau documente de pe site-ul dvs. Exemple sunt, de exemplu, site-ul intermediar sau PDF-urile. Planificați cu atenție ceea ce trebuie indexat de motoarele de căutare și țineți cont de faptul că conținutul care a devenit inaccesibil prin intermediul robots.txt poate fi găsit în continuare de crawlerele motoarelor de căutare dacă este conectat la alte zone ale site-ului web.
Cele mai bune practici Robots.txt
Cele mai bune practici robots.txt sunt clasificate după cum urmează:
- Locația și numele fișierului
- Ordinea de prioritate
- Doar un grup de directive pentru fiecare robot
- Fiți cât mai specific posibil
- Directivele pentru toți roboții, inclusiv directivele pentru un anumit robot
- Fișierul Robots.txt pentru fiecare (sub) domeniu.
- Instrucțiuni conflictuale: robots.txt vs. Google Search Console
- Monitorizați fișierul robots.txt
- Nu utilizați noindex în robot.txt
- Prevenirea BOM-ului UTF-8 în fișierul robots.txt
Locație și numele fișierului
Fișierul robots.txt trebuie întotdeauna plasat în e root al unui site web (în directorul de nivel superior al gazdei) și poartă numele fișierului robots.txt, de exemplu: . Rețineți că adresa URL a fișierului robots.txt este, ca orice altă adresă URL, diferențiată de majuscule și minuscule.
Dacă fișierul robots.txt nu poate fi găsit în locația implicită, motoarele de căutare vor presupune că nu există directive și se vor deplasa cu crawlere pe site-ul dvs.
Ordinea de prioritate
Este important să rețineți că motoarele de căutare gestionează fișierele robots.txt diferit. În mod implicit, prima directivă de potrivire câștigă întotdeauna.
Cu toate acestea, cu Google și Bing câștigă specificitatea. De exemplu: o directivă Allow câștigă o directivă Disallow dacă lungimea caracterului său este mai mare.
Exemplu
În exemplu mai presus de toate motoarele de căutare, inclusiv Google și Bing nu au permisiunea de a accesa directorul /about/, cu excepția subdirectorului /about/company/.
Exemplu
În exemplul de mai sus, tuturor motoarelor de căutare, cu excepția Google și Bing, nu li se permite accesul la directorul /about/. Aceasta include directorul /about/company/.
Google și Bing au acces permis, deoarece directiva Allow este mai lungă decât Disallow directivă.
Numai un grup de directive pe robot
Puteți defini un singur grup de directive pentru fiecare motor de căutare. Dacă aveți mai multe grupuri de directive pentru un motor de căutare, acestea le încurcă.
Fiți cât mai specific posibil
Directiva Disallow se declanșează la potrivirile parțiale ca bine. Fiți cât mai specific posibil atunci când definiți directiva Disallow pentru a preveni interzicerea neintenționată a accesului la fișiere.
Exemplu:
Exemplul de mai sus nu permite accesul motoarelor de căutare la:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Directivele pentru toți roboții, inclusiv directivele pentru un anumit robot
Pentru un robot este valabil doar un grup de directive. În cazul în care directivele destinate tuturor roboților sunt urmate de directive pentru un anumit robot, numai aceste directive specifice vor fi luate în considerare. Pentru ca robotul specific să respecte și directivele pentru toți roboții, trebuie să repetați aceste directive pentru robotul specific.
Să vedem un exemplu care va clarifica acest lucru:
Exemplu
Dacă nu doriți ca googlebot să acceseze /secret/ și /not-launched-yet/, atunci trebuie să repetați aceste directive pentru googlebot în mod specific:
Rețineți că fișierul dvs. robots.txt este disponibil public. Dezactivarea secțiunilor site-ului web de acolo poate fi utilizată ca un vector de atac de către persoanele cu intenție rău intenționată.

Robots.txt poate fi periculos. Nu spui doar motoarelor de căutare unde nu vrei să le caute, le spui oamenilor unde îți ascunzi secretele murdare.
Fișier Robots.txt pentru fiecare (sub) domeniu
Numai directivele Robots.txt se aplică (sub) domeniului pe care este găzduit fișierul.
Exemple
este valabil pentru , dar nu pentru sau
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Am creat urmărirea și alertarea modificărilor robots.txt din acest motiv.
Vedem tot timpul: fișierele robots.txt se schimbă fără cunoștințe despre marketingul digital echipă. Nu fi persoana respectivă. Începeți să monitorizați fișierul robots.txt acum primiți alerte când se modifică!
Nu utilizați noindex în robot.txt
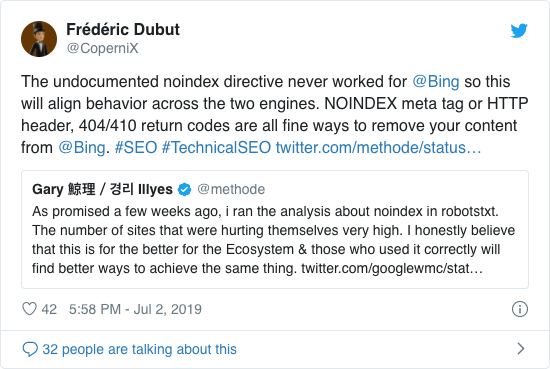
De ani de zile, Google a recomandat deja în mod deschis împotriva utilizării directivei neoficiale neindex. Cu toate acestea, de la 1 septembrie 2019, Google a încetat să o susțină în totalitate.
Directiva neoficială neindex nu a funcționat niciodată în Bing, așa cum a confirmat Frédéric Dubut în acest tweet:
Cel mai bun mod de a semnaliza motoarelor de căutare că paginile nu ar trebui indexate este folosirea etichetei meta-roboți sau a etichetei X-Robots .
Prevenirea BOM UTF-8 în fișierul robots.txt
BOM reprezintă semnul ordinii octeților, un caracter invizibil la începutul unui fișier folosit pentru a indica codificarea Unicode a unui fișier text.
În timp ce Google afirmă că ignoră marca de comandă opțională a octetului Unicode la începutul fișierului robots.txt, vă recomandăm să preveniți „BOM UTF-8”, deoarece am văzut că provoacă probleme cu interpretarea fișierul robots.txt de către motoarele de căutare.
Chiar dacă Google spune că se poate ocupa de acesta, iată două motive pentru a împiedica distrugerea UTF-8:
- Nu Nu vreau să existe nicio ambiguitate cu privire la preferințele dvs. în legătură cu accesarea cu crawlere la motoarele de căutare.
- Există și alte motoare de căutare, care ar putea să nu fie atât de iertătoare pe cât pretinde Google.
Exemple de robots.txt
În acest capitol vom acoperi o gamă largă de exemple de fișiere robots.txt:
- Permiteți tuturor roboților accesul la toate
- Interzice accesul tuturor roboților la tot
- Toți roboții Google nu au acces
- Toți roboții Google, cu excepția știrilor Googlebot, nu au acces
- Googlebot și Slurp nu au acces
- Toți roboții nu au acces la doi directoare
- Toți roboții nu au acces la un anumit fișier
- Googlebot nu are acces la / admin / și Slurp nu are acces la / private /
- Fișier Robots.txt pentru WordPress
- Fișier Robots.txt pentru Magento
Permiteți tuturor roboților accesul la toate
Există mai multe moduri pentru a spune motoarelor de căutare că pot accesa toate fișierele:
Sau să ai un fișier robots.txt gol sau să nu ai deloc un robots.txt.
Nu permite accesul tuturor roboților la tot
Exemplul robots.txt de mai jos spune tuturor motoarelor de căutare să nu acceseze întregul site:
Rețineți că doar un personaj suplimentar poate face diferența.
Toți roboții Google nu au acces
Vă rugăm să rețineți că atunci când dezactivați Googlebot, acest lucru este valabil pentru toți Googlebots. Aceasta include roboții Google care caută, de exemplu, știri (googlebot-news) și imagini (googlebot-images).
Toate Roboții Google, cu excepția știrilor Googlebot, nu au acces
Googlebot și Slurp nu au acces
Toți roboții nu au acces la două directoare
Toți roboții nu au acces la un anumit fișier
Googlebot nu are acces la / admin / și Slurp nu are acces la / private /
Robots.txt fișier pentru WordPress
Fișierul robots.txt de mai jos este optimizat special pentru WordPress, presupunând că:
- Nu doriți ca secțiunea de administrare să fie accesată cu crawlere.
- Nu doriți ca paginile de rezultate ale căutării interne să fie accesate cu crawlere.
- Nu doriți ca paginile de etichetă și autor să fie accesate cu crawlere.
- Nu trebuie Nu vreau ca pagina 404 să fie accesată cu crawlere.
Rețineți că acest fișier robots.txt va funcționa în majoritatea cazurilor, dar ar trebui să-l reglați întotdeauna și să-l testați pentru a vă asigura că se aplică situația exactă.
Fișierul Robots.txt pentru Magento
Fișierul robots.txt de mai jos este optimizat special pentru Magento și va face rezultate de căutare interne, pagini de autentificare, identificatori de sesiune și rezultat filtrat seturi care conțin price, color, material și size criterii inaccesibile crawlerelor.
Rețineți că acest fișier robots.txt va funcționa pentru majoritatea magazinelor Magento, dar dvs. ar trebui să îl ajustați întotdeauna și să-l testați pentru a vă asigura că se aplică situației dvs. exacte.
Încă aș căuta întotdeauna să blochez rezultatele căutării interne în robots.txt pe orice site, deoarece aceste tipuri de adrese URL de căutare sunt spații infinite și interminabile. Există mult potențial ca Googlebot să intre într-o capcană pe șenile.
Care sunt limitările fișierului robots.txt?
Fișierul Robots.txt conține directive
Chiar dacă robotul.txt este bine respectat de căutare motoare, este încă o directivă și nu un mandat.
Pagini care încă apar în rezultatele căutării
Pagini care sunt inaccesibile pentru motoarele de căutare din cauza roboților.txt, dar au linkuri către ele, pot apărea în continuare în rezultatele căutării dacă sunt conectate de pe o pagină care este accesată cu crawlere. Un exemplu de aspect:

Este posibil să eliminați aceste adrese URL de pe Google utilizând instrumentul de eliminare a adreselor URL din Google Search Console. Vă rugăm să rețineți că aceste adrese URL vor fi „ascunse” temporar numai. Pentru ca acestea să rămână în afara paginilor de rezultate Google, trebuie să trimiteți o solicitare de ascundere a adreselor URL la fiecare 180 de zile.

Utilizați robots.txt pentru a bloca backlink-urile afiliate nedorite și probabil dăunătoare. nu utilizați robots.txt pentru a preveni indexarea conținutului de către motoarele de căutare, deoarece acest lucru va eșua în mod inevitabil. În schimb, aplicați directiva noindex privind roboții atunci când este necesar.
Fișierul Robots.txt este stocat în cache până la 24 de ore
Google a indicat că un robot Fișierul .txt este, în general, stocat în cache până la 24 de ore. Este important să luați în considerare acest lucru atunci când efectuați modificări în fișierul robots.txt.
Nu este clar modul în care alte motoare de căutare se ocupă de stocarea în cache a robots.txt. , dar, în general, este bine să evitați stocarea în cache a fișierului robots.txt în av motoarele de căutare obișnuite durează mai mult decât este necesar pentru a putea prelua modificările.
Dimensiunea fișierului Robots.txt
Pentru fișierele robots.txt Google acceptă în prezent o limită de dimensiune a fișierului de 500 kibibyte (512 kilobyți). Orice conținut după această dimensiune maximă a fișierului poate fi ignorat.
Nu este clar dacă alte motoare de căutare au dimensiunea maximă a fișierelor pentru fișierele robots.txt.
Întrebări frecvente despre robots.txt
🤖 Cum arată un exemplu de robots.txt?
Iată un exemplu de conținut al unui robots.txt: User-agent: * Disallow:. Acest lucru le spune tuturor crawlerelor că pot accesa totul.
⛔ Ce face Disallow all face în robots.txt?
Când setați un robots.txt la „Disallow all”, sunteți în esență, le spune tuturor crawlerelor să se ferească. Niciun crawler, inclusiv Google, nu are acces la site-ul dvs. Acest lucru înseamnă că nu vor putea să acceseze cu crawlere, să indexeze și să claseze site-ul dvs. Acest lucru va duce la o scădere masivă a traficului organic.
✅ Ce înseamnă Permiteți toate să facă în robots.txt?
Când setați un robot.txt la „Permiteți toate”, spuneți fiecărui crawler că poate accesa fiecare adresă URL de pe site. Pur și simplu nu există reguli de implicare. Vă rugăm să rețineți că acesta este echivalentul de a avea un robots.txt gol sau de a nu avea deloc robots.txt.
🤔 Cât de important este robots.txt pentru SEO?
În în general, fișierul robots.txt este foarte important în scopuri SEO. Pentru site-urile web mai mari, robots.txt este esențial pentru a oferi motoarelor de căutare instrucțiuni foarte clare cu privire la ce conținut nu trebuie accesat.