La fonction de fenêtre ROW_NUMBER a de nombreuses applications pratiques, bien au-delà des besoins de classement évidents. La plupart du temps, lorsque vous calculez les numéros de ligne, vous devez les calculer en fonction d’un ordre et vous fournissez la spécification de tri souhaitée dans la clause d’ordre de fenêtre de la fonction. Cependant, il existe des cas où vous devez calculer les numéros de ligne sans ordre particulier; en d’autres termes, basé sur un ordre non déterministe. Cela peut concerner l’ensemble du résultat de la requête ou au sein des partitions. Les exemples incluent l’attribution de valeurs uniques aux lignes de résultats, la déduplication des données et le renvoi de n’importe quelle ligne par groupe.
Notez que devoir attribuer des numéros de ligne en fonction d’un ordre non déterministe est différent de devoir les attribuer en fonction d’un ordre aléatoire. Avec le premier, vous ne vous souciez pas de l’ordre dans lequel elles sont affectées, et si les exécutions répétées de la requête continuent d’attribuer les mêmes numéros de ligne aux mêmes lignes ou non. Avec ce dernier, vous vous attendez à ce que des exécutions répétées changent constamment quelles lignes sont attribuées avec quels numéros de ligne. Cet article explore différentes techniques de calcul des numéros de ligne avec un ordre non déterministe. L’espoir est de trouver une technique à la fois fiable et optimale.
Un merci spécial à Paul White pour le conseil concernant le pliage constant, pour la technique de la constante d’exécution et pour être toujours une excellente source d’informations!
Quand l’ordre compte
Je vais commencer par les cas où l’ordre des numéros de ligne est important.
J’utiliserai une table appelée T1 dans mes exemples. Utilisez le code suivant pour créer cette table et la remplir avec des exemples de données:
Considérez la requête suivante (nous l’appellerons Requête 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Ici, vous voulez que les numéros de ligne soient attribués dans chaque groupe identifié par la colonne grp, triés par la colonne datacol. Lorsque j’ai exécuté cette requête sur mon système, j’ai obtenu le résultat suivant:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Les numéros de ligne sont attribués ici dans un ordre partiellement déterministe et partiellement non déterministe. Ce que je veux dire par là, c’est que vous avez l’assurance que dans la même partition, une ligne avec une valeur de datacol plus grande obtiendra une valeur de numéro de ligne plus grande. Cependant, étant donné que datacol n’est pas unique dans la partition grp, l’ordre d’affectation des numéros de ligne entre les lignes avec les mêmes valeurs grp et datacol n’est pas déterministe. Tel est le cas avec les lignes avec les valeurs id 2 et 11. Les deux ont la valeur grp A et la valeur datacol 50. Lorsque j’ai exécuté cette requête sur mon système pour la première fois, la ligne avec l’id 2 a obtenu le numéro de ligne 2 et le la ligne avec l’ID 11 a la ligne numéro 3. Peu importe la probabilité que cela se produise dans la pratique dans SQL Server; si je réexécute la requête, théoriquement, la ligne avec l’id 2 pourrait être attribuée avec le numéro de ligne 3 et la ligne avec l’id 11 pourrait être affectée avec le numéro de ligne 2.
Si vous devez attribuer des numéros de ligne en fonction dans un ordre complètement déterministe, garantissant des résultats reproductibles à travers les exécutions de la requête tant que les données sous-jacentes ne changent pas, vous avez besoin que la combinaison d’éléments dans les clauses de partitionnement et de classement de la fenêtre soit unique. Cela pourrait être réalisé dans notre cas en ajoutant l’ID de colonne à la clause d’ordre de la fenêtre en tant que bris d’égalité. La clause OVER serait alors:
OVER (PARTITION BY grp ORDER BY datacol, id)
Quoi qu’il en soit, lors du calcul des numéros de ligne sur la base d’une spécification de classement significative comme dans la requête 1, SQL Server doit traiter le rangées ordonnées par la combinaison d’éléments de partitionnement de fenêtre et de classement. Cela peut être réalisé soit en extrayant les données pré-ordonnées à partir d’un index, soit en triant les données. Pour le moment, il n’y a pas d’index sur T1 pour prendre en charge le calcul ROW_NUMBER dans la requête 1, SQL Server doit donc opter pour le tri des données. Cela peut être vu dans le plan pour la requête 1 illustré à la figure 1.
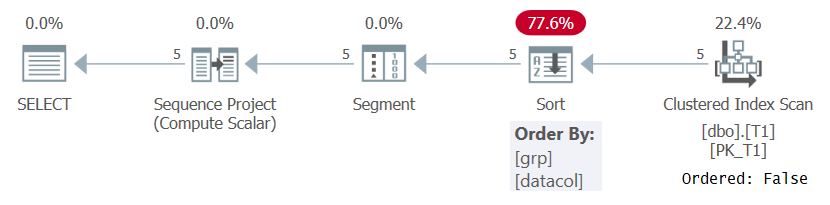 Figure 1: Plan pour la requête 1 sans index de prise en charge
Figure 1: Plan pour la requête 1 sans index de prise en charge
Notez que le plan analyse les données de l’index clusterisé avec une propriété Ordered: False. Cela signifie que l’analyse n’a pas besoin de renvoyer les lignes triées par la clé d’index. C’est le cas, car l’index clusterisé est utilisé ici simplement parce qu’il couvre la requête et non en raison de l’ordre de ses clés. Le plan applique ensuite un tri, ce qui entraîne un coût supplémentaire, une mise à l’échelle N Log N et un temps de réponse retardé. L’opérateur Segment produit un indicateur indiquant si la ligne est la première de la partition ou non. Enfin, l’opérateur de projet de séquence attribue des numéros de ligne commençant par 1 dans chaque partition.
Si vous voulez éviter d’avoir à trier, vous pouvez préparer un index de couverture avec une liste de clés basée sur les éléments de partitionnement et de classement, et une liste d’inclusion basée sur les éléments de couverture.J’aime considérer cet index comme un index POC (pour le partitionnement, l’ordre et la couverture). Voici la définition du POC qui prend en charge notre requête:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Relancez la requête 1:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Le plan de cette exécution est illustré à la Figure 2.
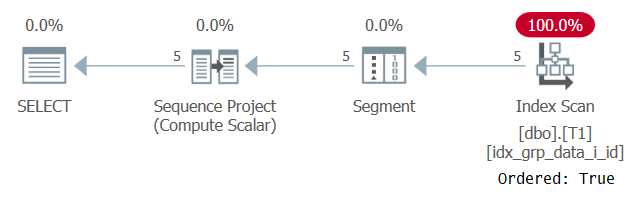 Figure 2: Plan pour la requête 1 avec un index POC
Figure 2: Plan pour la requête 1 avec un index POC
Observez que cette fois le plan analyse l’index POC avec une propriété Ordered: True. Cela signifie que l’analyse garantit que les lignes seront renvoyées dans l’ordre des clés d’index. Étant donné que les données sont extraites pré-ordonnées de l’index comme les besoins de la fonction de fenêtre, aucun tri explicite n’est nécessaire. La mise à l’échelle de ce plan est linéaire et le temps de réponse est bon.
Quand l’ordre n’a pas d’importance
Les choses deviennent un peu délicates lorsque vous devez attribuer des numéros de ligne avec un complètement non déterministe order. La chose naturelle à faire dans un tel cas est d’utiliser la fonction ROW_NUMBER sans spécifier de clause d’ordre de fenêtre. Commençons par vérifier si le standard SQL le permet. Voici la partie pertinente du standard définissant les règles de syntaxe pour window fonctions:
Notez que l’élément 6 répertorie les fonctions < ntile function >, < fonction d’avance ou de retard >, < type de fonction de rang > ou ROW_NUMBER, puis l’élément 6a dit que pour les fonctions < ntile function >, < fonction lead ou lag >, RANK ou DENSE_RANK la clause d’ordre de fenêtre doit b e présent. Il n’y a pas de langage explicite indiquant si ROW_NUMBER nécessite une clause d’ordre de fenêtre ou non, mais la mention de la fonction dans l’élément 6 et son omission dans 6a pourraient impliquer que la clause est facultative pour cette fonction. C’est assez évident pourquoi des fonctions telles que RANK et DENSE_RANK nécessiteraient une clause d’ordre de fenêtre, puisque ces fonctions se spécialisent dans la gestion des liens, et les liens n’existent que lorsqu’il y a une spécification de commande. Cependant, vous pouvez certainement voir comment la fonction ROW_NUMBER pourrait bénéficier d’une clause optionnelle d’ordre des fenêtres.
Alors, essayons et essayons de calculer les numéros de ligne sans ordre de fenêtre dans SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Cette tentative entraîne l’erreur suivante:
La fonction « ROW_NUMBER » doit avoir une clause OVER avec ORDER BY.
En effet, si vous consultez la documentation SQL Server de la fonction ROW_NUMBER, vous trouverez le texte suivant:
The ORDER La clause BY détermine la séquence dans laquelle les lignes reçoivent leur ROW_NUMBER unique dans une partition spécifiée. C’est obligatoire. »
Donc, apparemment, la clause d’ordre des fenêtres est obligatoire pour la fonction ROW_NUMBER dans SQL Server . C’est également le cas dans Oracle, d’ailleurs.
Je dois dire que je ne suis pas sûr de comprendre la raisoni ng derrière cette exigence. Rappelez-vous que vous autorisez la définition des numéros de ligne sur la base d’un ordre partiellement non déterministe, comme dans la requête 1. Alors pourquoi ne pas autoriser le non-déterminisme complètement? Il y a peut-être une raison à laquelle je ne pense pas. Si vous pensez à une telle raison, merci de partager.
Quoi qu’il en soit, vous pourriez faire valoir que si vous ne vous souciez pas de l’ordre, étant donné que la clause d’ordre des fenêtres est obligatoire, vous pouvez spécifier n’importe quel ordre. Le problème avec cette approche est que si vous commandez selon une colonne de la ou des tables interrogées, cela peut entraîner une pénalité de performances inutile. Lorsqu’aucun index de prise en charge n’est en place, vous payez pour un tri explicite. Lorsqu’un index de prise en charge est en place, vous limitez le moteur de stockage à une stratégie d’analyse de l’ordre d’index (après la liste liée des index). Vous ne lui permettez pas plus de flexibilité comme il le fait habituellement lorsque l’ordre n’a pas d’importance dans le choix entre un scan de l’ordre d’index et un scan de l’ordre d’allocation (basé sur des pages IAM).
Une idée qui vaut la peine d’être essayée consiste à spécifier une constante, comme 1, dans la clause d’ordre des fenêtres. S’il est pris en charge, vous espérez que l’optimiseur est suffisamment intelligent pour se rendre compte que toutes les lignes ont la même valeur, il n’y a donc pas de réelle pertinence de classement et donc pas besoin de forcer un tri ou une analyse de l’ordre d’index. Voici une requête tentant cette approche:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Malheureusement, SQL Server ne prend pas en charge cette solution. Il génère l’erreur suivante:
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les indices entiers comme expressions de clause ORDER BY.
Apparemment, SQL Server suppose que si vous utilisez une constante entière dans la clause d’ordre de fenêtre, cela représente une position ordinale d’un élément dans la liste SELECT, comme lorsque vous spécifiez un entier dans la présentation ORDER Clause BY. Si tel est le cas, une autre option qui vaut la peine d’essayer est de spécifier une constante non entière, comme ceci:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Il s’avère que cette solution n’est pas non plus prise en charge. SQL Server génère l’erreur suivante:
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les constantes en tant qu’expressions de clause ORDER BY.
Apparemment, la clause d’ordre des fenêtres ne prend en charge aucun type de constante.
Jusqu’à présent, nous avons appris ce qui suit sur la pertinence de l’ordre des fenêtres de la fonction ROW_NUMBER dans SQL Server:
- ORDER BY est obligatoire.
- Impossible de trier par constante entière car SQL Server pense que vous «essayez de spécifier une position ordinale dans SELECT.
- Impossible de trier par toute sorte de constante.
La conclusion est que vous êtes censé trier par expressions qui ne sont pas des constantes. Évidemment, vous pouvez classer par une liste de colonnes à partir de la ou des tables interrogées. Mais nous sommes à la recherche d’une solution efficace où l’optimiseur peut se rendre compte qu’il n’y a pas de pertinence de commande.
Pliage constant
La conclusion jusqu’à présent est que vous ne pouvez pas utiliser de constantes dans le Clause d’ordre des fenêtres de ROW_NUMBER, mais qu’en est-il des expressions basées sur des constantes, comme dans la requête suivante:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Cependant, cette tentative est victime d’un processus dit constant pliage, qui a normalement un impact positif sur les performances des requêtes. L’idée derrière cette technique est d’améliorer les performances des requêtes en repliant une expression basée sur des constantes à leurs constantes de résultat à un stade précoce du traitement de la requête. Vous pouvez trouver des détails sur les types d’expressions qui peuvent être constamment pliés ici. Notre expression 1 + 0 est pliée à 1, ce qui entraîne la même erreur que celle que vous avez obtenue en spécifiant directement la constante 1:
Fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les index entiers comme expressions de clause ORDER BY.
Vous seriez confronté à une situation similaire en essayant de concaténer deux chaînes de caractères littérales, comme ceci:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Vous obtenez la même erreur que celle que vous avez obtenue en spécifiant directement le littéral « Pas de commande »:
fenêtré les fonctions, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les constantes comme expressions de clause ORDER BY.
Bizarro world – des erreurs qui évitent les erreurs
La vie est pleine de surprises…
Une chose qui empêche le repli constant est lorsque l’expression entraînerait normalement une erreur. Par exemple, l’expression 2147483646 + 1 peut être repliée de manière constante car elle aboutit à une valeur de type INT valide. Par conséquent, une tentative d’exécution de la requête suivante échoue:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Fonctions fenêtrées, agrégats et VALEUR SUIVANTE Les fonctions FOR ne prennent pas en charge les index entiers comme expressions de clause ORDER BY.
Cependant, l’expression 2147483647 + 1 ne peut pas être repliée de façon constante car une telle tentative aurait entraîné une erreur de dépassement INT. L’implication sur la commande est assez intéressante. Essayez la requête suivante (nous appellerons cette requête 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Curieusement, cette requête s’exécute avec succès! Ce qui se passe, c’est que d’une part, SQL Server ne parvient pas à appliquer le repliement constant et, par conséquent, l’ordre est basé sur une expression qui n’est pas une seule constante. D’un autre côté, l’optimiseur estime que la valeur de classement est la même pour toutes les lignes, donc il ignore complètement l’expression de classement. Ceci est confirmé lors de l’examen du plan de cette requête comme illustré à la figure 3.
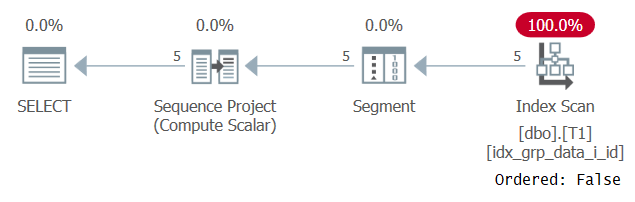 Figure 3: Plan pour la requête 2
Figure 3: Plan pour la requête 2
Observer que le plan analyse certains index de couverture avec une propriété Ordered: False. C’était exactement notre objectif de performances.
De la même manière, la requête suivante implique une tentative de repli constant réussie et échoue donc:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les indices entiers comme expressions de clause ORDER BY.
La requête suivante implique une tentative de repli constant échouée, et réussit donc, générant le plan montré plus haut dans la figure 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Ce qui suit La requête implique une tentative de repli constant réussie (le littéral VARCHAR « 1 » est implicitement converti en INT 1, puis 1 + 1 est plié en 2), et échoue donc:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les index entiers comme expressions de clause ORDER BY.
La requête suivante implique un échec de la tentative de pliage de constante (impossible de convertir « A » en INT), et donc réussit, générant le plan indiqué précédemment dans la figure 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Pour être honnête, même si cette technique bizarro atteint notre objectif de performance initial, je ne peux pas dire que je la considère comme sûre et par conséquent je ne suis pas très à l’aise de m’y fier.
Constantes d’exécution basées sur des fonctions
Poursuivant la recherche d’une bonne solution pour calculer les nombres de lignes avec un ordre non déterministe, il existe quelques techniques qui semblent plus sûres que la dernière solution décalée: utiliser des constantes d’exécution basées sur des fonctions, utiliser une sous-requête basée sur une constante, utiliser un colonne aliasée basée sur une constante et utilisant une variable.
Comme je l’explique dans les bogues, les pièges et les meilleures pratiques T-SQL – le déterminisme, la plupart des fonctions de T-SQL ne sont évaluées qu’une seule fois par référence dans la requête – pas une fois par ligne. C’est le cas même avec la plupart des fonctions non déterministes comme GETDATE et RAND. Il y a très peu d’exceptions à cette règle, comme les fonctions NEWID et CRYPT_GEN_RANDOM, qui sont évaluées une fois par ligne. La plupart des fonctions, telles que GETDATE, @@ SPID et bien d’autres, sont évaluées une fois au début de la requête et leurs valeurs sont alors considérées comme des constantes d’exécution. Une référence à de telles fonctions ne se replie pas constamment. Ces caractéristiques font d’une constante d’exécution basée sur une fonction un bon choix en tant qu’élément de classement des fenêtres, et en effet, il semble que T-SQL la supporte. En même temps, l’optimiseur se rend compte qu’en pratique, il n’y a pas de pertinence de commande, évitant ainsi des pénalités de performances inutiles.
Voici un exemple utilisant la fonction GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Cette requête obtient le même plan que celui indiqué précédemment dans la figure 3.
Voici un autre exemple utilisant la fonction @@ SPID (renvoyant l’ID de session en cours):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
Et la fonction PI? Essayez la requête suivante:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Celui-ci échoue avec l’erreur suivante:
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les constantes en tant qu’expressions de clause ORDER BY.
Les fonctions comme GETDATE et @@ SPID sont réévaluées une fois par exécution du plan, elles ne peuvent donc pas obtenir constante pliée. PI représente toujours la même constante, et est donc toujours pliée.
Comme mentionné précédemment, très peu de fonctions sont évaluées une fois par ligne, telles que NEWID et CRYPT_GEN_RANDOM. Cela en fait un mauvais choix comme élément de classement des fenêtres si vous avez besoin d’un ordre non déterministe – à ne pas confondre avec un ordre aléatoire. Pourquoi payer une pénalité de tri inutile?
Voici un exemple utilisant la fonction NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Le plan de cette requête est illustré à la figure 4, confirmant que SQL Server a ajouté explicitement tri basé sur le résultat de la fonction.
 Figure 4: Planifiez la requête 3
Figure 4: Planifiez la requête 3
Si vous voulez que les numéros de ligne soient attribués dans un ordre aléatoire, c’est certainement la technique que vous souhaitez utiliser. Vous devez juste être conscient que cela entraîne le coût du tri.
Utilisation d’une sous-requête
Vous pouvez également utiliser une sous-requête basée sur une constante comme expression de classement des fenêtres (par exemple, ORDER BY (SÉLECTIONNEZ « Pas de commande »)). De plus, avec cette solution, l’optimiseur de SQL Server reconnaît qu’il n’ya pas de pertinence de l’ordre et n’impose donc pas de tri inutile ni ne limite les choix du moteur de stockage à ceux qui doivent garantir l’ordre. Essayez d’exécuter la requête suivante comme exemple:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Vous obtenez le même plan illustré précédemment dans la figure 3.
L’un des grands avantages de cette technique est que vous pouvez ajouter votre propre touche personnelle.Peut-être que vous aimez vraiment les NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Peut-être que vous aimez vraiment un certain nombre:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Vous souhaitez peut-être envoyer un message à quelqu’un:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Vous obtenez le point.
Faisable, mais maladroit
Il y a quelques techniques qui fonctionnent, mais qui sont un peu gênantes. La première consiste à définir un alias de colonne pour une expression basée sur une constante, puis à utiliser cet alias de colonne comme élément de classement des fenêtres. Vous pouvez le faire en utilisant une expression de table ou avec l’opérateur CROSS APPLY et un constructeur de valeur de table. Voici un exemple pour ce dernier:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Vous obtenez le même plan illustré précédemment dans la figure 3.
Une autre option consiste à utiliser une variable comme élément de classement des fenêtres:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Cette requête obtient également le plan montré précédemment dans la figure 3.
Et si j’utilise mon propre UDF ?
Vous pourriez penser que l’utilisation de votre propre UDF qui renvoie une constante pourrait être un bon choix comme élément de classement des fenêtres lorsque vous voulez un ordre non déterministe, mais ce n’est pas le cas. Prenons l’exemple de la définition UDF suivante:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Essayez d’utiliser l’UDF comme clause de classement des fenêtres, comme ceci (nous appellerons cette requête 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Avant SQL Server 2019 (ou niveau de compatibilité parallèle < 150), les fonctions définies par l’utilisateur sont évaluées par ligne . Même s’ils renvoient une constante, ils ne sont pas intégrés. Par conséquent, d’une part, vous pouvez utiliser un tel UDF comme élément de classement des fenêtres, mais d’autre part, cela entraîne une pénalité de tri. Ceci est confirmé en examinant le plan de cette requête, comme indiqué dans la figure 5.
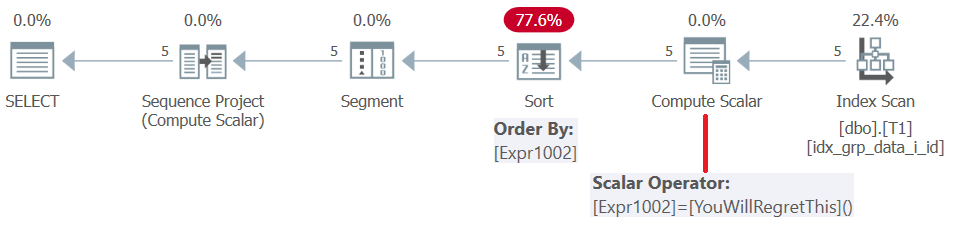 Figure 5: Plan pour la requête 4
Figure 5: Plan pour la requête 4
À partir de SQL Server 2019, sous le niveau de compatibilité > = 150, ces fonctions définies par l’utilisateur sont incorporées, ce qui est généralement une bonne chose, mais dans notre cas entraîne une erreur:
Les fonctions fenêtrées, les agrégats et les fonctions NEXT VALUE FOR ne prennent pas en charge les constantes comme expressions de clause ORDER BY.
Donc, en utilisant un UDF basé sur une constante en tant qu’élément de classement des fenêtres force un tri ou une erreur selon la version de SQL Server que vous utilisez et le niveau de compatibilité de votre base de données. En bref, ne le faites pas.
Numéros de ligne partitionnés avec un ordre non déterministe
Un cas d’utilisation courant pour les numéros de ligne partitionnés basés sur un ordre non déterministe est de renvoyer n’importe quelle ligne par groupe. Étant donné que, par définition, un élément de partitionnement existe dans ce scénario, vous penseriez qu’une technique sûre dans un tel cas serait d’utiliser l’élément de partitionnement de fenêtre également comme élément de classement de fenêtre. Dans un premier temps, vous calculez les numéros de ligne comme suit:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Le plan de cette requête est illustré à la Figure 6.
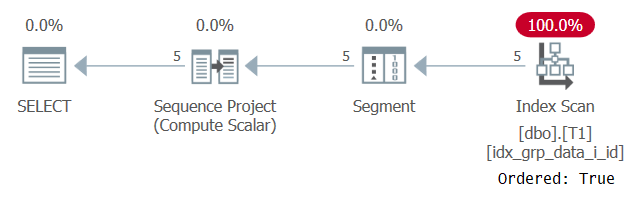 Figure 6: Planification de la requête 5
Figure 6: Planification de la requête 5
La raison pour laquelle notre index de prise en charge est analysé avec une propriété Ordered: True est que SQL Server doit traiter les lignes de chaque partition comme un unité unique. C’est le cas avant le filtrage. Si vous filtrez une seule ligne par partition, vous disposez d’algorithmes à la fois basés sur l’ordre et basés sur le hachage comme options.
La deuxième étape consiste à placer la requête avec le calcul du numéro de ligne dans une expression de table, et dans la requête externe filtre la ligne avec le numéro de ligne 1 dans chaque partition, comme ceci:
Théoriquement, cette technique est censée être sûre, mais Paul White a trouvé un bogue qui montre qu’en utilisant cette méthode, vous pouvez obtenir des attributs à partir de différentes lignes source dans la ligne de résultat renvoyée par partition. L’utilisation d’une constante d’exécution basée sur une fonction ou une sous-requête basée sur une constante comme élément de classement semble être sûre même avec ce scénario, alors assurez-vous d’utiliser une solution telle que la suivante à la place:
Personne doit passer de cette façon sans ma permission
Essayer de calculer les numéros de ligne en fonction d’un ordre non déterministe est un besoin courant. Cela aurait été bien si T-SQL avait simplement rendu la clause d’ordre des fenêtres facultative pour la fonction ROW_NUMBER, mais ce n’est pas le cas. Sinon, cela aurait été bien si cela permettait au moins d’utiliser une constante comme élément de classement, mais ce n’est pas non plus une option prise en charge.Mais si vous demandez gentiment, sous la forme d’une sous-requête basée sur une constante ou une constante d’exécution basée sur une fonction, SQL Server le permettra. Ce sont les deux options avec lesquelles je suis le plus à l’aise. Je ne me sens pas vraiment à l’aise avec les expressions erronées bizarres qui semblent fonctionner, je ne peux donc pas recommander cette option.