Un robots Le fichier .txt contient des directives pour les moteurs de recherche. Vous pouvez l’utiliser pour empêcher les moteurs de recherche d’explorer des parties spécifiques de votre site Web et pour donner aux moteurs de recherche des conseils utiles sur la meilleure façon d’explorer votre site Web. Le fichier robots.txt joue un rôle important dans le référencement.
Lors de la mise en œuvre de robots.txt, gardez à l’esprit les bonnes pratiques suivantes:
- Soyez prudent lorsque vous apportez des modifications à votre robots.txt: ce fichier a le potentiel de rendre de grandes parties de votre site Web inaccessibles aux moteurs de recherche.
- Le fichier robots.txt doit résider à la racine de votre site Web (par exemple,
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpouhttps). - Différents moteurs de recherche interprètent les directives différemment. Par défaut, la première directive correspondante l’emporte toujours. Mais, avec Google et Bing, la spécificité l’emporte.
- Évitez autant que possible d’utiliser la directive crawl-delay pour les moteurs de recherche.
Qu’est-ce qu’un Fichier robots.txt?
Un fichier robots.txt indique aux moteurs de recherche quelles sont les règles d’engagement de votre site Web. Une grande partie du référencement consiste à envoyer les bons signaux aux moteurs de recherche, et le fichier robots.txt est l’un des moyens de communiquer vos préférences d’exploration aux moteurs de recherche.
En 2019, nous avons vu pas mal quelques développements autour de la norme robots.txt: Google a proposé une extension au protocole d’exclusion des robots et a ouvert son analyseur robots.txt.
TL; DR
- les robots de Google L’interpréteur .txt est assez flexible et étonnamment indulgent.
- En cas de directives confuses, Google se trompe du bon côté et suppose que les sections doivent être restreintes plutôt que illimitées.
Les moteurs de recherche vérifient régulièrement le fichier robots.txt d’un site Web pour voir s’il existe des instructions pour l’exploration du site Web. Nous appelons ces instructions directives.
S’il n’y a pas de fichier robots.txt ou s’il n’y a pas de directives applicables, les moteurs de recherche exploreront l’ensemble du site Web.
Bien que tous les principaux moteurs de recherche respectent le fichier robots.txt, les moteurs de recherche peuvent choisir d’ignorer (des parties de) votre fichier robots.txt. Bien que les directives du fichier robots.txt soient un signal fort pour les moteurs de recherche, il est important de se rappeler que le fichier robots.txt est un ensemble de directives facultatives destinées aux moteurs de recherche plutôt qu’un mandat.

Le fichier robots.txt est le fichier le plus sensible de l’univers SEO. Un seul caractère peut casser tout un site.
Terminologie autour du fichier robots.txt
Le fichier robots.txt est l’implémentation du standard d’exclusion des robots, ou aussi appelé le protocole d’exclusion des robots.
Pourquoi devriez-vous vous soucier du fichier robots.txt?
Le fichier robots.txt joue un rôle essentiel d’un point de vue SEO. Il indique aux moteurs de recherche comment explorer au mieux votre site Web.
En utilisant le fichier robots.txt, vous pouvez empêcher les moteurs de recherche d’accéder à certaines parties de votre site Web, éviter le contenu en double et donner aux moteurs de recherche des conseils utiles sur la façon dont ils peut explorer votre site Web plus efficacement.
Soyez prudent lorsque vous apportez des modifications à votre fichier robots.txt: ce fichier a le potentiel de rendre de grandes parties de votre site Web inaccessibles aux moteurs de recherche.

Robots.txt est souvent surutilisé pour réduire le contenu en double, de ce fait tuer les liens internes alors soyez vraiment prudent avec cela. Mon conseil est de ne l’utiliser que pour des fichiers ou des pages que les moteurs de recherche ne devraient jamais voir ou qui peuvent avoir un impact significatif sur l’exploration en étant autorisés à y accéder. Exemples courants: zones de connexion qui génèrent de nombreuses URL différentes, zones de test ou dans lesquelles une navigation à facettes multiples peut exister. Et assurez-vous de surveiller votre fichier robots.txt pour tout problème ou modification.

La grande majorité des problèmes que je constate avec les fichiers robots.txt se répartissent en trois catégories:
- La mauvaise gestion des caractères génériques. Il est assez courant de voir des parties du site bloquées qui étaient censées être bloquées. Parfois, si vous ne faites pas attention, les directives peuvent également entrer en conflit les unes avec les autres.
- Quelqu’un, comme un développeur, a effectué un changement à l’improviste (souvent en poussant un nouveau code) et l’a modifié par inadvertance le robots.txt à votre insu.
- L’inclusion de directives qui n’appartiennent pas à un fichier robots.txt. Robots.txt est un standard Web et est quelque peu limité. Je vois souvent des développeurs élaborer des directives qui ne fonctionneront tout simplement pas (du moins pour la grande majorité des robots d’exploration). Parfois c’est inoffensif, parfois moins.
Exemple
Prenons un exemple pour illustrer ceci:
Vous exécutez un site Web de commerce électronique et les visiteurs peuvent utiliser un filtre pour rechercher rapidement dans vos produits. Ce filtre génère des pages qui affichent essentiellement le même contenu que les autres pages. Cela fonctionne très bien pour les utilisateurs, mais embrouille les moteurs de recherche car cela crée du contenu en double.
Vous ne voulez pas que les moteurs de recherche indexent ces pages filtrées et perdent leur temps précieux sur ces URL avec du contenu filtré. Pour cela, vous devez configurer des règles Disallow afin que les moteurs de recherche n’accèdent pas à ces pages de produits filtrées.
La prévention du contenu en double peut également être effectuée à l’aide de l’URL canonique ou la balise meta robots, mais cela ne concerne pas le fait de permettre aux moteurs de recherche d’explorer uniquement les pages qui comptent.
L’utilisation d’une URL canonique ou d’une balise meta robots n’empêchera pas les moteurs de recherche d’explorer ces pages. Cela empêchera uniquement les moteurs de recherche d’afficher ces pages dans les résultats de recherche. Étant donné que les moteurs de recherche ont peu de temps pour explorer un site Web, ce temps doit être consacré aux pages que vous souhaitez afficher dans les moteurs de recherche.
Un fichier robots.txt mal configuré peut nuire à vos performances de référencement. Vérifiez tout de suite si c’est le cas pour votre site Web!

C’est un outil très simple, mais un fichier robots.txt peut causer beaucoup de problèmes s’il n’est pas configuré correctement, en particulier pour les grands sites Web. Il est très facile de faire des erreurs telles que le blocage d’un site entier après le déploiement d’une nouvelle conception ou d’un nouveau CMS, ou de ne pas bloquer des sections d’un site qui devraient être privées. Pour les sites Web plus volumineux, il est très important de garantir une exploration efficace de Google et un fichier robots.txt bien structuré est un outil essentiel dans ce processus.
Vous devez prendre le temps de comprendre quelles sections de votre site sont les mieux tenues à l’écart de Google afin qu’ils dépensent autant de leurs ressources que possible pour explorer les pages qui vous intéressent vraiment.
À quoi ressemble un fichier robots.txt?
Un exemple de ce à quoi un simple fichier robots.txt pour un site Web WordPress peut ressembler à:
Expliquons l’anatomie d’un fichier robots.txt à partir de l’exemple ci-dessus:
- User-agent: le
user-agentindique pour quelle recherche moteurs les directives qui suivent sont signifiées. -
*: cela indique que les directives sont destinées à tous les moteurs de recherche. -
Disallow: il s’agit d’une directive indiquant quel contenu n’est pas accessible auuser-agent. -
/wp-admin/: c’est lepathqui est inaccessible pour leuser-agent.
En résumé: ce fichier robots.txt indique à tous les moteurs de recherche de rester en dehors du répertoire /wp-admin/.
Analysons les différents composants des fichiers robots.txt plus en détail:
- User-agent
- Interdire
- Autoriser
- Plan du site
- Délai d’exploration
User-agent dans le fichier robots.txt
Chaque moteur de recherche doit s’identifier avec un user-agent. Les robots de Google s’identifient comme Googlebot, par exemple, les robots de Yahoo comme Slurp et le robot de Bing comme BingBot et ainsi de suite.
L’enregistrement user-agent définit le début d’un groupe de directives. Toutes les directives entre le premier user-agent et le prochain user-agent enregistrement sont traitées comme des directives pour le premier user-agent.
Les directives peuvent s’appliquer à des agents utilisateurs spécifiques, mais elles peuvent également s’appliquer à tous les agents utilisateurs. Dans ce cas, un caractère générique est utilisé: User-agent: *.
Interdire la directive dans le fichier robots.txt
Vous pouvez dire aux moteurs de recherche de ne pas accéder certains fichiers, pages ou sections de votre site Web. Cela se fait à l’aide de la directive Disallow. La directive Disallow est suivie de la path qui ne doit pas être accédée. Si aucun path n’est défini, la directive est ignorée.
Exemple
Dans cet exemple, tous les moteurs de recherche sont invités à ne pas accéder au répertoire /wp-admin/.
Directive Allow dans le fichier robots.txt
La directive Allow est utilisée pour contrer une directive Disallow. La directive Allow est prise en charge par Google et Bing. En utilisant les directives Allow et Disallow, vous pouvez indiquer aux moteurs de recherche qu’ils peuvent accéder à un fichier ou une page spécifique dans un répertoire qui est autrement interdit. La directive Allow est suivie de la path accessible. Si aucun path n’est défini, la directive est ignorée.
Exemple
Dans l’exemple ci-dessus, tous les moteurs de recherche ne sont pas autorisés à accéder au /media/, sauf pour le fichier /media/terms-and-conditions.pdf.
Important: lors de l’utilisation de Allow et Disallow ensemble, assurez-vous de ne pas utiliser de caractères génériques car cela peut conduire à des directives conflictuelles.
Exemple de directives conflictuelles
Les moteurs de recherche ne sauront pas quoi faire avec l’URL . Ils ne savent pas s’ils sont autorisés à y accéder. Lorsque les directives ne sont pas claires pour Google, ils utiliseront la directive la moins restrictive, ce qui signifie dans ce cas qu’ils accèderont en fait à
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt est l’une des fonctionnalités que je vois le plus souvent mal implémentées, donc il ne bloque pas ce qu’ils voulaient bloquer ou il bloque plus que prévu et a un impact négatif sur leur site Web. Robots.txt est un outil très puissant mais trop souvent mal configuré.
Utilisation du caractère générique *
Non seulement le caractère générique peut être utilisé pour définir le user-agent, mais il peut également être utilisé pour correspondent aux URL. Le caractère générique est pris en charge par Google, Bing, Yahoo et Ask.
Exemple
Dans l’exemple ci-dessus, tous les moteurs de recherche ne sont pas autorisés à accéder aux URL contenant un point d’interrogation (?).

Développeurs ou les propriétaires de sites semblent souvent penser qu’ils peuvent utiliser toutes sortes d’expressions régulières dans un fichier robots.txt alors que seule une quantité très limitée de correspondance de modèle est réellement valide – par exemple des caractères génériques (
*). Il semble y avoir une confusion entre les fichiers .htaccess et les fichiers robots.txt de temps en temps.
Utilisation de la fin de l’URL $
Pour indiquer la fin d’une URL, vous pouvez utiliser le signe dollar ($) à la fin de path.
Exemple
Dans l’exemple ci-dessus, les moteurs de recherche ne sont pas autorisés à accéder à toutes les URL qui se terminent par .php . URL avec des paramètres, par exemple ne serait pas interdit, car l’URL ne se termine pas après .php.
Ajoutez un plan du site aux robots. txt
Même si le fichier robots.txt a été inventé pour indiquer aux moteurs de recherche quelles pages ne pas explorer, le fichier robots.txt peut également être utilisé pour diriger les moteurs de recherche vers le plan de site XML. Ceci est pris en charge par Google, Bing, Yahoo et Ask.
Le sitemap XML doit être référencé comme une URL absolue. L’URL n’a pas besoin d’être sur le même hôte que le fichier robots.txt.
Le référencement du plan de site XML dans le fichier robots.txt est l’une des meilleures pratiques que nous vous conseillons de toujours faire, même si vous avez peut-être déjà envoyé votre plan de site XML dans Google Search Console ou dans Bing Webmaster Tools. N’oubliez pas qu’il existe d’autres moteurs de recherche.
Veuillez noter qu’il est possible de référencer plusieurs sitemaps XML dans un fichier robots.txt.
Exemples
Plusieurs Sitemaps XML définis dans un fichier robots.txt:
Un seul plan de site XML défini dans un fichier robots.txt fichier:
L’exemple ci-dessus indique à tous les moteurs de recherche de ne pas accéder au répertoire /wp-admin/ et que le plan du site XML se trouve à
Comments are preceded by a # et peut soit être placé au début d’une ligne ou après une directive sur la même ligne. Tout ce qui suit # sera ignoré. Ces commentaires sont destinés uniquement aux humains.
Exemple 1
Exemple 2
Les exemples ci-dessus communiquent le même message.
Délai d’exploration dans le fichier robots.txt
Le Crawl-delay est une directive non officielle utilisée pour éviter de surcharger les serveurs avec trop de requêtes. Si les moteurs de recherche sont capables de surcharger un serveur, l’ajout de Crawl-delay à votre fichier robots.txt n’est qu’une solution temporaire. Le fait est que votre site Web fonctionne dans un environnement d’hébergement médiocre et / ou que votre site Web est mal configuré, et vous devez résoudre ce problème dès que possible.
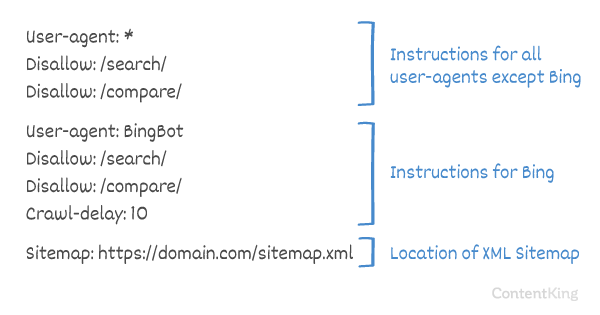
La manière dont les moteurs de recherche gèrent les Crawl-delay diffère. Nous expliquons ci-dessous comment les principaux moteurs de recherche le gèrent.
Délai d’exploration et Google
Le robot d’exploration de Google, Googlebot, ne prend pas en charge le Crawl-delay, alors ne vous souciez pas de définir un délai d’exploration Google.
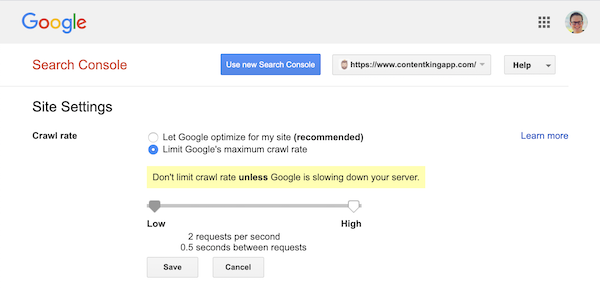
Cependant, Google prend en charge la définition d’un taux d’exploration (ou « taux de demande » si vous voulez ) dans Google Search Console.
- Connectez-vous à l’ancienne Google Search Console.
- Choisissez le site Web que vous souhaitez définir la vitesse d’exploration.
- Vous ne pouvez modifier qu’un seul paramètre:
Crawl rate, avec un curseur dans lequel vous pouvez définir la vitesse d’exploration préférée. Par défaut la vitesse d’exploration est définie sur « Laisser Google optimiser pour mon site (recommandé) ».
Voici à quoi cela ressemble dans Google Search Console:
Délai d’exploration et Bing, Yahoo et Yandex
Bing, Yahoo et Yandex tous supportent le Crawl-delay directive pour limiter l’exploration d’un site Web. Leur interprétation du délai de crawl est cependant légèrement différente, alors assurez-vous de vérifier leur documentation:
- Bing et Yahoo
- Yandex
La directive Crawl-delay doit être placée juste après les directives Disallow ou Allow.
Exemple:
Délai d’exploration et Baidu
Baidu ne prend pas en charge la directive crawl-delay, mais il est possible d’enregistrer un compte Baidu Webmaster Tools dans dont vous pouvez contrôler la fréquence d’exploration, similaire à Google Search Console.
Quand utiliser un fichier robots.txt?
Nous vous recommandons de toujours utiliser un fichier robots.txt. Il n’y a absolument aucun mal à en avoir un, et c’est un excellent endroit pour transmettre les directives des moteurs de recherche sur la meilleure façon d’explorer votre site Web.

Le fichier robots.txt peut être utile pour empêcher l’exploration et l’indexation de certaines zones ou documents de votre site. Des exemples sont par exemple le site de préparation ou les PDF. Planifiez soigneusement ce qui doit être indexé par les moteurs de recherche et gardez à l’esprit que le contenu rendu inaccessible via le fichier robots.txt peut toujours être trouvé par les robots des moteurs de recherche s’il est lié à d’autres zones du site Web.
Meilleures pratiques Robots.txt
Les bonnes pratiques du fichier robots.txt sont classées comme suit:
- Emplacement et nom de fichier
- Ordre de priorité
- Un seul groupe de directives par robot
- Soyez aussi précis que possible
- Directives pour tous les robots tout en incluant également des directives pour un robot spécifique
- Fichier Robots.txt pour chaque (sous) domaine.
- Directives contradictoires: robots.txt et Google Search Console
- Surveillez votre fichier robots.txt
- N’utilisez pas noindex dans votre robots.txt
- Empêcher la nomenclature UTF-8 dans le fichier robots.txt
Emplacement et nom de fichier
Le fichier robots.txt doit toujours être placé dans e e root d’un site Web (dans le répertoire de niveau supérieur de l’hôte) et porter le nom de fichier robots.txt, par exemple: . Notez que l’URL du fichier robots.txt est, comme toute autre URL, sensible à la casse.
Si le fichier robots.txt est introuvable dans l’emplacement par défaut, les moteurs de recherche supposeront qu’il n’y a pas de directives et ramperont sur votre site Web.
Ordre de priorité
Il est important de noter que les moteurs de recherche traitent les fichiers robots.txt différemment. Par défaut, la première directive correspondante l’emporte toujours.
Cependant, la spécificité de Google et Bing l’emporte. Par exemple: une directive Allow l’emporte sur une directive Disallow si sa longueur de caractères est plus longue.
Exemple
Dans le exemple ci-dessus, tous les moteurs de recherche, y compris Google et Bing, ne sont pas autorisés à accéder au répertoire /about/, à l’exception du sous-répertoire /about/company/.
Exemple
Dans l’exemple ci-dessus, tous les moteurs de recherche, à l’exception de Google et Bing, ne sont pas autorisés à accéder au répertoire /about/. Cela inclut le répertoire /about/company/.
Google et Bing sont autorisés à accéder, car la directive Allow est plus longue que la Disallow directive.
Un seul groupe de directives par robot
Vous ne pouvez définir qu’un groupe de directives par moteur de recherche. Avoir plusieurs groupes de directives pour un moteur de recherche les confond.
Soyez aussi précis que possible
La directive Disallow se déclenche sur des correspondances partielles comme bien. Soyez aussi précis que possible lors de la définition de la directive Disallow pour éviter de refuser involontairement l’accès aux fichiers.
Exemple:
L’exemple ci-dessus ne permet pas aux moteurs de recherche d’accéder à:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Directives pour tous les robots tout en incluant également des directives pour un robot spécifique
Pour un robot un seul groupe de directives est valide. Dans le cas où des directives destinées à tous les robots sont suivies avec des directives pour un robot spécifique, seules ces directives spécifiques seront prises en compte. Pour que le robot spécifique suive également les directives pour tous les robots, vous devez répéter ces directives pour le robot spécifique.
Regardons un exemple qui rendra cela clair:
Exemple
Si vous ne souhaitez pas que googlebot accède à /secret/ et /not-launched-yet/, vous devez répéter ces directives pour googlebot en particulier:
Veuillez noter que votre fichier robots.txt est accessible au public. Interdire les sections de sites Web qui s’y trouvent peut être utilisé comme vecteur d’attaque par des personnes malveillantes.

Les robots.txt peuvent être dangereux. Vous ne dites pas seulement aux moteurs de recherche où vous ne voulez pas qu’ils regardent, vous dites aux gens où vous cachez vos sales secrets.
Fichier Robots.txt pour chaque (sous) domaine
Directives Robots.txt uniquement s’appliquent au (sous) domaine sur lequel le fichier est hébergé.
Exemples
est valide pour , mais pas pour ou
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / C’est pour cette raison que nous avons créé le suivi et l’alerte des modifications du fichier robots.txt.
On le voit tout le temps: les fichiers robots.txt changent sans connaissance du marketing digital équipe. Ne sois pas cette personne. Commencez à surveiller votre fichier robots.txt et recevez maintenant des alertes lorsqu’il change!
N’utilisez pas noindex dans votre fichier robots.txt
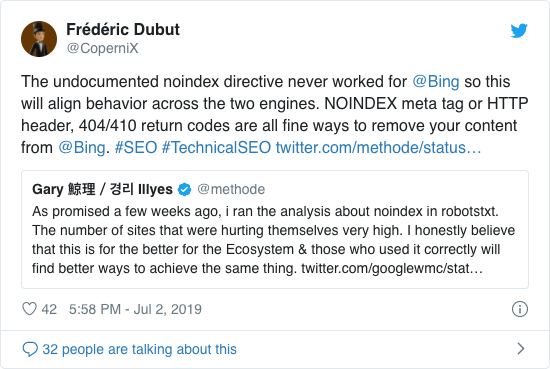
Pendant des années, Google recommandait déjà ouvertement de ne pas utiliser la directive non officielle noindex. Cependant, depuis le 1er septembre 2019, Google a cessé de le supporter entièrement.
La directive non officielle noindex n’a jamais fonctionné dans Bing, comme le confirme Frédéric Dubut dans ce tweet:
La meilleure façon de signaler aux moteurs de recherche que les pages ne doivent pas être indexées est d’utiliser la balise meta robots ou X-Robots-Tag .
Empêcher la nomenclature UTF-8 dans le fichier robots.txt
La nomenclature représente la marque d’ordre des octets, un caractère invisible au début d’un fichier utilisé pour indiquer le codage Unicode d’un fichier texte.
Bien que Google déclare ignorer la marque facultative d’ordre des octets Unicode au début du fichier robots.txt, nous vous recommandons d’éviter la « nomenclature UTF-8 », car nous l’avons vu causer des problèmes avec l’interprétation de le fichier robots.txt par les moteurs de recherche.
Même si Google dit qu’ils peuvent le gérer, voici deux raisons pour empêcher la nomenclature UTF-8:
- Vous ne Je ne veux pas qu’il y ait d’ambiguïté quant à vos préférences concernant l’exploration vers les moteurs de recherche.
- Il existe d’autres moteurs de recherche, qui peuvent ne pas être aussi indulgents que Google prétend l’être.
Exemples de robots.txt
Dans ce chapitre, nous allons couvrir un large éventail d’exemples de fichiers robots.txt:
- Autoriser tous les robots à accéder à tout
- Interdire à tous les robots d’accéder à tout
- Tous les robots Google n’y ont pas accès
- Tous les robots Google, à l’exception des actualités Googlebot, n’y ont pas accès
- Googlebot et Slurp n’ont aucun accès
- Tous les robots n’ont pas accès à deux répertoires
- Tous les robots n’ont pas accès à un fichier spécifique
- Googlebot n’a pas accès à / admin / et Slurp n’a pas accès à / private /
- Fichier Robots.txt pour WordPress
- Fichier Robots.txt pour Magento
Autoriser tous les robots à accéder à tout
Il y a plusieurs façons pour indiquer aux moteurs de recherche qu’ils peuvent accéder à tous les fichiers:
Ou avoir un fichier robots.txt vide ou ne pas avoir du tout un fichier robots.txt.
Interdire à tous les robots d’accéder à tout
L’exemple Le fichier robots.txt ci-dessous indique à tous les moteurs de recherche de ne pas accéder à l’ensemble du site:
Veuillez noter qu’un seul caractère supplémentaire peut faire toute la différence.
Tous les robots Google n’y ont pas accès
Veuillez noter que lorsque vous désactivez Googlebot, cela vaut pour tous les Googlebots. Cela inclut les robots Google qui recherchent par exemple des actualités (googlebot-news) et des images (googlebot-images).
Tout Les robots Google, à l’exception de Googlebot News, n’y ont pas accès
Googlebot et Slurp n’ont aucun accès
Tous les robots n’ont pas accès à deux répertoires
Tous les robots n’ont pas accès à un fichier spécifique
Googlebot n’a pas accès à / admin / et Slurp n’a pas accès à / private /
Robots.txt fichier pour WordPress
Le fichier robots.txt ci-dessous est spécifiquement optimisé pour WordPress, en supposant que:
- Vous ne voulez pas que votre section d’administration soit explorée.
- Vous ne voulez pas que vos pages de résultats de recherche internes soient explorées.
- Vous ne voulez pas que votre balise et les pages de l’auteur soient explorées.
- Vous ne voulez pas que votre balise et vos pages d’auteur soient explorées. t voulez que votre page 404 soit explorée.
Veuillez noter que ce fichier robots.txt fonctionnera dans la plupart des cas, mais vous devez toujours l’ajuster et le tester pour vous assurer qu’il s’applique à votre situation exacte.
Fichier Robots.txt pour Magento
Le fichier robots.txt ci-dessous est spécifiquement optimisé pour Magento, et fera des résultats de recherche internes, des pages de connexion, des identifiants de session et des résultats filtrés ensembles contenant price, color, material et size critères inaccessibles aux robots d’exploration.
Veuillez noter que ce fichier robots.txt fonctionnera pour la plupart des magasins Magento, mais vous devrait toujours l’ajuster et le tester pour s’assurer qu’il s’applique à votre situation exacte.
Je chercherais toujours à bloquer les résultats de recherche internes dans le fichier robots.txt sur n’importe quel site car ces types d’URL de recherche sont des espaces infinis et sans fin. Il y a beaucoup de chances que Googlebot entre dans un piège de robot d’exploration.
Quelles sont les limitations du fichier robots.txt?
Le fichier Robots.txt contient des directives
Même si le fichier robots.txt est bien respecté par la recherche moteurs, c’est toujours une directive et non un mandat.
Pages toujours présentes dans les résultats de recherche
Pages inaccessibles aux moteurs de recherche à cause des robots.txt, mais qui contiennent des liens vers eux, peuvent toujours apparaître dans les résultats de recherche s’ils sont liés à partir d’une page explorée. Un exemple de ce à quoi cela ressemble:

Il est possible de supprimer ces URL de Google à l’aide de l’outil de suppression d’URL de Google Search Console. Veuillez noter que ces URL ne seront que temporairement « masquées ». Pour qu’elles restent en dehors des pages de résultats de Google, vous devez soumettre une demande de masquage des URL tous les 180 jours.

Utilisez le fichier robots.txt pour bloquer les backlinks d’affiliation indésirables et probablement nuisibles. n’utilisez pas le fichier robots.txt pour tenter d’empêcher l’indexation du contenu par les moteurs de recherche, car cela échouera inévitablement. Appliquez plutôt la directive robots noindex si nécessaire.
Le fichier Robots.txt est mis en cache jusqu’à 24 heures
Google a indiqué qu’un fichier robots Le fichier .txt est généralement mis en cache pendant 24 heures maximum. Il est important d’en tenir compte lorsque vous apportez des modifications à votre fichier robots.txt.
La manière dont les autres moteurs de recherche gèrent la mise en cache de robots.txt n’est pas claire. , mais en général, il est préférable d’éviter de mettre en cache votre fichier robots.txt dans av Les moteurs de recherche oid prennent plus de temps que nécessaire pour être en mesure de prendre en compte les modifications.
Taille du fichier Robots.txt
Pour les fichiers robots.txt, Google prend actuellement en charge une limite de taille de fichier de 500 Ko (512 kilo-octets). Tout contenu après cette taille de fichier maximale peut être ignoré.
Il n’est pas clair si les autres moteurs de recherche ont une taille de fichier maximale pour les fichiers robots.txt.
Questions fréquemment posées sur robots.txt
🤖 À quoi ressemble un exemple de fichier robots.txt?
Voici un exemple de contenu d’un fichier robots.txt: User-agent: * Disallow:. Cela indique à tous les robots d’exploration qu’ils peuvent accéder à tout.
⛔ Que fait Disallow all dans le fichier robots.txt?
Lorsque vous définissez un fichier robots.txt sur « Disallow all », vous essentiellement en disant à tous les robots d’exploration de ne pas entrer. Aucun robot, y compris Google, n’est autorisé à accéder à votre site. Cela signifie qu’ils ne pourront pas explorer, indexer et classer votre site. Cela entraînera une baisse massive du trafic organique.
✅ Que fait Autoriser tout dans le fichier robots.txt?
Lorsque vous définissez un fichier robots.txt sur « Tout autoriser », vous indiquez à chaque robot d’exploration qu’il peut accéder à toutes les URL du site. Il n’y a tout simplement pas de règles d’encouragement. Veuillez noter que cela équivaut à avoir un fichier robots.txt vide ou à ne pas avoir de robots.txt du tout.
🤔 Quelle est l’importance du fichier robots.txt pour le référencement?
Dans En général, le fichier robots.txt est très important à des fins de référencement. Pour les sites Web plus volumineux, le fichier robots.txt est essentiel pour donner aux moteurs de recherche des instructions très claires sur le contenu auquel ne pas accéder.