A função de janela ROW_NUMBER tem várias aplicações práticas, muito além das necessidades óbvias de classificação. Na maioria das vezes, quando você calcula os números das linhas, precisa calculá-los com base em alguma ordem e fornece a especificação de ordem desejada na cláusula de ordem da janela da função. No entanto, há casos em que você precisa calcular os números das linhas sem uma ordem específica; em outras palavras, com base na ordem não determinística. Isso pode ocorrer em todo o resultado da consulta ou dentro de partições. Os exemplos incluem a atribuição de valores exclusivos às linhas de resultados, a desduplicação de dados e o retorno de qualquer linha por grupo.
Observe que precisar atribuir números de linha com base em uma ordem não determinística é diferente de precisar atribuí-los com base em ordem aleatória. Com o primeiro, você simplesmente não se importa em que ordem eles são atribuídos e se as execuções repetidas da consulta continuam atribuindo os mesmos números de linha às mesmas linhas ou não. Com o último, você espera que as execuções repetidas continuem alterando quais linhas são atribuídas a quais números de linha. Este artigo explora diferentes técnicas para calcular números de linhas com ordem não determinística. A esperança é encontrar uma técnica que seja confiável e ideal.
Agradecimentos especiais a Paul White pela dica sobre dobramento constante, pela técnica constante de tempo de execução e por sempre ser uma grande fonte de informação!
Quando a ordem é importante
Vou começar com casos em que a ordem do número da linha importa.
Usarei uma tabela chamada T1 em meus exemplos. Use o seguinte código para criar esta tabela e preenchê-la com dados de amostra:
Considere a seguinte consulta (vamos chamá-la de Consulta 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Aqui você deseja que os números das linhas sejam atribuídos dentro de cada grupo identificado pela coluna grp, ordenados pela coluna datacol. Quando executei esta consulta em meu sistema, obtive a seguinte saída:
id grp datacol n--- ---- -------- ---5 A 40 12 A 50 211 A 50 37 B 10 13 B 20 2
Os números das linhas são atribuídos aqui em uma ordem parcialmente determinística e parcialmente não determinística. O que quero dizer com isso é que você tem uma garantia de que dentro da mesma partição, uma linha com um valor de datacol maior terá um valor de número de linha maior. No entanto, uma vez que o datacol não é único dentro da partição grp, a ordem de atribuição dos números de linha entre as linhas com os mesmos valores grp e datacol é não determinística. Esse é o caso com as linhas com valores de id 2 e 11. Ambas têm o valor grp A e o valor de datacol 50. Quando executei esta consulta no meu sistema pela primeira vez, a linha com id 2 obteve a linha 2 e o a linha com id 11 obteve a linha 3. Não importa a probabilidade de isso acontecer na prática no SQL Server; se eu executar a consulta novamente, teoricamente, a linha com id 2 poderia ser atribuída com a linha número 3 e a linha com id 11 poderia ser atribuída com a linha número 2.
Se você precisar atribuir números de linha com base em uma ordem completamente determinística, garantindo resultados repetíveis nas execuções da consulta, desde que os dados subjacentes não mudem, você precisa que a combinação de elementos no particionamento da janela e nas cláusulas de ordenação seja única. Isso pode ser alcançado em nosso caso adicionando o id da coluna à cláusula de ordem da janela como um desempatador. A cláusula OVER seria então:
OVER (PARTITION BY grp ORDER BY datacol, id)
De qualquer forma, ao calcular os números das linhas com base em alguma especificação de ordenação significativa como na Consulta 1, o SQL Server precisa processar o linhas ordenadas pela combinação de particionamento de janela e elementos de ordenação. Isso pode ser obtido puxando os dados pré-ordenados de um índice ou classificando os dados. No momento, não há índice em T1 para dar suporte ao cálculo ROW_NUMBER na Consulta 1, portanto, o SQL Server deve optar por classificar os dados. Isso pode ser visto no plano da Consulta 1 mostrado na Figura 1.
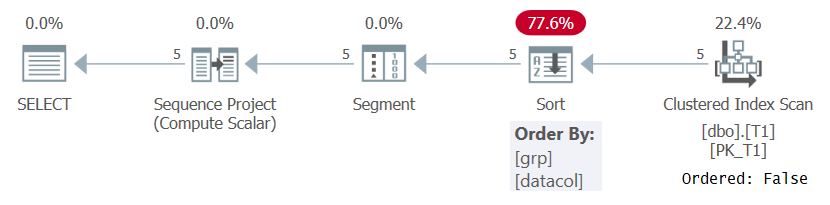 Figura 1: Plano da Consulta 1 sem um índice de suporte
Figura 1: Plano da Consulta 1 sem um índice de suporte
Observe que o plano varre os dados do índice clusterizado com uma propriedade Ordered: False. Isso significa que a varredura não precisa retornar as linhas ordenadas pela chave de índice. Esse é o caso, pois o índice clusterizado é usado aqui apenas porque ele cobre a consulta e não por causa de sua ordem de chave. O plano então aplica uma classificação, resultando em custo extra, escala N Log N e tempo de resposta atrasado. O operador Segment produz um sinalizador que indica se a linha é a primeira na partição ou não. Finalmente, o operador Sequence Project atribui números de linha começando com 1 em cada partição.
Se você deseja evitar a necessidade de classificação, pode preparar um índice de cobertura com uma lista de chaves baseada nos elementos de particionamento e ordenação e uma lista de inclusão baseada nos elementos de cobertura.Gosto de pensar neste índice como um índice POC (para particionar, ordenar e cobrir). Aqui está a definição do POC que suporta nossa consulta:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Execute a Consulta 1 novamente:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
O plano para essa execução é mostrado na Figura 2.
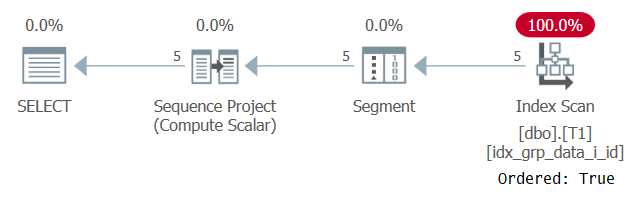 Figura 2: Plano para a consulta 1 com um índice POC
Figura 2: Plano para a consulta 1 com um índice POC
Observe que desta vez o plano varre o índice POC com uma propriedade Ordered: True. Isso significa que a varredura garante que as linhas serão retornadas na ordem da chave do índice. Uma vez que os dados são pré-ordenados do índice como a função da janela precisa, não há necessidade de classificação explícita. A escala desse plano é linear e o tempo de resposta é bom.
Quando a ordem não importa
As coisas ficam um pouco complicadas quando você precisa atribuir números de linha com um valor completamente não determinístico ordem. A coisa natural a se querer nesse caso é usar a função ROW_NUMBER sem especificar uma cláusula de ordem de janela. Primeiro, vamos verificar se o padrão SQL permite isso. Aqui está a parte relevante do padrão que define as regras de sintaxe para janela funções:
Observe que o item 6 lista as funções < função ntile >, < função lead ou lag >, < tipo de função de classificação > ou ROW_NUMBER, e o item 6a diz que para as funções < função ntile >, < função lead ou lag >, RANK ou DENSE_RANK a cláusula de ordem de janela deve b e presente. Não há linguagem explícita afirmando se ROW_NUMBER requer uma cláusula de ordem de janela ou não, mas a menção da função no item 6 e sua omissão em 6a pode implicar que a cláusula é opcional para esta função. É bastante óbvio por que funções como RANK e DENSE_RANK exigiriam uma cláusula de ordem de janela, uma vez que essas funções se especializam em lidar com empates, e empates só existe quando há especificação de pedido. No entanto, você certamente pode ver como a função ROW_NUMBER pode se beneficiar de uma cláusula de ordem de janela opcional.
Então, vamos fazer uma tentativa e tentar calcular os números de linha sem ordem de janela no SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Esta tentativa resulta no seguinte erro:
A função “ROW_NUMBER” deve ter uma cláusula OVER com ORDER BY.
Na verdade, se você verificar a documentação do SQL Server da função ROW_NUMBER, encontrará o seguinte texto:
O ORDER A cláusula BY determina a seqüência na qual as linhas são atribuídas a seu ROW_NUMBER exclusivo dentro de uma partição especificada. É obrigatório. ”
Portanto, aparentemente, a cláusula de ordem das janelas é obrigatória para a função ROW_NUMBER no SQL Server . Esse também é o caso do Oracle, a propósito.
Devo dizer que não tenho certeza se entendi o motivoi ng por trás deste requisito. Lembre-se de que você está permitindo definir números de linha com base em uma ordem parcialmente não-determinística, como na Consulta 1. Então, por que não permitir o não-determinismo totalmente? Talvez haja algum motivo no qual não estou pensando. Se você pode pensar em tal motivo, por favor, compartilhe.
De qualquer forma, você poderia argumentar que, se não se preocupa com a ordem, visto que a cláusula de ordem das janelas é obrigatória, você pode especificar qualquer ordem. O problema com essa abordagem é que se você ordenar por alguma coluna da (s) tabela (s) consultada (s), isso pode envolver uma penalidade de desempenho desnecessária. Quando não há nenhum índice de suporte em vigor, você pagará pela classificação explícita. Quando há um índice de suporte em vigor, você está limitando o mecanismo de armazenamento a uma estratégia de varredura de ordem de índice (seguindo a lista vinculada de índice). Você não permite mais flexibilidade como normalmente ocorre quando a ordem não importa ao escolher entre uma varredura de ordem de índice e uma varredura de ordem de alocação (com base nas páginas IAM).
Uma ideia que vale a pena tentar é especificar uma constante, como 1, na cláusula de ordem da janela. Se houver suporte, você espera que o otimizador seja inteligente o suficiente para perceber que todas as linhas têm o mesmo valor, portanto, não há relevância de ordenação real e, portanto, não há necessidade de forçar uma classificação ou uma varredura de ordem de índice. Aqui está uma consulta tentando essa abordagem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Infelizmente, o SQL Server não oferece suporte a esta solução. Ele gera o seguinte erro:
Funções em janela, agregados e funções NEXT VALUE FOR não oferecem suporte a índices inteiros como expressões de cláusula ORDER BY.
Aparentemente, o SQL Server assume que se você estiver usando uma constante inteira na cláusula de ordem da janela, ela representa uma posição ordinal de um elemento na lista SELECT, como quando você especifica um número inteiro na apresentação ORDER Cláusula BY. Se for esse o caso, outra opção que vale a pena tentar é especificar uma constante não inteira, como:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No Order") AS n FROM dbo.T1;
Acontece que esta solução também não tem suporte. O SQL Server gera o seguinte erro:
Funções em janela, agregados e funções NEXT VALUE FOR não oferecem suporte a constantes como expressões de cláusula ORDER BY.
Aparentemente, a cláusula de ordem da janela não suporta nenhum tipo de constante.
Até agora, aprendemos o seguinte sobre a relevância da ordem da janela da função ROW_NUMBER no SQL Server:
- ORDER BY é obrigatório.
- Não é possível ordenar por uma constante inteira porque o SQL Server pensa que você está tentando especificar uma posição ordinal no SELECT.
- Não é possível ordenar por qualquer tipo de constante.
A conclusão é que você deve ordenar por expressões que não são constantes. Obviamente, você pode ordenar por uma lista de colunas da (s) tabela (s) consultada (s). Mas estamos em uma busca para encontrar uma solução eficiente onde o otimizador possa perceber que não há relevância de ordenação.
Dobra constante
A conclusão até agora é que você não pode usar constantes em a A cláusula de ordem da janela de ROW_NUMBER, mas e as expressões baseadas em constantes, como na seguinte consulta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
No entanto, esta tentativa é vítima de um processo conhecido como constante dobrar, que normalmente tem um impacto de desempenho positivo nas consultas. A ideia por trás dessa técnica é melhorar o desempenho da consulta, juntando algumas expressões com base em constantes em suas constantes de resultado em um estágio inicial do processamento da consulta. Você pode encontrar detalhes sobre quais tipos de expressões podem ser dobrados constantemente aqui. Nossa expressão 1 + 0 é dobrada para 1, resultando no mesmo erro que você obteve ao especificar a constante 1 diretamente:
Funções em janela, agregados e funções NEXT VALUE FOR não suportam índices inteiros como expressões de cláusula ORDER BY.
Você enfrentaria uma situação semelhante ao tentar concatenar dois literais de string de caracteres, como:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY "No" + " Order") AS n FROM dbo.T1;
Você obtém o mesmo erro ao especificar o literal “Sem pedido” diretamente:
Em janela funções, agregados e funções NEXT VALUE FOR não suportam constantes como expressões de cláusula ORDER BY.
Mundo bizarro – erros que evitam erros
A vida é cheia de surpresas…
Uma coisa que impede o dobramento constante é quando a expressão normalmente resultaria em um erro. Por exemplo, a expressão 2147483646 + 1 pode ser dobrada constante, pois resulta em um valor válido digitado em INT. Consequentemente, uma tentativa de executar a seguinte consulta falha:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;
Funções em janelas, agregados e PRÓXIMO VALOR As funções FOR não suportam índices inteiros como expressões de cláusula ORDER BY.
No entanto, a expressão 2147483647 + 1 não pode ser dobrada constante porque tal tentativa teria resultado em um erro de estouro de INT. A implicação no pedido é bastante interessante. Tente a seguinte consulta (chamaremos esta de Consulta 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Estranhamente, esta consulta foi executada com sucesso! O que acontece é que, por um lado, o SQL Server não consegue aplicar dobradura constante e, portanto, a ordem é baseada em uma expressão que não é uma única constante. Por outro lado, o otimizador calcula que o valor de ordenação é o mesmo para todas as linhas, portanto, ignora a expressão de ordenação por completo. Isso é confirmado ao examinar o plano para esta consulta, conforme mostrado na Figura 3.
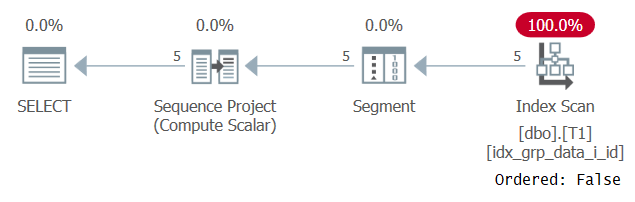 Figura 3: Plano para a consulta 2
Figura 3: Plano para a consulta 2
Observe que o plano varre algum índice de cobertura com uma propriedade Ordered: False. Essa era exatamente nossa meta de desempenho.
De maneira semelhante, a consulta a seguir envolve uma tentativa de dobrar constante bem-sucedida e, portanto, falha:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;
Funções em janela, agregados e funções NEXT VALUE FOR não suportam índices inteiros como expressões de cláusula ORDER BY.
A consulta a seguir envolve uma tentativa falhada de dobrar constante e, portanto, é bem-sucedida, gerando o plano mostrado anteriormente na Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
O seguinte a consulta envolve uma tentativa de dobramento constante bem-sucedida (VARCHAR literal “1” é implicitamente convertido para INT 1 e, em seguida, 1 + 1 é dobrado para 2) e, portanto, falha:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"1") AS n FROM dbo.T1;
Funções em janela, agregados e funções NEXT VALUE FOR não suportam índices inteiros como expressões de cláusula ORDER BY.
A consulta a seguir envolve um falha na tentativa de dobramento constante (não é possível converter “A” em INT) e, portanto, é bem-sucedida, gerando o plano mostrado anteriormente na Figura 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+"A") AS n FROM dbo.T1;
Para ser honesto, embora essa técnica bizarra atinja nosso objetivo de desempenho original, não posso dizer que a considero segura e, portanto, não me sinto tão confortável em confiar nela.
Constantes de tempo de execução baseadas em funções
Continuando a busca por uma boa solução para calcular números de linhas com ordem não determinística, existem algumas técnicas que parecem mais seguras do que a última solução peculiar: usar constantes de tempo de execução baseadas em funções, usar uma subconsulta baseada em uma constante, usar um coluna com alias baseada em uma constante e usando uma variável.
Como explico no T-SQL bugs, armadilhas e práticas recomendadas – determinismo, a maioria das funções no T-SQL são avaliadas apenas uma vez por referência na consulta – não uma vez por linha. Este é o caso mesmo com a maioria das funções não determinísticas como GETDATE e RAND. Existem muito poucas exceções a esta regra, como as funções NEWID e CRYPT_GEN_RANDOM, que são avaliadas uma vez por linha. A maioria das funções, como GETDATE, @@ SPID e muitas outras, são avaliadas uma vez no início da consulta e seus valores são considerados constantes de tempo de execução. Uma referência a tais funções não é dobrada constantemente. Essas características tornam uma constante de tempo de execução baseada em uma função uma boa escolha como o elemento de ordenação de janela e, de fato, parece que o T-SQL a suporta. Ao mesmo tempo, o otimizador percebe que na prática não há relevância de ordenação, evitando penalidades de desempenho desnecessárias.
Aqui está um exemplo usando a função GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
Esta consulta obtém o mesmo plano mostrado anteriormente na Figura 3.
Aqui está outro exemplo usando a função @@ SPID (retornando o ID da sessão atual):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
E quanto à função PI? Tente a seguinte consulta:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Este falha com o seguinte erro:
Funções em janela, agregados e funções NEXT VALUE FOR não suportam constantes como expressões de cláusula ORDER BY.
Funções como GETDATE e @@ SPID são reavaliadas uma vez por execução do plano, portanto, não podem ser dobrado constante. PI representa sempre a mesma constante e, portanto, é dobrado constantemente.
Conforme mencionado anteriormente, existem muito poucas funções que são avaliadas uma vez por linha, como NEWID e CRYPT_GEN_RANDOM. Isso os torna uma escolha ruim como o elemento de ordenação da janela se você precisar de ordem não determinística – não confunda com ordem aleatória. Por que pagar uma penalidade de classificação desnecessária?
Aqui está um exemplo usando a função NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
O plano para esta consulta é mostrado na Figura 4, confirmando que o SQL Server adicionou explícito classificação com base no resultado da função.
 Figura 4: Plano para a consulta 3
Figura 4: Plano para a consulta 3
Se você deseja que os números das linhas sejam atribuídos em ordem aleatória, sem dúvida, essa é a técnica que você deseja usar. Você só precisa estar ciente de que isso incorre no custo de classificação.
Usando uma subconsulta
Você também pode usar uma subconsulta baseada em uma constante como a expressão de ordenação da janela (por exemplo, ORDER BY (SELECIONE “Sem pedido”)). Além disso, com esta solução, o otimizador do SQL Server reconhece que não há relevância de ordenação e, portanto, não impõe uma classificação desnecessária ou limita as escolhas do mecanismo de armazenamento àquelas que devem garantir a ordem. Tente executar a seguinte consulta como exemplo:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "No Order")) AS n FROM dbo.T1;
Você obtém o mesmo plano mostrado anteriormente na Figura 3.
Um dos grandes benefícios desta técnica é que você pode adicionar seu próprio toque pessoal.Talvez você realmente goste de NULLs:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Talvez você realmente goste de um determinado número:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Talvez você queira enviar uma mensagem para alguém:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT "Lilach, will you marry me?")) AS n FROM dbo.T1;
Você entendeu.
Possível, mas estranho
Existem algumas técnicas que funcionam, mas são um pouco estranhas. Uma é definir um alias de coluna para uma expressão com base em uma constante e, em seguida, usar esse alias de coluna como o elemento de ordenação da janela. Você pode fazer isso usando uma expressão de tabela ou com o operador CROSS APPLY e um construtor de valor de tabela. Aqui está um exemplo para o último:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY ) AS n FROM dbo.T1 CROSS APPLY ( VALUES("No Order") ) AS A();
Você obtém o mesmo plano mostrado anteriormente na Figura 3.
Outra opção é usar uma variável como o elemento de ordenação da janela:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
Essa consulta também obtém o plano mostrado anteriormente na Figura 3.
E se eu usar meu próprio UDF ?
Você pode pensar que usar seu próprio UDF que retorna uma constante pode ser uma boa escolha como o elemento de ordenação de janela quando deseja uma ordem não determinística, mas não é. Considere a seguinte definição de UDF como exemplo:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis;GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INTASBEGIN RETURN NULLEND;GO
Tente usar a UDF como a cláusula de ordenação da janela, assim (chamaremos esta de Consulta 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Antes do SQL Server 2019 (ou nível de compatibilidade paralelo < 150), as funções definidas pelo usuário são avaliadas por linha . Mesmo se eles retornarem uma constante, eles não ficam embutidos. Conseqüentemente, por um lado, você pode usar esse UDF como o elemento de ordenação da janela, mas por outro lado, isso resulta em uma penalidade de classificação. Isso é confirmado examinando o plano para esta consulta, conforme mostrado na Figura 5.
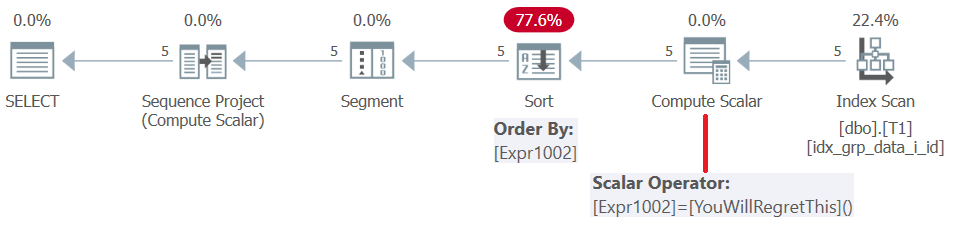 Figura 5: Plano para a consulta 4
Figura 5: Plano para a consulta 4
A partir do SQL Server 2019, no nível de compatibilidade > = 150, essas funções definidas pelo usuário são incorporadas, o que é muito bom, mas em nosso caso resulta em um erro:
Funções em janela, agregados e funções NEXT VALUE FOR não suportam constantes como expressões de cláusula ORDER BY.
Portanto, usando um UDF baseado em uma constante como o elemento de ordenação da janela força uma classificação ou um erro, dependendo da versão do SQL Server que você está usando e do nível de compatibilidade do banco de dados. Resumindo, não faça isso.
Números de linhas particionadas com ordem não determinística
Um caso de uso comum para números de linhas particionadas com base em ordem não determinística é retornar qualquer linha por grupo. Dado que, por definição, existe um elemento de particionamento neste cenário, você pensaria que uma técnica segura em tal caso seria usar o elemento de particionamento de janela também como o elemento de ordenação de janela. Como primeira etapa, você calcula os números das linhas da seguinte forma:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
O plano para esta consulta é mostrado na Figura 6.
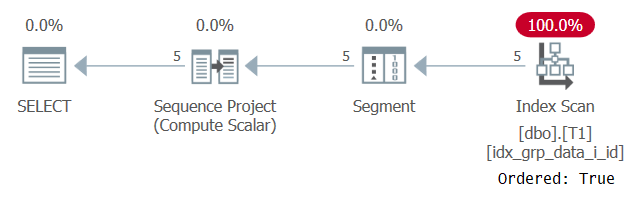 Figura 6: Plano para consulta 5
Figura 6: Plano para consulta 5
O motivo de nosso índice de suporte ser verificado com uma propriedade Ordered: True é porque o SQL Server precisa processar as linhas de cada partição como um única unidade. Esse é o caso antes da filtragem. Se você filtrar apenas uma linha por partição, terá algoritmos baseados em ordem e hash como opções.
A segunda etapa é colocar a consulta com o cálculo do número da linha em uma expressão de tabela e em a consulta externa filtra a linha com a linha número 1 em cada partição, da seguinte forma:
Teoricamente, esta técnica é supostamente segura, mas Paul White encontrou um bug que mostra que usando este método você pode obter atributos de diferentes linhas de origem na linha de resultado retornada por partição. Usar uma constante de tempo de execução com base em uma função ou uma subconsulta com base em uma constante como o elemento de ordenação parece ser seguro mesmo com este cenário, então certifique-se de usar uma solução como a seguinte:
Ninguém deve passar por aqui sem minha permissão
Tentar calcular números de linha com base em ordem não determinística é uma necessidade comum. Teria sido bom se o T-SQL simplesmente tornasse a cláusula de ordem da janela opcional para a função ROW_NUMBER, mas não faz. Caso contrário, teria sido bom se pelo menos permitisse o uso de uma constante como o elemento de ordenação, mas essa também não é uma opção compatível.Mas se você perguntar com educação, na forma de uma subconsulta com base em uma constante ou uma constante de tempo de execução com base em uma função, o SQL Server permitirá. Estas são as duas opções com as quais estou mais confortável. Eu realmente não me sinto confortável com as expressões errôneas peculiares que parecem funcionar, então não posso recomendar esta opção.