A robôs O arquivo .txt contém diretivas para mecanismos de pesquisa. Você pode usá-lo para evitar que os mecanismos de pesquisa rastreiem partes específicas do seu site e para dar dicas úteis aos mecanismos de pesquisa sobre como eles podem rastrear melhor o seu site. O arquivo robots.txt desempenha um grande papel no SEO.
Ao implementar o robots.txt, mantenha as seguintes práticas recomendadas em mente:
- Tenha cuidado ao fazer alterações em seu robots.txt: esse arquivo tem o potencial de tornar grandes partes do seu site inacessíveis para mecanismos de pesquisa.
- O arquivo robots.txt deve residir na raiz do seu site (por exemplo,
- The robots.txt file is only valid for the full domain it resides on, including the protocol (
httpouhttps). - Diferentes mecanismos de pesquisa interpretam as diretivas de maneiras diferentes. Por padrão, a primeira diretiva correspondente sempre vence. Mas, com o Google e o Bing, a especificidade vence.
- Evite usar a diretiva de atraso de rastreamento para mecanismos de pesquisa, tanto quanto possível.
O que é um Arquivo robots.txt?
Um arquivo robots.txt informa aos mecanismos de pesquisa quais são as regras de engajamento do seu site. Uma grande parte do SEO é enviar os sinais certos aos mecanismos de pesquisa, e o robots.txt é uma das maneiras de comunicar suas preferências de rastreamento aos mecanismos de pesquisa.
Em 2019, vimos bastante alguns desenvolvimentos em torno do padrão do robots.txt: o Google propôs uma extensão para o protocolo de exclusão de robôs e abriu o código do analisador do robots.txt.
TL; DR
- robôs do Google O intérprete .txt é bastante flexível e surpreendentemente indulgente.
- Em caso de confusão com as diretrizes, o Google erra pelos lados seguros e assume que as seções devem ser restritas em vez de irrestritas.
Os mecanismos de pesquisa verificam regularmente o arquivo robots.txt de um site para ver se há instruções para rastrear o site. Chamamos essas instruções de diretivas.
Se não houver nenhum arquivo robots.txt presente ou se não houver diretivas aplicáveis, os mecanismos de pesquisa rastrearão todo o site.
Embora todos os principais mecanismos de pesquisa respeitem o arquivo robots.txt, os mecanismos de pesquisa podem escolher ignorar (partes do) seu arquivo robots.txt. Embora as diretivas no arquivo robots.txt sejam um forte sinal para os mecanismos de pesquisa, é importante lembrar que o arquivo robots.txt é um conjunto de diretivas opcionais para os mecanismos de pesquisa, e não uma ordem.

O robots.txt é o arquivo mais sensível no universo SEO. Um único caractere pode destruir um site inteiro.
Terminologia em torno do arquivo robots.txt
O arquivo robots.txt é a implementação do padrão de exclusão de robôs, ou também chamado o protocolo de exclusão de robôs.
Por que você deve se preocupar com o robots.txt?
O robots.txt desempenha um papel essencial do ponto de vista de SEO. Ele informa aos mecanismos de pesquisa como eles podem rastrear melhor o seu site.
Usando o arquivo robots.txt, você pode impedir que os mecanismos de pesquisa acessem certas partes do seu site, evitar conteúdo duplicado e dar dicas úteis aos mecanismos de pesquisa sobre como eles pode rastrear seu site com mais eficiência.
No entanto, tenha cuidado ao fazer alterações em seu robots.txt: esse arquivo tem o potencial de tornar grandes partes de seu site inacessíveis para mecanismos de pesquisa.

Robots.txt é frequentemente usado demais para reduzir o conteúdo duplicado, portanto matando links internos, então tenha muito cuidado com isso. Meu conselho é sempre usá-lo para arquivos ou páginas que os mecanismos de pesquisa nunca deveriam ver, ou podem impactar significativamente o rastreamento ao serem permitidos. Exemplos comuns: áreas de login que geram muitos URLs diferentes, áreas de teste ou onde pode existir navegação multifacetada. E certifique-se de monitorar seu arquivo robots.txt em busca de quaisquer problemas ou alterações.

A maioria dos problemas que vejo com os arquivos robots.txt se enquadra em três grupos:
- O manuseio incorreto de curingas. É bastante comum ver partes do site bloqueadas que deveriam ser bloqueadas. Às vezes, se você não for cuidadoso, as diretivas também podem entrar em conflito umas com as outras.
- Alguém, como um desenvolvedor, fez uma mudança inesperada (geralmente ao enviar um novo código) e alterou inadvertidamente o robots.txt sem o seu conhecimento.
- A inclusão de diretivas que não pertencem a um arquivo robots.txt. Robots.txt é um padrão da web e um tanto limitado Muitas vezes vejo desenvolvedores criando diretivas que simplesmente não funcionam (pelo menos para a grande maioria dos rastreadores). Às vezes, isso é inofensivo, às vezes nem tanto.
Exemplo
Vejamos um exemplo para ilustrar isso:
Você está executando um site de comércio eletrônico e os visitantes podem usar um filtro para pesquisar rapidamente seus produtos. Este filtro gera páginas que basicamente mostram o mesmo conteúdo que outras páginas. Isso funciona muito bem para os usuários, mas confunde os mecanismos de pesquisa porque cria conteúdo duplicado.
Você não quer que os mecanismos de pesquisa indexem essas páginas filtradas e desperdiçam seu valioso tempo nesses URLs com conteúdo filtrado. Portanto, você deve configurar Disallow regras para que os mecanismos de pesquisa não acessem essas páginas de produtos filtradas.
A prevenção de conteúdo duplicado também pode ser feita usando o URL canônico ou a metatag de robôs, no entanto, isso não permite que os mecanismos de pesquisa rastreiem apenas as páginas que importam.
Usar um URL canônico ou uma metatag de robôs não impedirá que os mecanismos de pesquisa rastreiem essas páginas. Isso apenas impedirá que os mecanismos de pesquisa mostrem essas páginas nos resultados da pesquisa. Como os mecanismos de pesquisa têm tempo limitado para rastrear um site, esse tempo deve ser gasto nas páginas que você deseja que apareçam nos mecanismos de pesquisa.
Um arquivo robots.txt configurado incorretamente pode estar impedindo seu desempenho de SEO. Verifique se este é o caso do seu site imediatamente!

É uma ferramenta muito simples, mas um arquivo robots.txt pode causar muitos problemas se não for configurado corretamente, principalmente para sites maiores. É muito fácil cometer erros, como bloquear um site inteiro após o lançamento de um novo design ou CMS ou não bloquear seções de um site que deveriam ser privadas. Para sites maiores, garantir o rastreamento do Google com eficiência é muito importante, e um arquivo robots.txt bem estruturado é uma ferramenta essencial nesse processo.
Você precisa dedicar um tempo para entender quais seções do seu site devem ser mantidas afastadas do Google para que eles gastem o máximo possível de seus recursos rastreando as páginas de seu interesse.
Qual é a aparência de um arquivo robots.txt?
Um exemplo de como um arquivo robots.txt simples para um site WordPress pode parecido com:
Vamos explicar a anatomia de um arquivo robots.txt com base no exemplo acima:
- User-agent: o
user-agentindica para qual pesquisa motores, as diretivas a seguir se referem. -
*: isso indica que as diretivas são destinadas a todos os mecanismos de pesquisa. -
Disallow: esta é uma diretiva que indica qual conteúdo não está acessível aouser-agent. -
/wp-admin/: este é opathque está inacessível parauser-agent.
Em resumo: este arquivo robots.txt diz a todos os mecanismos de pesquisa para ficarem fora do diretório /wp-admin/.
Vamos analisar os diferentes componentes dos arquivos robots.txt em mais detalhes:
- User-agent
- Disallow
- Allow
- Sitemap
- Atraso de rastreamento
User-agent em robots.txt
Cada mecanismo de pesquisa deve se identificar com um user-agent. Os robôs do Google são identificados como Googlebot, por exemplo, os robôs do Yahoo como Slurp e o robô do Bing como BingBot e assim por diante.
O registro user-agent define o início de um grupo de diretivas. Todas as diretivas entre o primeiro user-agent e o próximo user-agent registro são tratadas como diretivas para o primeiro user-agent.
As diretivas podem ser aplicadas a agentes de usuário específicos, mas também podem ser aplicáveis a todos os agentes de usuário. Nesse caso, um curinga é usado: User-agent: *.
Diretiva de não permitir no robots.txt
Você pode dizer aos mecanismos de pesquisa para não acessar determinados arquivos, páginas ou seções do seu site. Isso é feito usando a diretiva Disallow. A diretiva Disallow é seguida pela path que não deve ser acessada. Se nenhum path for definido, a diretiva será ignorada.
Exemplo
Neste exemplo, todos os mecanismos de pesquisa são instruídos a não acessar o diretório /wp-admin/.
Permitir diretiva em robots.txt
A diretiva Allow é usada para neutralizar uma diretiva Disallow. A diretiva Allow é compatível com o Google e o Bing. Usando as diretivas Allow e Disallow juntas, você pode dizer aos mecanismos de pesquisa que eles podem acessar um arquivo ou página específica em um diretório que, de outra forma, não é permitido. A diretiva Allow é seguida pela path que pode ser acessada. Se nenhum path for definido, a diretiva será ignorada.
Exemplo
No exemplo acima, todos os mecanismos de pesquisa não têm permissão para acessar o /media/ diretório, exceto para o arquivo /media/terms-and-conditions.pdf.
Importante: ao usar Allow e Disallow diretivas juntas, certifique-se de não usar curingas, pois isso pode levar a diretivas conflitantes.
Exemplo de diretivas conflitantes
Os mecanismos de pesquisa não saberão o que fazer com o URL . Não está claro para eles se têm permissão para acessar. Quando as diretivas não são claras para o Google, eles seguem a diretiva menos restritiva, o que, neste caso, significa que eles iriam de fato acessar
Disallow rules in a site’s robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed – but improper use of disallow rules can severely damage a site’s SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/ 
Robots.txt é um dos recursos que vejo mais comumente implementado incorretamente, por isso não está bloqueando o que eles queriam bloquear ou está bloqueando mais do que o esperado e tem um impacto negativo no site. Robots.txt é uma ferramenta muito poderosa, mas frequentemente está configurada incorretamente.
Usando curinga *
O curinga não só pode ser usado para definir o user-agent, mas também pode ser usado para corresponder URLs. O curinga é compatível com Google, Bing, Yahoo e Ask.
Exemplo
No exemplo acima, todos os mecanismos de pesquisa não têm permissão para acessar URLs que incluam um ponto de interrogação (?).

Desenvolvedores ou proprietários de sites muitas vezes parecem pensar que podem utilizar todos os tipos de expressão regular em um arquivo robots.txt enquanto apenas uma quantidade muito limitada de correspondência de padrões é realmente válida – por exemplo, curingas (
*). Parece haver uma confusão entre arquivos .htaccess e arquivos robots.txt de vez em quando.
Usando o final do URL $
Para indicar o final de um URL, você pode usar o cifrão ($) no final do path.
Exemplo
No exemplo acima, os mecanismos de pesquisa não têm permissão para acessar todos os URLs que terminam com .php . URLs com parâmetros, por exemplo não seria desautorizado, pois o URL não termina depois de .php.
Adicione o mapa do site aos robôs. txt
Embora o arquivo robots.txt tenha sido inventado para informar aos mecanismos de pesquisa quais páginas não devem ser rastreadas, o arquivo robots.txt também pode ser usado para apontar os mecanismos de pesquisa para o mapa do site XML. Isso é compatível com Google, Bing, Yahoo e Ask.
O mapa do site XML deve ser referenciado como um URL absoluto. O URL não precisa estar no mesmo host do arquivo robots.txt.
Fazer referência ao mapa do site XML no arquivo robots.txt é uma das melhores práticas que aconselhamos sempre a fazer, embora você já pode ter enviado o seu sitemap XML no Google Search Console ou nas Ferramentas do Google para webmasters. Lembre-se de que existem mais mecanismos de pesquisa por aí.
Observe que é possível fazer referência a vários sitemaps XML em um arquivo robots.txt.
Exemplos
Vários Sitemaps XML definidos em um arquivo robots.txt:
Um único sitemap XML definido em robôs.arquivo txt:
O exemplo acima diz a todos os mecanismos de pesquisa para não acessar o diretório /wp-admin/ e que o mapa do site XML pode ser encontrado em
Comments are preceded by a # e pode ser colocado no início de uma linha ou após uma diretiva na mesma linha. Tudo depois de # será ignorado. Estes comentários destinam-se apenas a humanos.
Exemplo 1
Exemplo 2
Os exemplos acima comunicam a mesma mensagem.
Atraso de rastreamento em robots.txt
O Crawl-delay diretiva é uma diretiva não oficial usada para evitar sobrecarregar servidores com muitas solicitações. Se os mecanismos de pesquisa são capazes de sobrecarregar um servidor, adicionar Crawl-delay ao seu arquivo robots.txt é apenas uma correção temporária. O fato é que seu site está funcionando em um ambiente de hospedagem ruim e / ou está configurado incorretamente e você deve corrigir isso o mais rápido possível.
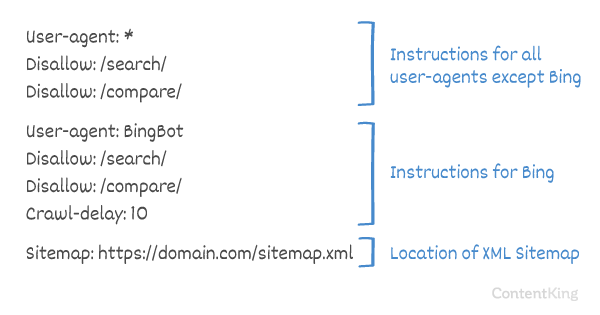
A maneira como os mecanismos de pesquisa lidam com Crawl-delay é diferente. A seguir, explicamos como os principais mecanismos de pesquisa lidam com isso.
Atraso de rastreamento e Google
O rastreador do Google, o Googlebot, não oferece suporte ao Crawl-delay diretiva, portanto, não se preocupe em definir um atraso de rastreamento do Google.
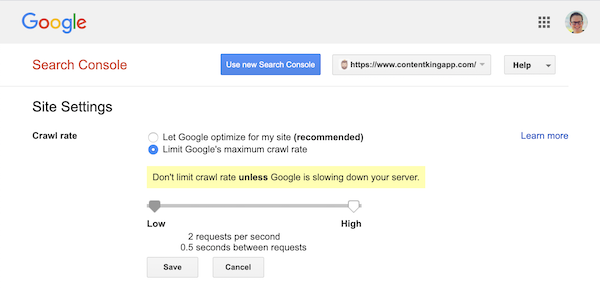
No entanto, o Google oferece suporte para definir uma taxa de rastreamento (ou “taxa de solicitação”, se preferir ) no Google Search Console.
- Faça login no antigo Google Search Console.
- Escolha o site que você deseja definir a taxa de rastreamento para.
- Há apenas uma configuração que você pode ajustar:
Crawl rate, com um controle deslizante onde você pode definir a taxa de rastreamento preferida. Por padrão a taxa de rastreamento é definida como “Deixe o Google otimizar para meu site (recomendado)”.
Isso é o que parece no Google Search Console:
Atraso de rastreamento e Bing, Yahoo e Yandex
Bing, Yahoo e Yandex todos apoiam o Crawl-delay diretiva para controlar o rastreamento de um site. A interpretação do atraso do rastreamento é um pouco diferente, portanto, certifique-se de verificar a documentação:
- Bing e Yahoo
- Yandex
A diretiva Crawl-delay deve ser colocada logo após as diretivas Disallow ou Allow.
Exemplo:
Atraso de rastreamento e Baidu
O Baidu não oferece suporte à diretiva crawl-delay, no entanto, é possível registrar uma conta das Ferramentas do Google para webmasters do Baidu em que você pode controlar a frequência de rastreamento, semelhante ao Google Search Console.
Quando usar um arquivo robots.txt?
Recomendamos sempre usar um arquivo robots.txt. Não há absolutamente nenhum mal em ter um, e é um ótimo lugar para fornecer diretivas de mecanismos de pesquisa sobre como eles podem rastrear melhor seu site.

O robots.txt pode ser útil para evitar que certas áreas ou documentos em seu site sejam rastreados e indexados. Os exemplos são, por exemplo, o site de teste ou PDFs. Planeje cuidadosamente o que precisa ser indexado pelos mecanismos de pesquisa e esteja ciente de que o conteúdo que se tornou inacessível por meio do robots.txt ainda pode ser encontrado pelos rastreadores do mecanismo de pesquisa se estiver vinculado a outras áreas do site.
Práticas recomendadas para Robots.txt
As práticas recomendadas do robots.txt são categorizadas da seguinte forma:
- Local e nome do arquivo
- Ordem de precedência
- Apenas um grupo de diretivas por robô
- Seja o mais específico possível
- Diretivas para todos os robôs e, ao mesmo tempo, inclua diretivas para um robô específico
- Arquivo Robots.txt para cada (sub) domínio.
- Diretrizes conflitantes: robots.txt vs. Google Search Console
- Monitore seu arquivo robots.txt
- Não use noindex em seu robots.txt
- Impedir BOM UTF-8 no arquivo robots.txt
Local e nome do arquivo
O arquivo robots.txt deve sempre ser colocado no e root de um site (no diretório de nível superior do host) e carrega o nome do arquivo robots.txt, por exemplo: . Observe que o URL do arquivo robots.txt, como qualquer outro URL, diferencia maiúsculas de minúsculas.
Se o arquivo robots.txt não puder ser encontrado no local padrão, os mecanismos de pesquisa irão presumir que não há diretivas e irão se arrastar para fora do seu site.
Ordem de precedência
É importante observar que os mecanismos de pesquisa tratam os arquivos robots.txt de maneira diferente. Por padrão, a primeira diretiva correspondente sempre vence.
No entanto, com Google e Bing, a especificidade vence. Por exemplo: uma diretiva Allow vence uma diretiva Disallow se o comprimento de seus caracteres for maior.
Exemplo
No exemplo acima de todos os mecanismos de pesquisa, incluindo Google e Bing, não têm permissão para acessar o diretório /about/, exceto para o subdiretório /about/company/.
Exemplo
No exemplo acima, todos os mecanismos de pesquisa, exceto Google e Bing, não têm permissão para acessar o diretório /about/. Isso inclui o diretório /about/company/.
Google e Bing têm acesso permitido, porque a diretiva Allow é mais longa que a Disallow diretiva.
Apenas um grupo de diretivas por robô
Você só pode definir um grupo de diretivas por mecanismo de pesquisa. Ter vários grupos de diretivas para um mecanismo de pesquisa os confunde.
Seja o mais específico possível
A diretiva Disallow aciona correspondências parciais como Nós vamos. Seja o mais específico possível ao definir a diretiva Disallow para evitar a proibição involuntária do acesso aos arquivos.
Exemplo:
O exemplo acima não permite o acesso dos mecanismos de pesquisa a:
-
/directory -
/directory/ -
/directory-name-1 -
/directory-name.html -
/directory-name.php -
/directory-name.pdf
Diretivas para todos os robôs, ao mesmo tempo incluindo diretivas para um robô específico
Para um robô apenas um grupo de diretivas é válido. Caso as diretivas destinadas a todos os robôs sejam seguidas pelas diretivas de um robô específico, apenas essas diretivas específicas serão consideradas. Para que o robô específico também siga as diretivas para todos os robôs, você precisa repetir essas diretivas para o robô específico.
Vejamos um exemplo que deixará isso claro:
Exemplo
Se você não quiser que o googlebot acesse /secret/ e /not-launched-yet/, será necessário repetir essas diretivas para googlebot especificamente:
Observe que o seu arquivo robots.txt está disponível publicamente. Desautorizar as seções do site pode ser usado como um vetor de ataque por pessoas com más intenções.

Robots.txt pode ser perigoso. Você não está apenas dizendo aos mecanismos de pesquisa onde não quer que eles olhem, mas também dizendo às pessoas onde você esconde seus segredos sujos.
Arquivo Robots.txt para cada (sub) domínio
Apenas diretivas Robots.txt aplicam-se ao (sub) domínio em que o arquivo está hospedado.
Exemplos
é válido para , mas não para ou
It’s a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
Monitor your robots.txt file
It’s important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *Disallow: / Criamos alertas e rastreamento de alterações em robots.txt por esse motivo.
Vemos isso o tempo todo: arquivos robots.txt mudando sem conhecimento do marketing digital equipe. Não seja essa pessoa. Comece a monitorar seu arquivo robots.txt agora receba alertas quando ele mudar!
Não use noindex em seu robots.txt
Por anos, o Google já recomendava abertamente contra o uso da diretiva não oficial noindex. No entanto, a partir de 1º de setembro de 2019, o Google deixou de oferecer suporte totalmente.
A diretiva não oficial noindex nunca funcionou no Bing, conforme confirmado por Frédéric Dubut neste tweet:
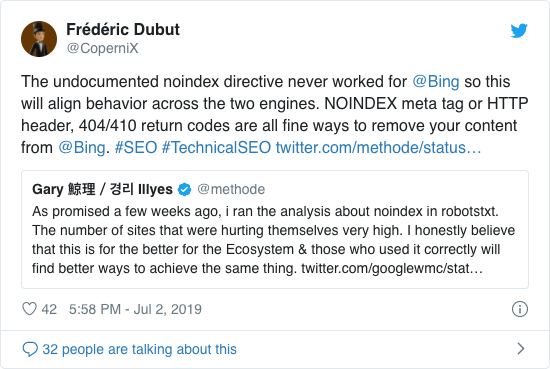
A melhor maneira de sinalizar aos mecanismos de pesquisa que as páginas não devem ser indexadas é usando a meta tag de robôs ou X-Robots-Tag .
Impedir UTF-8 BOM no arquivo robots.txt
BOM significa marca de ordem de byte, um caractere invisível no início de um arquivo usado para indicar a codificação Unicode de um arquivo de texto.
Embora o Google afirme que ignora a marca opcional de ordem de bytes Unicode no início do arquivo robots.txt, recomendamos evitar o “BOM UTF-8” porque vimos ele causar problemas com a interpretação de o arquivo robots.txt pelos mecanismos de pesquisa.
Embora o Google diga que eles podem lidar com isso, aqui estão dois motivos para evitar o BOM UTF-8:
- Você não não quero que haja qualquer ambiguidade sobre suas preferências quanto ao rastreamento para mecanismos de pesquisa.
- Existem outros mecanismos de pesquisa por aí, que podem não ser tão tolerantes quanto o Google afirma ser.
Exemplos de robôs.txt
Neste capítulo, cobriremos uma ampla gama de exemplos de arquivo robots.txt:
- Permitir que todos os robôs acessem tudo
- Proibir o acesso de todos os robôs a tudo
- Todos os bots do Google não têm acesso
- Todos os bots do Google, exceto o Googlebot news, não têm acesso
- Googlebot e Slurp não têm acesso
- Todos os robôs não têm acesso a dois diretórios
- Todos os robôs não têm acesso a um arquivo específico
- O Googlebot não tem acesso a / admin / e Slurp não tem acesso a / private /
- Arquivo Robots.txt para WordPress
- Arquivo Robots.txt para Magento
Permitir que todos os robôs acessem tudo
Existem várias maneiras para informar aos mecanismos de pesquisa que eles podem acessar todos os arquivos:
Ou ter um arquivo robots.txt vazio ou não ter nenhum robots.txt.
Proibir o acesso de todos os robôs a tudo
O exemplo O robots.txt abaixo diz a todos os mecanismos de pesquisa para não acessar o site inteiro:
Observe que apenas UM caractere extra pode fazer toda a diferença.
Todos os bots do Google não têm acesso
Observe que ao desabilitar o Googlebot, isso se aplica a todos os Googlebots. Isso inclui robôs do Google que estão procurando por notícias (googlebot-news) e imagens (googlebot-images).
Todos Os bots do Google, exceto o Googlebot News, não têm acesso
Googlebot e Slurp não têm nenhum acesso
Todos os robôs não têm acesso a dois diretórios
Todos os robôs não têm acesso a um arquivo específico
O Googlebot não tem acesso a / admin / e Slurp não têm acesso a / private /
Robots.txt arquivo para WordPress
O arquivo robots.txt abaixo é especificamente otimizado para WordPress, assumindo:
- Você não quer que sua seção de administração seja rastreada.
- Você não deseja que suas páginas de resultados de pesquisa internas sejam rastreadas.
- Você não deseja que suas tags e páginas de autor sejam rastreadas.
- Você não quer não quero que sua página 404 seja rastreada.
Observe que esse arquivo robots.txt funcionará na maioria dos casos, mas você deve sempre ajustá-lo e testá-lo para ter certeza de que se aplica ao seu situação exata.
Arquivo Robots.txt para Magento
O arquivo robots.txt abaixo é especificamente otimizado para Magento e fará resultados de pesquisa interna, páginas de login, identificadores de sessão e resultado filtrado conjuntos que contêm price, color, material e size critérios inacessíveis para rastreadores.
Observe que este arquivo robots.txt funcionará para a maioria das lojas Magento, deve sempre ajustá-lo e testá-lo para ter certeza de que se aplica à sua situação exata.
Mesmo assim, sempre procuro bloquear os resultados da pesquisa interna no robots.txt em qualquer site porque esses tipos de URLs de pesquisa são espaços infinitos e sem fim. Há muito potencial para o Googlebot cair em uma armadilha do rastreador.
Quais são as limitações do arquivo robots.txt?
O arquivo Robots.txt contém diretivas
Mesmo que o robots.txt seja bem respeitado pela pesquisa motores, ainda é uma diretiva e não um mandato.
Páginas que ainda aparecem nos resultados da pesquisa
Páginas que são inacessíveis para os motores de pesquisa devido aos robôs.txt, mas têm links para eles, ainda podem aparecer nos resultados de pesquisa se estiverem vinculados a uma página que é rastreada. Um exemplo de como isso se parece:

É possível remover esses URLs do Google usando a ferramenta de remoção de URL do Google Search Console. Observe que esses URLs ficarão apenas temporariamente “ocultos”. Para que eles fiquem fora das páginas de resultados do Google, você precisa enviar uma solicitação para ocultar os URLs a cada 180 dias.

Use o robots.txt para bloquear backlinks indesejáveis e provavelmente prejudiciais dos afiliados. não use o robots.txt na tentativa de impedir que o conteúdo seja indexado pelos mecanismos de pesquisa, pois isso inevitavelmente falhará. Em vez disso, aplique a diretiva dos robôs noindex quando necessário.
O arquivo Robots.txt é armazenado em cache por até 24 horas
O Google indicou que robôs O arquivo .txt geralmente é armazenado em cache por até 24 horas. É importante levar isso em consideração ao fazer alterações no seu arquivo robots.txt.
Não está claro como outros mecanismos de pesquisa lidam com o armazenamento em cache do robots.txt. , mas, em geral, é melhor evitar armazenar em cache o arquivo robots.txt para av Os mecanismos de pesquisa oid demoram mais do que o necessário para detectar as alterações.
Tamanho do arquivo Robots.txt
Para arquivos robots.txt, o Google atualmente suporta um limite de tamanho de arquivo de 500 kibibytes (512 kilobytes). Qualquer conteúdo após esse tamanho máximo de arquivo pode ser ignorado.
Não está claro se outros mecanismos de pesquisa têm um tamanho máximo de arquivo para arquivos robots.txt.
Perguntas frequentes sobre o robots.txt
🤖 Qual é a aparência de um exemplo de robots.txt?
Aqui está um exemplo de conteúdo de um robots.txt: User-agent: * Disallow:. Isso informa a todos os rastreadores que eles podem acessar tudo.
⛔ O que Disallow all faz no robots.txt?
Quando você define um robots.txt como “Disallow all”, você está essencialmente dizendo a todos os rastreadores para ficarem fora. Nenhum rastreador, incluindo o Google, tem permissão para acessar seu site. Isso significa que eles não poderão rastrear, indexar e classificar seu site. Isso levará a uma queda enorme no tráfego orgânico.
✅ O que Permitir todos faz no robots.txt?
Quando você define um robots.txt para “Permitir todos”, você diz a todos os rastreadores que eles podem acessar todos os URLs do site. Simplesmente não existem regras de engajamento. Observe que isso é o equivalente a ter um robots.txt vazio ou nenhum robots.txt.
🤔 Qual a importância do robots.txt para SEO?
Em Em geral, o arquivo robots.txt é muito importante para fins de SEO. Para sites maiores, o robots.txt é essencial para fornecer aos mecanismos de pesquisa instruções muito claras sobre qual conteúdo não acessar.