

K Nejbližší soused je jednoduchý algoritmus, který ukládá všechny dostupné případy a klasifikuje nová data nebo případy na základě opatření podobnosti. Většinou se používá ke klasifikaci datového bodu podle toho, jak jsou klasifikováni jeho sousedé.
Vezměme si níže příklad vína. Dvě chemické složky zvané Rutime a myricetin. Zvažte měření hladiny rutinu vs myricetinu pomocí dvou datových bodů, červeného a bílého vína. Testovali a kde potom spadají do tohoto grafu na základě toho, kolik rutinu a kolik chemického obsahu myricetinu ve vínech obsahuje.

„ k “v KNN je parametr, který odkazuje na počet nejbližších sousedů, kteří mají být zahrnuti do většiny hlasovacího procesu.
Předpokládejme, že pokud přidáme nové sklo vína v datové sadě. Rádi bychom věděli, zda je nové víno červené nebo bílé?

Takže my je třeba zjistit, co jsou v tomto případě sousedé. Řekněme k = 5 a nový datový bod je klasifikován většinou hlasů od svých pěti sousedů a nový bod by byl klasifikován jako červený, protože čtyři z pěti sousedů jsou červené.

Jak mám vybrat hodnotu k v algoritmu KNN?

‚k‘ v algoritmu KNN je založeno na podobnosti funkce výběr správné hodnoty K je proces zvaný ladění parametrů a je důležitý pro lepší přesnost. Zjištění hodnoty k není snadné.

Několik nápadů na výběr hodnoty pro ‚ K ‚
- Neexistuje žádná strukturovaná metoda, jak najít nejlepší hodnotu pro „K“. Musíme zjistit různé hodnoty metodou pokusů a omylů a za předpokladu, že tréninková data nejsou známa.
- Výběr menších hodnot pro K může být hlučný a bude mít větší vliv na výsledek.
3) Větší hodnoty K budou mít plynulejší hranice rozhodování, což znamená nižší rozptyl, ale zvýšený zkreslení. Také výpočetně nákladné.
4) Dalším způsobem, jak zvolit K, je křížová validace. Jedním ze způsobů, jak vybrat datovou sadu pro křížovou validaci ze školicí datové sady. Vezměte malou část ze školicí datové sady a nazvěme to datovou sadou pro ověření a poté ji použijeme k vyhodnocení různých možných hodnot K. Tímto způsobem předpovídáme štítek pro každá instance v sadě ověřování pomocí K se rovná 1, K se rovná 2, K se rovná 3 .. a pak se podíváme na to, jaká hodnota K nám dává nejlepší výkon na ověřovací sadě, a pak můžeme tuto hodnotu vzít a použijte to jako konečné nastavení našeho algoritmu, abychom minimalizovali chybu ověření.
5) Obecně platí, že výběr hodnoty k je v praxi k = sqrt (N), kde N znamená počet ukázky ve vaší tréninkové datové sadě.
6) Pokuste se zachovat hodnotu k liché, aby nedošlo k záměně mezi dvěma třídami dat.
Jak funguje KNN Algorithm?
V nastavení klasifikace se algoritmus K-nejbližšího souseda v podstatě scvrkává na formování většinového hlasování mezi K nejpodobnějšími instancemi pro dané „neviditelné“ pozorování. Podobnost je definována podle metriky vzdálenosti mezi dvěma datovými body. Oblíbenou metodou je euklidovská metoda vzdálenosti.
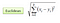
Další metody jsou metody vzdálenosti na Manhattan, Minkowski a Hamming. U kategorických proměnných je třeba použít Hammanovu vzdálenost.
Vezměme si malý příklad. Věk vs. půjčka.

Musíme předpovědět Andrewovo výchozí nastavení stav (Ano nebo Ne).

Vypočítejte euklidovskou vzdálenost pro všechny datové body.