

K Neighbor cel mai apropiat este un algoritm simplu care stochează toate cazurile disponibile și clasifică noile date sau caz pe baza o măsură de similitudine. Este folosit în principal pentru a clasifica un punct de date în funcție de clasificarea vecinilor săi.
Să luăm mai jos exemplul vinului. Două componente chimice numite Rutime și Myricetin. Luați în considerare o măsurare a nivelului de rutină vs Myricetin cu două puncte de date, vinuri roșii și albe. Au testat și unde se încadrează în acel grafic pe baza cantității de rutină și a conținutului de substanță chimică Myricetin prezentă în vinuri.

‘k’ în KNN este un parametru care se referă la numărul celor mai apropiați vecini care trebuie incluși în majoritatea procesului de votare.
Să presupunem că, dacă adăugăm un nou pahar de vin din setul de date. Am dori să știm dacă vinul nou este roșu sau alb?

Deci, noi trebuie să aflăm care sunt vecinii în acest caz. Să presupunem că k = 5 și noul punct de date este clasificat la majoritatea voturilor celor cinci vecini, iar noul punct ar fi clasificat ca roșu, deoarece patru din cinci vecini sunt roșii.

Cum aleg valoarea lui k în algoritmul KNN?

‘k’ în algoritmul KNN se bazează pe similitudinea caracteristicilor alegerea valorii corecte a lui K este un proces numit reglarea parametrilor și este important pentru o mai bună acuratețe. Găsirea valorii lui k nu este ușoară.

Puține idei despre alegerea unei valori pentru „ K ‘
- Nu există nicio metodă structurată pentru a găsi cea mai bună valoare pentru „K”. Trebuie să aflăm cu diferite valori prin încercare și eroare și presupunând că datele de antrenament sunt necunoscute.
- Alegerea unor valori mai mici pentru K poate fi zgomotoasă și va avea o influență mai mare asupra rezultatului.
3) Valorile mai mari ale lui K vor avea limite de decizie mai fine, ceea ce înseamnă o varianță mai mică, dar a crescut prejudecată. De asemenea, scump din punct de vedere al calculului.
4) O altă modalitate de a alege K este prin validare încrucișată. O modalitate de a selecta setul de date de validare încrucișată din setul de date de antrenament. Luați partea mică din setul de date de antrenament și numiți-l set de date de validare, apoi folosiți același lucru pentru a evalua diferite valori posibile ale lui K. Astfel vom prezice eticheta pentru fiecare instanță din setul de validare folosind cu K este egal cu 1, K este egal cu 2, K este egal cu 3 .. și apoi ne uităm la ce valoare a lui K ne oferă cea mai bună performanță pe setul de validare și atunci putem lua acea valoare și folosiți acest lucru ca setare finală a algoritmului nostru, astfel încât să minimalizăm eroarea de validare. mostre în setul de date de antrenament.
6) Încercați să păstrați valoarea lui k impar pentru a evita confuzia între două clase de date
Cum funcționează algoritmul KNN?
În setarea clasificării, algoritmul cel mai apropiat de vecinul K se rezumă, în esență, la formarea unui vot majoritar între cele mai multe instanțe K similare cu o observație „nevăzută” dată. Asemănarea este definită în funcție de metrica distanței dintre două puncte de date. Una populară este metoda distanței euclidiene
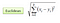
Alte metode sunt metodele de distanță Manhattan, Minkowski și Hamming. Pentru variabilele categorice, trebuie utilizată distanța de lovire.
Să luăm un mic exemplu. Vârstă vs împrumut.

Trebuie să prezicem implicit Andrew starea (Da sau Nu).

Calculați distanța euclidiană pentru toate punctele de date.