

K Nærmeste nabo er en enkel algoritme som lagrer alle tilgjengelige saker og klassifiserer de nye dataene eller sakene basert på et likhetstiltak. Det brukes vanligvis til å klassifisere et datapunkt basert på hvordan naboene er klassifisert.
La oss ta et eksempel på vin. To kjemiske komponenter kalt Rutime og Myricetin. Vurder en måling av Rutine vs Myricetin-nivå med to datapunkter, røde og hvite viner. De har testet og hvor da faller på grafen basert på hvor mye Rutine og hvor mye Myricetin kjemisk innhold som er tilstede i vinene.

‘k’ i KNN er en parameter som refererer til antall nærmeste naboer som skal inkluderes i flertallet av stemmeprosessen.
Anta, hvis vi legger til et nytt glass vin i datasettet. Vi vil gjerne vite om den nye vinen er rød eller hvit?

Så vi trenger å finne ut hva naboene er i dette tilfellet. La oss si at k = 5 og det nye datapunktet er klassifisert av flertallet av stemmene fra de fem naboene, og det nye punktet vil bli klassifisert som rødt siden fire av fem naboer er røde.

Hvordan skal jeg velge verdien av k i KNN-algoritme?

‘k’ i KNN-algoritme er basert på funksjonslikhet. Å velge riktig verdi av K er en prosess som kalles parameterinnstilling og er viktig for bedre nøyaktighet. Det er ikke lett å finne verdien av k.

Få ideer om å velge en verdi for ‘ K ‘
- Det er ingen strukturert metode for å finne den beste verdien for «K». Vi må finne ut av forskjellige verdier ved prøving og feiling og forutsatt at treningsdata er ukjent.
- Valg av mindre verdier for K kan være støyende og vil ha større innflytelse på resultatet.
3) Større verdier av K vil ha jevnere beslutningsgrenser som betyr lavere varians, men økt skjevhet. Også beregningsdyr.
4) En annen måte å velge K på er kryssvalidering. En måte å velge kryssvalideringsdatasettet fra treningsdatasettet. Ta den lille delen fra treningsdatasettet og kaller det et valideringsdatasett, og bruk deretter det samme til å evaluere forskjellige mulige verdier av K. På denne måten skal vi forutsi etiketten for hver forekomst i valideringssettet ved hjelp av K er lik 1, K tilsvarer 2, K tilsvarer 3 .. og så ser vi på hvilken verdi av K som gir oss den beste ytelsen på valideringssettet, og så kan vi ta den verdien og bruk det som den endelige innstillingen av algoritmen vår, så vi minimerer valideringsfeilen.
5) Generelt sett er det å velge verdien av k er k = sqrt (N) hvor N står for antall eksempler i treningsdatasettet ditt.
6) Prøv og hold verdien på k odd for å unngå forveksling mellom to dataklasser
Hvordan fungerer KNN-algoritme?
I klassifiseringsinnstillingen koker K-nærmeste naboalgoritme i det vesentlige til å danne et flertall mellom de mest liknende tilfellene til en gitt «usett» observasjon. Likhet er definert i henhold til en avstandsmåling mellom to datapunkter. En populær er den euklidiske avstandsmetoden
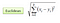
Andre metoder er Manhattan, Minkowski og Hamming avstandsmetoder. For kategoriske variabler må hammingavstanden brukes.
La oss ta et lite eksempel. Alder mot lån.

Vi må forutsi Andrews standard status (Ja eller Nei).

Beregn euklidisk avstand for alle datapunktene.