

K Nearest Neighbor è un semplice algoritmo che memorizza tutti i casi disponibili e classifica i nuovi dati o casi in base a una misura di somiglianza. Viene utilizzato principalmente per classificare un punto dati in base a come sono classificati i suoi vicini.
Prendiamo sotto l’esempio del vino. Due componenti chimici chiamati Rutime e Myricetin. Considera una misurazione del livello di Rutina vs Miricetina con due punti dati, vini rossi e bianchi. Hanno testato e dove poi ricadono su quel grafico in base a quanta Rutina e quanto contenuto chimico di Miricetina presente nei vini.

” k “in KNN è un parametro che si riferisce al numero di vicini più vicini da includere nella maggior parte del processo di votazione.
Supponiamo, se aggiungiamo un nuovo bicchiere di vino nel set di dati. Vorremmo sapere se il vino nuovo è rosso o bianco?

Quindi, noi bisogno di scoprire quali sono i vicini in questo caso. Supponiamo che k = 5 e il nuovo punto dati sia classificato dalla maggioranza dei voti dei suoi cinque vicini e il nuovo punto verrebbe classificato come rosso poiché quattro vicini su cinque sono rossi.

Come devo scegliere il valore di k nell’algoritmo KNN?

‘k’ nell’algoritmo KNN si basa sulla somiglianza delle caratteristiche scegliendo il giusto valore di K è un processo chiamato regolazione dei parametri ed è importante per una migliore precisione. Trovare il valore di k non è facile.

Poche idee su come scegliere un valore per ” K ‘
- Non esiste un metodo strutturato per trovare il valore migliore per “K”. Dobbiamo scoprirlo con vari valori per tentativi ed errori e supponendo che i dati di addestramento siano sconosciuti.
- La scelta di valori più piccoli per K può essere fastidiosa e avrà un’influenza maggiore sul risultato.
3) Valori più grandi di K avranno confini decisionali più fluidi che significano una varianza inferiore ma aumentata bias. Inoltre, computazionalmente costoso.
4) Un altro modo per scegliere K è la convalida incrociata. Un modo per selezionare il set di dati di convalida incrociata dal set di dati di addestramento. Prendi la piccola parte dal set di dati di addestramento e chiamalo un set di dati di convalida, quindi usa lo stesso per valutare diversi possibili valori di K. In questo modo prevediamo l’etichetta per ogni istanza nell’insieme di convalida che utilizza con K è uguale a 1, K è uguale a 2, K è uguale a 3 .. e poi guardiamo quale valore di K ci dà le migliori prestazioni sull’insieme di convalida e quindi possiamo prendere quel valore e usalo come impostazione finale del nostro algoritmo in modo da ridurre al minimo l’errore di convalida.
5) In generale, la pratica, la scelta del valore di k è k = sqrt (N) dove N sta per il numero di campioni nel tuo set di dati di addestramento.
6) Cerca di mantenere il valore di k dispari per evitare confusione tra due classi di dati
Come funziona l’algoritmo KNN?
Nell’impostazione di classificazione, l’algoritmo del vicino più prossimo K si riduce essenzialmente a formare un voto di maggioranza tra le istanze K più simili a una data osservazione “invisibile”. La somiglianza è definita in base a una metrica di distanza tra due punti dati. Un metodo popolare è il metodo della distanza euclidea
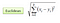
Altri metodi sono i metodi a distanza Manhattan, Minkowski e Hamming. Per le variabili categoriali, è necessario utilizzare la distanza di percussione.
Facciamo un piccolo esempio. Età vs prestito.

Dobbiamo prevedere Andrew predefinito stato (Sì o No).

Calcola la distanza euclidea per tutti i punti dati.