

K Najbliższy sąsiad to prosty algorytm, który przechowuje wszystkie dostępne przypadki i klasyfikuje nowe dane lub przypadki na podstawie miara podobieństwa. Służy głównie do klasyfikowania punktu danych na podstawie klasyfikacji jego sąsiadów.
Weźmy poniżej przykład wina. Dwa składniki chemiczne o nazwie Rutime i Myricetin. Rozważ pomiar poziomu rutyny w porównaniu z mirycetyną z dwoma punktami danych, winami czerwonymi i białymi. Przetestowali, a następnie wypadają na tym wykresie w oparciu o zawartość rutyny i mirycetyny w winach.

'k' w KNN to parametr, który odnosi się do liczby najbliższych sąsiadów, które mają być uwzględnione w większości procesu głosowania.
Załóżmy, że jeśli dodamy nową szklankę wina w zbiorze danych. Chcielibyśmy wiedzieć, czy nowe wino jest czerwone czy białe?

Zatem trzeba dowiedzieć się, jacy są w tym przypadku sąsiedzi. Powiedzmy, że k = 5, a nowy punkt danych jest klasyfikowany większością głosów od pięciu sąsiadów, a nowy punkt zostałby sklasyfikowany jako czerwony, ponieważ czterech z pięciu sąsiadów jest czerwonych.

Jak wybrać wartość k w algorytmie KNN?

'k' w algorytmie KNN opiera się na podobieństwie cech Wybór właściwej wartości K jest procesem nazywanym dostrajaniem parametrów i jest ważny dla uzyskania większej dokładności. Znalezienie wartości k nie jest łatwe.

Kilka pomysłów na wybór wartości dla „ K '
- Nie ma ustrukturyzowanej metody znalezienia najlepszej wartości dla „K”. Musimy znaleźć różne wartości metodą prób i błędów oraz zakładając, że dane treningowe są nieznane.
- Wybór mniejszych wartości K może być zaszumiony i będzie miał większy wpływ na wynik.
3) Większe wartości K będą miały gładsze granice decyzyjne, co oznacza mniejszą wariancję, ale większe odchylenie. Również kosztowne obliczeniowo.
4) Innym sposobem wyboru K jest walidacja krzyżowa. Jednym ze sposobów wybrania zestawu danych do weryfikacji krzyżowej z zestawu danych szkoleniowych. Weź niewielką część z zestawu danych szkoleniowych i nazwij to zbiorem danych do walidacji, a następnie użyj tego samego do oceny różnych możliwych wartości K. W ten sposób zamierzamy przewidzieć etykietę dla każda instancja w zbiorze walidacyjnym przy użyciu K równa się 1, K równa się 2, K równa się 3 .. a następnie sprawdzamy, jaka wartość K daje nam najlepszą wydajność w zbiorze walidacyjnym, a następnie możemy przyjąć tę wartość i użyj tego jako końcowego ustawienia naszego algorytmu, aby zminimalizować błąd walidacji.
5) Ogólnie rzecz biorąc, w praktyce wybranie wartości k to k = sqrt (N), gdzie N oznacza liczbę próbki w zbiorze danych treningowych.
6) Spróbuj zachować wartość k nieparzystą, aby uniknąć pomyłki między dwiema klasami danych.
Jak działa algorytm KNN?
W klasyfikacji, algorytm K-najbliższego sąsiada zasadniczo sprowadza się do utworzenia większości głosów między K najbardziej podobnymi przypadkami do danej „niewidocznej” obserwacji. Podobieństwo jest definiowane na podstawie metryki odległości między dwoma punktami danych. Popularną metodą jest metoda odległości euklidesowej
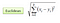
Inne metody to metody odległości Manhattan, Minkowski i Hamming. W przypadku zmiennych kategorialnych należy użyć odległości Hamminga.
Weźmy mały przykład. Wiek a pożyczka.

Musimy przewidzieć Andrew jako domyślny status (tak lub nie).

Oblicz odległość euklidesową dla wszystkich punktów danych.