

K Lähin naapuri on yksinkertainen algoritmi, joka tallentaa kaikki käytettävissä olevat tapaukset ja luokittelee uudet tiedot tai tapaukset samankaltaisuusmitta. Sitä käytetään enimmäkseen luokittelemaan datapiste sen mukaan, miten sen naapurit luokitellaan.
Otetaan esimerkki viinistä. Kaksi kemiallista komponenttia, nimeltään Rutime ja Myricetin. Harkitse Rutine vs Myricetin -tason mittaamista kahdella datapisteellä, punaisella ja valkoviinillä. He ovat testanneet ja mihin sitten sijoittuvat kaavioon sen perusteella, kuinka paljon Rutine- ja Myricetin-kemiallisia pitoisuuksia viineissä on.

’k’ KNN: ssä on parametri, joka viittaa lähimpien naapureiden lukumäärään, joka sisällytetään suurimpaan osaan äänestysprosessia.
Oletetaan, että jos lisäämme uuden lasin viiniä tietojoukossa. Haluamme tietää, onko uusi viini punainen vai valkoinen?

Joten, me täytyy selvittää, mitä naapurit ovat tässä tapauksessa. Oletetaan, että k = 5 ja uusi datapiste luokitellaan sen viiden naapurin äänten enemmistöllä ja uusi piste luokitellaan punaiseksi, koska neljä viidestä naapurista on punaisia.

Kuinka valitsen k: n arvon KNN-algoritmissa?

’k’ KNN-algoritmissa perustuu ominaisuuksien samankaltaisuuteen. Oikean K-arvon valitseminen on prosessi, jota kutsutaan parametrien viritykseksi ja joka on tärkeä tarkkuuden parantamiseksi. K: n arvon löytäminen ei ole helppoa.

Muutama idea arvon valitsemiselle K ’
- Ei ole jäsenneltyä menetelmää ”K”: n parhaan arvon löytämiseksi. Meidän on selvitettävä erilaisilla arvoilla kokeilemalla ja olettaen, että harjoitteludataa ei tunneta.
- Pienempien arvojen valitseminen K: lle voi olla meluisa ja sillä on suurempi vaikutus tulokseen.
3) Suuremmilla K-arvoilla on tasaisemmat päätösrajat, mikä tarkoittaa pienempää varianssia, mutta kasvaa bias. Myös laskennallisesti kallis.
4) Toinen tapa valita K on ristivalidointi. Yksi tapa valita ristivalidoinnin tietojoukko harjoitustietojoukosta. Ota pieni osa harjoittelutietojoukosta ja kutsu sitä validointiaineistoksi ja käytä samaa samalla K: n eri mahdollisten arvojen arvioimiseen. Tällä tavalla aiomme ennustaa jokainen validointijoukon esiintymä, joka käyttää K: n kanssa, on 1, K on 2, K on 3 .. ja sitten katsotaan, mikä K: n arvo antaa meille parhaan suorituskyvyn validointijoukossa, ja sitten voimme ottaa kyseisen arvon ja Käytä sitä algoritmin lopullisena asetuksena, jotta minimoimme vahvistusvirheen.
5) Yleensä käytännössä k: n arvon valitseminen on k = sqrt (N), jossa N tarkoittaa esimerkkejä harjoittelutietojoukostasi.
6) Yritä pitää k: n pariton arvo välttääksesi sekaannusta kahden tietoluokan välillä.
Kuinka KNN-algoritmi toimii?
Luokitteluasetuksessa K-lähimmän naapurin algoritmi supistuu muodostaen enemmistön äänen K: n vastaavimpien ilmentymien välillä tietyn ”näkymättömän” havainnon välillä. Samankaltaisuus määritetään kahden datapisteen välisen etäisyystiedon mukaan. Suosittu menetelmä on euklidinen etäisyysmenetelmä
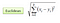
Muita menetelmiä ovat Manhattanin, Minkowskin ja Hammingin etäisyysmenetelmät. Luokka-muuttujien osalta on käytettävä vasaran etäisyyttä.
Otetaan pieni esimerkki. Ikä vs. laina.

Meidän on ennustettava Andrew oletuksena tila (Kyllä tai Ei).

Laske euklidinen etäisyys kaikille datapisteille.