

K Nearest Neighbor ist ein einfacher Algorithmus, der alle verfügbaren Fälle speichert und die neuen Daten oder Fälle basierend auf klassifiziert ein Ähnlichkeitsmaß. Es wird hauptsächlich verwendet, um einen Datenpunkt basierend auf der Klassifizierung seiner Nachbarn zu klassifizieren.
Nehmen wir das folgende Weinbeispiel. Zwei chemische Komponenten namens Rutime und Myricetin. Betrachten Sie eine Messung des Rutin- gegenüber dem Myricetin-Gehalt mit zwei Datenpunkten, Rot- und Weißwein. Sie haben getestet und wo fallen sie dann auf diese Grafik, basierend darauf, wie viel Rutin und wie viel Myricetin chemischer Gehalt in den Weinen vorhanden ist.

‚k‘ in KNN ist ein Parameter, der sich auf die Anzahl der nächsten Nachbarn bezieht, die in die Mehrheit des Abstimmungsprozesses einbezogen werden sollen.
Angenommen, wir fügen ein neues Glas hinzu Wein im Datensatz. Wir möchten wissen, ob der neue Wein rot oder weiß ist?

Also, wir müssen herausfinden, was die Nachbarn in diesem Fall sind. Angenommen, k = 5 und der neue Datenpunkt wird mit der Mehrheit der Stimmen seiner fünf Nachbarn klassifiziert, und der neue Punkt wird als rot klassifiziert, da vier von fünf Nachbarn rot sind.

Wie soll ich den Wert von k im KNN-Algorithmus auswählen?

‚k‘ im KNN-Algorithmus basiert auf der Ähnlichkeit von Merkmalen. Die Auswahl des richtigen Werts von K ist ein Prozess, der als Parameteroptimierung bezeichnet wird und für eine bessere Genauigkeit wichtig ist. Das Ermitteln des Werts von k ist nicht einfach.

Einige Ideen zur Auswahl eines Werts für ‚ K ‚
- Es gibt keine strukturierte Methode, um den besten Wert für „K“ zu finden. Wir müssen mit verschiedenen Werten durch Versuch und Irrtum herausfinden und davon ausgehen, dass die Trainingsdaten unbekannt sind.
- Die Auswahl kleinerer Werte für K kann verrauscht sein und einen höheren Einfluss auf das Ergebnis haben.
3) Größere Werte für K haben glattere Entscheidungsgrenzen, die eine geringere Varianz bedeuten, aber größer sind Voreingenommenheit. Auch rechenintensiv.
4) Eine andere Möglichkeit, K zu wählen, ist die Kreuzvalidierung. Eine Möglichkeit, den Kreuzvalidierungsdatensatz aus dem Trainingsdatensatz auszuwählen. Nehmen Sie den kleinen Teil aus dem Trainingsdatensatz und Nennen Sie es einen Validierungsdatensatz und verwenden Sie denselben, um verschiedene mögliche Werte von K zu bewerten. Auf diese Weise werden wir das Etikett für vorhersagen Jede Instanz im Validierungssatz, die mit K gleich 1 ist, K ist gleich 2, K ist gleich 3 .. und dann schauen wir uns an, welcher Wert von K uns die beste Leistung für den Validierungssatz liefert, und dann können wir diesen Wert und nehmen Verwenden Sie dies als endgültige Einstellung unseres Algorithmus, um den Validierungsfehler zu minimieren.
5) Im Allgemeinen ist die Auswahl des Werts von k k = sqrt (N), wobei N für die Anzahl von steht Beispiele in Ihrem Trainingsdatensatz.
6) Versuchen Sie, den Wert von k ungerade zu halten, um Verwechslungen zwischen zwei Datenklassen zu vermeiden.
Wie funktioniert der KNN-Algorithmus?
In der Klassifizierungseinstellung läuft der K-Nächste-Nachbar-Algorithmus im Wesentlichen darauf hinaus, eine Mehrheitsabstimmung zwischen den K ähnlichsten Instanzen zu einer bestimmten „unsichtbaren“ Beobachtung zu bilden. Die Ähnlichkeit wird anhand einer Abstandsmetrik zwischen zwei Datenpunkten definiert. Eine beliebte Methode ist die euklidische Distanzmethode
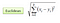
Andere Methoden sind Manhattan-, Minkowski- und Hamming-Distanzmethoden. Für kategoriale Variablen muss der Hamming-Abstand verwendet werden.
Nehmen wir ein kleines Beispiel. Alter gegen Darlehen.

Wir müssen Andrews Standard vorhersagen Status (Ja oder Nein).

Berechnen Sie den euklidischen Abstand für alle Datenpunkte.