

K最近傍法は、利用可能なすべてのケースを格納し、新しいデータまたはケースをに基づいて分類する単純なアルゴリズムです。類似性の尺度。これは主に、隣接するデータポイントの分類方法に基づいてデータポイントを分類するために使用されます。
以下のワインの例を見てみましょう。ルタイムとミリセチンと呼ばれる2つの化学成分。赤ワインと白ワインの2つのデータポイントを使用して、ルチンとミリセチンのレベルを測定することを検討してください。彼らはテストを行い、ワインに含まれるルチンの量とミリセチンの化学物質の量に基づいて、そのグラフのどこに分類されますか。

KNNの「k」は、投票プロセスの大部分に含める最近傍の数を参照するパラメータです。
新しいグラスを追加するとします。データセット内のワインの。新しいワインが赤か白か知りたいのですが?

つまり、この場合、隣人が何であるかを知る必要があります。 k = 5で、新しいデータポイントが5つの近傍からの投票の過半数によって分類され、5つの近傍のうち4つが赤であるため、新しいポイントは赤として分類されるとします。

KNNアルゴリズムでkの値を選択するにはどうすればよいですか?

KNNアルゴリズムの「k」は、特徴の類似性に基づいており、Kの正しい値を選択することは、パラメーター調整と呼ばれるプロセスであり、精度を高めるために重要です。 kの値を見つけるのは簡単ではありません。

‘の値を選択するためのいくつかのアイデアK ‘
- 「K」の最適な値を見つけるための構造化された方法はありません。試行錯誤によってさまざまな値を見つけ、トレーニングデータが不明であると想定する必要があります。
- Kに小さい値を選択すると、ノイズが多くなり、結果への影響が大きくなります。
3)Kの値を大きくすると、決定境界が滑らかになり、分散は小さくなりますが、増加します。バイアス。また、計算コストも高くなります。
4)Kを選択する別の方法は、相互検証です。トレーニングデータセットから相互検証データセットを選択する1つの方法です。トレーニングデータセットから少量を取得し、これを検証データセットと呼び、同じものを使用してKのさまざまな可能な値を評価します。このようにして、次のラベルを予測します。 Kが1に等しい、Kが2に等しい、Kが3に等しいを使用する検証セット内のすべてのインスタンス。次に、検証セットで最高のパフォーマンスが得られるKの値を調べ、その値を取得して、これをアルゴリズムの最終設定として使用して、検証エラーを最小限に抑えます。
5)一般に、kの値の選択はk = sqrt(N)です。ここで、Nは次の数を表します。トレーニングデータセットのサンプル。
6)2つのクラスのデータ間の混乱を避けるために、kの値を奇数に保つようにしてください。
KNNアルゴリズムはどのように機能しますか?
分類設定では、K最近傍アルゴリズムは基本的に、特定の「見えない」観測に最も類似したK個のインスタンス間で多数決を形成することになります。類似性は、2つのデータポイント間の距離メトリックに従って定義されます。人気のある方法は、ユークリッド距離法です
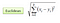
他の方法は、マンハッタン、ミンコフスキー、およびハミング距離法です。カテゴリ変数の場合、ハミング距離を使用する必要があります。
小さな例を見てみましょう。年齢とローン。

Andrewのデフォルトを予測する必要がありますステータス(はいまたはいいえ)。

すべてのデータポイントのユークリッド距離を計算します。