

K Nearest Neighbor는 사용 가능한 모든 케이스를 저장하고 다음을 기반으로 새 데이터 또는 케이스를 분류하는 간단한 알고리즘입니다. 유사성 측정. 주로 이웃이 분류되는 방식에 따라 데이터 포인트를 분류하는 데 사용됩니다.
아래의 와인 예를 들어 보겠습니다. Rutime과 Myricetin이라는 두 가지 화학 성분. 두 개의 데이터 포인트, 레드 와인과 화이트 와인으로 Rutine 대 Myricetin 수준의 측정을 고려하십시오. 그들은 와인에 포함 된 Rutine의 양과 Myricetin의 화학 성분 함량을 기준으로 그래프의 위치와 위치를 테스트했습니다.

‘k’는 대부분의 투표 과정에 포함 할 가장 가까운 이웃의 수를 나타내는 매개 변수입니다.
새 유리 잔을 추가한다고 가정합니다. 데이터 세트의 와인 새 와인이 빨간색인지 흰색인지 알고 싶습니다.

그래서 이 경우 이웃이 무엇인지 알아 내야합니다. k = 5이고 새 데이터 포인트가 5 개 이웃의 과반수 투표로 분류되고 새 포인트는 5 개 이웃 중 4 개가 빨간색이므로 빨간색으로 분류됩니다.

KNN 알고리즘에서 k 값을 어떻게 선택하나요?

‘k’는 기능 유사성을 기반으로 K의 올바른 값을 선택하는 것은 매개 변수 조정이라고하는 프로세스이며 정확도 향상을 위해 중요합니다. k 값을 찾는 것은 쉽지 않습니다.

‘값 선택에 대한 몇 가지 아이디어 K ‘
- ‘K ‘에 가장 적합한 값을 찾을 수있는 구조화 된 방법은 없습니다. 학습 데이터를 알 수 없다고 가정하고 시행 착오를 통해 다양한 값을 찾아야합니다.
- K에 대해 더 작은 값을 선택하면 노이즈가 발생할 수 있으며 결과에 더 큰 영향을 미칠 수 있습니다.
3) K 값이 클수록 결정 경계가 더 부드러워 지지만 분산은 낮아 지지만 증가합니다. 또한 계산 비용이 많이 듭니다.
4) K를 선택하는 또 다른 방법은 교차 검증입니다. 훈련 데이터 세트에서 교차 검증 데이터 세트를 선택하는 한 가지 방법입니다. 훈련 데이터 세트에서 작은 부분을 취하고 이를 유효성 검사 데이터 세트라고 부르고 동일한 것을 사용하여 K의 다른 가능한 값을 평가합니다. 이렇게하면 레이블을 예측할 수 있습니다. K는 1, K는 2, K는 3을 사용하는 유효성 검사 집합의 모든 인스턴스. 그런 다음 K의 값이 유효성 검사 집합에서 최상의 성능을 제공하는지 확인한 다음 해당 값을 가져 와서 이를 알고리즘의 최종 설정으로 사용하여 유효성 검사 오류를 최소화합니다.
5) 일반적으로 k 값을 선택하는 것은 k = sqrt (N)입니다. 여기서 N은 학습 데이터 세트의 샘플입니다.
6) 두 데이터 클래스 간의 혼동을 피하기 위해 k 값을 홀수로 유지하십시오.
KNN 알고리즘은 어떻게 작동합니까?
분류 설정에서 K- 최근 접 이웃 알고리즘은 기본적으로 주어진 “보이지 않는”관측치에 대해 가장 유사한 K 개의 인스턴스간에 다수결 투표를 형성하는 것으로 귀결됩니다. 유사성은 두 데이터 포인트 간의 거리 측정 항목에 따라 정의됩니다. 인기있는 방법은 유클리드 거리 방법입니다.
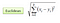
다른 방법으로는 Manhattan, Minkowski 및 Hamming distance 방법이 있습니다. 범주 형 변수의 경우 해밍 거리를 사용해야합니다.
작은 예를 들어 보겠습니다. 연령 대 대출.

Andrew 기본값을 예측해야합니다. 상태 (예 또는 아니오).

모든 데이터 포인트에 대한 유클리드 거리를 계산합니다.