

K Närmaste granne är en enkel algoritm som lagrar alla tillgängliga fall och klassificerar nya data eller fall baserat på en likhetsåtgärd. Det används mest för att klassificera en datapunkt baserat på hur dess grannar klassificeras.
Låt oss ta ett exempel på vin. Två kemiska komponenter som kallas Rutime och Myricetin. Tänk på en mätning av Rutine vs Myricetin-nivå med två datapunkter, röda och vita viner. De har testat och där faller sedan på den grafen baserat på hur mycket Rutine och hur mycket kemiskt innehåll i Myricetin som finns i vinerna.

’k’ i KNN är en parameter som hänvisar till antalet närmaste grannar som ska ingå i majoriteten av omröstningsprocessen.
Antag att om vi lägger till ett nytt glas vin i datasetet. Vi vill veta om det nya vinet är rött eller vitt?

Så vi måste ta reda på vad grannarna är i det här fallet. Låt oss säga k = 5 och den nya datapunkten klassificeras med majoriteten av rösterna från dess fem grannar och den nya punkten skulle klassificeras som röd eftersom fyra av fem grannar är röda.

Hur ska jag välja värdet på k i KNN-algoritm?

’k’ i KNN-algoritmen är baserad på funktionslikhet att välja rätt värde på K är en process som kallas parameterinställning och är viktig för bättre noggrannhet. Att hitta värdet på k är inte lätt.

Få idéer för att välja ett värde för ’ K ’
- Det finns ingen strukturerad metod för att hitta det bästa värdet för ”K”. Vi måste ta reda på det med olika värden genom försök och fel och förutsatt att träningsdata är okända.
- Att välja mindre värden för K kan vara bullrigt och kommer att ha ett högre inflytande på resultatet.
3) Större värden på K kommer att ha jämnare beslutsgränser som betyder lägre variation men ökad bias. Också beräkningsmässigt dyrt.
4) Ett annat sätt att välja K är dock korsvalidering. Ett sätt att välja korsvalideringsdataset från träningsdataset. Ta den lilla delen från träningsdataset och kalla det en valideringsdataset och använd sedan samma för att utvärdera olika möjliga värden på K. På detta sätt kommer vi att förutsäga etiketten för varje instans i valideringsuppsättningen med K är lika med 1, K är lika med 2, K är lika med 3 .. och sedan tittar vi på vilket värde på K som ger oss den bästa prestandan på valideringsuppsättningen och sedan kan vi ta det värdet och använd det som den slutliga inställningen för vår algoritm så att vi minimerar valideringsfelet.
5) I allmänhet är övningen att välja värdet på k är k = sqrt (N) där N står för antalet prover i din träningsdataset.
6) Försök att behålla värdet på k odd för att undvika förvirring mellan två dataklasser
Hur fungerar KNN-algoritm?
I klassificeringsinställningen kokar den närmaste grannalgoritmen i huvudsak ner till att bilda en majoritetsröstning mellan de K som mest liknar en given ”osynlig” observation. Likhet definieras enligt ett avståndsmätvärde mellan två datapunkter. En populär är den euklidiska avståndsmetoden
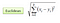
Andra metoder är avståndsmetoder Manhattan, Minkowski och Hamming. För kategoriska variabler måste hammingsavståndet användas.
Låt oss ta ett litet exempel. Ålder mot lån.

Vi måste förutsäga Andrews standard status (Ja eller Nej).

Beräkna euklidiskt avstånd för alla datapunkter.