

K Nærmeste nabo er en simpel algoritme, der gemmer alle tilgængelige sager og klassificerer de nye data eller sager baseret på en lighedstiltag. Det bruges mest til at klassificere et datapunkt baseret på, hvordan dets naboer er klassificeret.
Lad os tage nedenstående vineksempel. To kemiske komponenter kaldet Rutime og Myricetin. Overvej en måling af Rutine vs Myricetin-niveau med to datapunkter, rød og hvidvin. De har testet, og hvor falder derpå grafen baseret på hvor meget Rutine og hvor meget Myricetin kemisk indhold der findes i vinene.

‘k’ i KNN er en parameter, der refererer til antallet af nærmeste naboer, der skal medtages i størstedelen af afstemningsprocessen.
Antag, hvis vi tilføjer et nyt glas vin i datasættet. Vi vil gerne vide, om den nye vin er rød eller hvid?

Så vi skal finde ud af, hvad naboerne er i dette tilfælde. Lad os sige, at k = 5, og det nye datapunkt er klassificeret med flertallet af stemmer fra dets fem naboer, og det nye punkt vil blive klassificeret som rødt, da fire ud af fem naboer er røde.

Hvordan skal jeg vælge værdien af k i KNN-algoritme?

‘k’ i KNN-algoritme er baseret på funktionslighed at vælge den rigtige værdi af K er en proces kaldet parameterindstilling og er vigtig for bedre nøjagtighed. Det er ikke let at finde værdien af k.

Få ideer til at vælge en værdi til ‘ K ‘
- Der er ingen struktureret metode til at finde den bedste værdi for “K”. Vi er nødt til at finde ud af det med forskellige værdier ved at prøve og fejle og antage, at træningsdata er ukendte.
- Valg af mindre værdier for K kan være støjende og vil have en større indflydelse på resultatet.
3) Større værdier for K vil have jævnere beslutningsgrænser, som betyder lavere varians, men øget bias. Også beregningsmæssigt dyrt.
4) En anden måde at vælge K på er krydsvalidering. En måde at vælge krydsvalideringsdatasættet fra træningsdatasættet. Tag den lille del fra træningsdatasættet og kalde det et valideringsdatasæt, og brug det samme til at evaluere forskellige mulige værdier af K. På denne måde forudsiger vi etiketten for hver instans i valideringssættet ved hjælp af med K er lig med 1, K er lig med 2, K er lig med 3 .. og så ser vi på, hvilken værdi af K, der giver os den bedste ydeevne på valideringssættet, og så kan vi tage den værdi og brug det som den endelige indstilling af vores algoritme, så vi minimerer valideringsfejlen.
5) Generelt er praksis at vælge værdien af k er k = sqrt (N) hvor N står for antallet af prøver i dit træningsdatasæt.
6) Prøv og hold værdien af k ulige for at undgå forveksling mellem to klasser af data
Hvordan fungerer KNN-algoritme?
I klassifikationsindstillingen koger den K-nærmeste naboalgoritme i det væsentlige til at danne et flertal mellem de K-mest lignende forekomster til en given “uset” observation. Lighed er defineret i henhold til en afstandsmetrik mellem to datapunkter. En populær er den euklidiske afstandsmetode
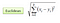
Andre metoder er Manhattan, Minkowski og Hamming distance metoder. For kategoriske variabler skal hammingafstanden bruges.
Lad os tage et lille eksempel. Alder vs lån.

Vi er nødt til at forudsige Andrews standard status (Ja eller Nej).

Beregn den euklidiske afstand for alle datapunkterne.