

K A legközelebbi szomszéd egy egyszerű algoritmus, amely az összes rendelkezésre álló esetet tárolja, és az új adatokat vagy eseteket az alapján osztályozza. hasonlósági intézkedés. Leginkább egy adatpont osztályozására használják a szomszédok osztályozása alapján.
Vegyünk példát a borra. Két kémiai komponens, a Rutime és a Myricetin. Vegyünk egy Rutine és Myricetin szint mérését két adatponttal, vörös és fehér borokkal. Kipróbálták, és hol esnek erre a grafikonra annak alapján, hogy mennyi rutin és mennyi miricetin kémiai tartalom van a borokban.

A kn a KNN-ben egy olyan paraméter, amely a legközelebbi szomszédok számát jelöli, amelyet a szavazási folyamat többségében be kell vonni.
Tegyük fel, hogy ha új poharat adunk hozzá bor az adatkészletben. Szeretnénk tudni, hogy az új bor vörös vagy fehér?

Tehát, meg kell tudni, hogy mi ebben az esetben a szomszédok. Tegyük fel, hogy k = 5, és az új adatpontot az öt szomszéd szavazatainak többsége osztályozza, és az új pontot pirosnak minősítenék, mivel ötből négy szomszéd vörös. >

Hogyan válasszam ki a k értékét a KNN algoritmusban?

A ‘k’ a KNN algoritmusban a jellemzők hasonlóságán alapul, és a K megfelelő értékének kiválasztása a paraméterek hangolásának nevezett folyamat, és fontos a jobb pontosság érdekében. A k értékének megtalálása nem egyszerű.

Néhány ötlet az érték kiválasztásához K ‘
- Nincs strukturált módszer a „K” legjobb értékének megtalálásához. Különböző értékekkel kell próbálkozással és hibával megtudnunk, feltételezve, hogy az edzés adatai ismeretlenek.
- A K kisebb értékeinek kiválasztása zajos lehet, és nagyobb hatással lesz az eredményre.
3) A K nagyobb értékei simább döntési határokkal bírnak, amelyek alacsonyabb szórást jelentenek, de nagyobbak torzítás. Számítási szempontból is drága.
4) A K kiválasztásának másik módja a keresztellenőrzés. A keresztellenőrzési adatkészlet kiválasztásának egyik módja a képzési adatkészletből. Vegyük a kis részt a képzési adatkészletből, és nevezzük validációs adatkészletnek, majd ugyanezt használjuk a K lehetséges különböző értékeinek kiértékeléséhez. Így meg fogjuk jósolni a az érvényesítési halmaz minden példánya a K-val egyenlő 1, K egyenlő 2, K egyenlő 3 .. majd megvizsgáljuk, hogy a K melyik értéke adja a legjobb teljesítményt az érvényesítési halmazon, és akkor ezt az értéket felvehetjük és használjuk ezt algoritmusunk végső beállításaként, így minimalizáljuk az érvényesítési hibát.
5) Általánosságban a k értékének kiválasztása k = sqrt (N), ahol N az minták a képzési adatkészletben.
6) Próbálja meg megőrizni a k páratlan értékét a két adattípus közötti összetévesztés elkerülése érdekében.
Hogyan működik a KNN algoritmus?
A besorolás beállításában a K-legközelebbi szomszéd algoritmus lényegében abból áll, hogy többségi szavazatot képez az adott “láthatatlan” megfigyeléshez leginkább hasonló K példányok között. A hasonlóságot két adatpont távolságmérője határozza meg. Népszerű az euklideszi távolság metódus
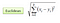
További módszerek a Manhattan, Minkowski és Hamming távolsági módszerek. A kategorikus változókhoz a kalapács távolságot kell használni.
Vegyünk egy kis példát. Kor és kölcsön.

Meg kell jósolni Andrew alapértelmezését állapot (Igen vagy Nem).

Számítsa ki az összes adatpont euklideszi távolságát.