

K Dichtstbijzijnde buur is een eenvoudig algoritme dat alle beschikbare gevallen opslaat en de nieuwe gegevens of casus classificeert op basis van een maatstaf voor gelijkenis. Het wordt meestal gebruikt om een gegevenspunt te classificeren op basis van hoe de buren zijn geclassificeerd.
Laten we het onderstaande wijnvoorbeeld nemen. Twee chemische componenten genaamd Rutime en Myricetin. Overweeg een meting van het Rutine versus Myricetin-niveau met twee gegevenspunten, rode en witte wijn. Ze hebben getest en waar vallen dan op die grafiek op basis van hoeveel rutine en hoeveel Myricetin-chemische inhoud aanwezig is in de wijnen.

‘k’ in KNN is een parameter die verwijst naar het aantal naaste buren dat in het merendeel van het stemproces moet worden meegenomen.
Stel dat als we een nieuw glas wijn in de dataset. We willen graag weten of de nieuwe wijn rood of wit is?

Dus we moeten weten wat de buren in dit geval zijn. Laten we zeggen dat k = 5 en het nieuwe datapunt wordt geclassificeerd door de meerderheid van de stemmen van de vijf buren en het nieuwe punt zou als rood worden geclassificeerd aangezien vier van de vijf buren rood zijn.

Hoe kies ik de waarde van k in KNN-algoritme?

‘k’ in KNN-algoritme is gebaseerd op gelijkenis van kenmerken. Het kiezen van de juiste waarde van K is een proces dat parameterafstemming wordt genoemd en is belangrijk voor een betere nauwkeurigheid. Het vinden van de waarde van k is niet eenvoudig.

Weinig ideeën over het kiezen van een waarde voor ‘ K ‘
- Er is geen gestructureerde methode om de beste waarde voor “K” te vinden. We moeten met vallen en opstaan uitzoeken met verschillende waarden en ervan uitgaande dat de trainingsgegevens onbekend zijn.
- Het kiezen van kleinere waarden voor K kan luidruchtig zijn en heeft een grotere invloed op het resultaat.
3) Hogere waarden van K zullen vloeiendere beslissingsgrenzen hebben, wat een lagere variantie betekent maar een grotere bias. Ook rekenkundig duur.
4) Een andere manier om K te kiezen is door middel van kruisvalidatie. Een manier om de kruisvalidatiedataset uit de trainingsdataset te selecteren. Haal het kleine deel uit de trainingsdataset en noem het een validatiedataset en gebruik deze vervolgens om verschillende mogelijke waarden van K te evalueren. Op deze manier gaan we het label voorspellen voor elke instantie in de validatieset met K is gelijk aan 1, K is gelijk aan 2, K is gelijk aan 3 .. en dan kijken we welke waarde van K ons de beste prestatie geeft op de validatieset en dan kunnen we die waarde nemen en gebruik dat als de laatste instelling van ons algoritme, zodat we de validatiefout minimaliseren.
5) In de praktijk is het kiezen van de waarde van k k = sqrt (N) waar N staat voor het aantal voorbeelden in uw trainingsdataset.
6) Probeer de waarde van k oneven te houden om verwarring tussen twee gegevensklassen te voorkomen.
Hoe werkt KNN-algoritme?
In de classificatie-instelling komt het K-dichtstbijzijnde-buuralgoritme in wezen neer op het vormen van een meerderheid van stemmen tussen de K meest vergelijkbare gevallen van een bepaalde “ongeziene” waarneming. Overeenkomsten worden gedefinieerd op basis van een afstandsmetriek tussen twee gegevenspunten. Een populaire methode is de Euclidische afstandsmethode
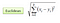
Andere methoden zijn de afstandsmethoden Manhattan, Minkowski en Hamming. Voor categorische variabelen moet de hamming-afstand worden gebruikt.
Laten we een klein voorbeeld nemen. Leeftijd versus lening.

We moeten Andrew standaard voorspellen status (ja of nee).

Bereken de Euclidische afstand voor alle datapunten.