

K Vecino más cercano es un algoritmo simple que almacena todos los casos disponibles y clasifica los nuevos datos o casos basándose en una medida de similitud. Se utiliza principalmente para clasificar un punto de datos en función de cómo se clasifican sus vecinos.
Tomemos el siguiente ejemplo de vino. Dos componentes químicos llamados Rutime y Myricetin. Considere una medición del nivel de rutina frente a miricetina con dos puntos de datos, vinos tintos y blancos. Han probado y dónde se ubican en ese gráfico según la cantidad de rutina y el contenido químico de miricetina presente en los vinos.

‘k’ en KNN es un parámetro que se refiere al número de vecinos más cercanos a incluir en la mayoría del proceso de votación.
Supongamos, si agregamos un nuevo vaso de vino en el conjunto de datos. ¿Nos gustaría saber si el vino nuevo es tinto o blanco?

Entonces, Necesito averiguar cuáles son los vecinos en este caso. Digamos que k = 5 y el nuevo punto de datos se clasifica por la mayoría de los votos de sus cinco vecinos y el nuevo punto se clasificaría como rojo ya que cuatro de cada cinco vecinos son rojos.

¿Cómo elegiré el valor de k en el algoritmo KNN?

‘k’ en el algoritmo KNN se basa en la similitud de características. La elección del valor correcto de K es un proceso llamado ajuste de parámetros y es importante para una mejor precisión. Encontrar el valor de k no es fácil.

Pocas ideas sobre cómo elegir un valor para ‘ K ‘
- No existe un método estructurado para encontrar el mejor valor para «K». Necesitamos averiguarlo con varios valores por prueba y error y asumiendo que los datos de entrenamiento son desconocidos.
- La elección de valores más pequeños para K puede ser ruidosa y tendrá una mayor influencia en el resultado.
3) Los valores más grandes de K tendrán límites de decisión más suaves, lo que significa una menor varianza pero una mayor sesgo. Además, computacionalmente costoso.
4) Otra forma de elegir K es mediante la validación cruzada. Una forma de seleccionar el conjunto de datos de validación cruzada del conjunto de datos de entrenamiento. Tome la pequeña parte del conjunto de datos de entrenamiento y llamarlo un conjunto de datos de validación, y luego usar el mismo para evaluar diferentes valores posibles de K. De esta manera vamos a predecir la etiqueta para cada instancia en el conjunto de validación usando con K es igual a 1, K es igual a 2, K es igual a 3 … y luego miramos qué valor de K nos da el mejor rendimiento en el conjunto de validación y luego podemos tomar ese valor y use eso como la configuración final de nuestro algoritmo para minimizar el error de validación.
5) En general, la práctica, elegir el valor de k es k = sqrt (N) donde N representa el número de muestras en su conjunto de datos de entrenamiento.
6) Intente mantener el valor de k impar para evitar confusiones entre dos clases de datos
¿Cómo funciona el algoritmo KNN?
En la configuración de clasificación, el algoritmo de K-vecino más cercano se reduce esencialmente a formar un voto mayoritario entre las K instancias más similares a una observación «invisible» dada. La similitud se define de acuerdo con una métrica de distancia entre dos puntos de datos. Uno popular es el método de distancia euclidiana
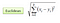
Otros métodos son los métodos de distancia de Manhattan, Minkowski y Hamming. Para las variables categóricas, se debe usar la distancia de hamming.
Tomemos un pequeño ejemplo. Edad frente a préstamo.

Necesitamos predecir el valor predeterminado de Andrew estado (Sí o No).

Calcule la distancia euclidiana para todos los puntos de datos.