

K Nearest Neighbor est un algorithme simple qui stocke tous les cas disponibles et classe les nouvelles données ou cas en fonction une mesure de similitude. Il est principalement utilisé pour classer un point de données en fonction de la façon dont ses voisins sont classés.
Prenons l’exemple de wine ci-dessous. Deux composants chimiques appelés Rutime et Myricetin. Considérez une mesure du niveau de rutine vs myricétine avec deux points de données, vins rouges et blancs. Ils ont testé et où se situent ensuite ce graphique en fonction de la quantité de rutine et de la teneur en myricétine présente dans les vins.

‘k’ dans KNN est un paramètre qui fait référence au nombre de voisins les plus proches à inclure dans la majorité du processus de vote.
Supposons, si nous ajoutons un nouveau verre de vin dans l’ensemble de données. Nous aimerions savoir si le vin nouveau est rouge ou blanc?

Donc, nous besoin de savoir ce que sont les voisins dans ce cas. Disons que k = 5 et que le nouveau point de données est classé par la majorité des votes de ses cinq voisins et le nouveau point serait classé comme rouge puisque quatre voisins sur cinq sont rouges.

Comment choisir la valeur de k dans l’algorithme KNN?

‘k’ dans l’algorithme KNN est basé sur la similitude des caractéristiques choisir la bonne valeur de K est un processus appelé réglage des paramètres et est important pour une meilleure précision. Trouver la valeur de k n’est pas facile.

Peu d’idées sur la sélection d’une valeur pour ‘ K ‘
- Il n’y a pas de méthode structurée pour trouver la meilleure valeur pour « K ». Nous devons trouver différentes valeurs par essais et erreurs et en supposant que les données d’entraînement sont inconnues.
- Le choix de valeurs plus petites pour K peut être bruyant et aura une plus grande influence sur le résultat.
3) Des valeurs plus grandes de K auront des limites de décision plus lisses, ce qui signifie une variance plus faible mais augmentée Un autre moyen de choisir K est la validation croisée. Une façon de sélectionner l’ensemble de données de validation croisée dans l’ensemble de données d’entraînement. Prenez la petite partie de l’ensemble de données d’entraînement et appelez-le un jeu de données de validation, puis utilisez le même pour évaluer différentes valeurs possibles de K. De cette façon, nous allons prédire l’étiquette pour chaque instance de l’ensemble de validation en utilisant avec K est égal à 1, K est égal à 2, K est égal à 3 .. puis nous regardons quelle valeur de K nous donne les meilleures performances sur l’ensemble de validation, puis nous pouvons prendre cette valeur et utilisez cela comme paramètre final de notre algorithme afin de minimiser l’erreur de validation.
5) En général, en pratique, choisir la valeur de k est k = sqrt (N) où N représente le nombre de échantillons dans votre jeu de données d’entraînement.
6) Essayez de garder la valeur de k impair afin d’éviter toute confusion entre deux classes de données
Comment fonctionne l’algorithme KNN?
Dans le cadre de la classification, l’algorithme du K-plus proche voisin se résume essentiellement à former un vote majoritaire entre les K instances les plus similaires à une observation « invisible » donnée. La similarité est définie en fonction d’une métrique de distance entre deux points de données. Une méthode populaire est la méthode de la distance euclidienne
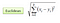
Les autres méthodes sont les méthodes de distance Manhattan, Minkowski et Hamming. Pour les variables catégorielles, la distance de frappe doit être utilisée.
Prenons un petit exemple. Âge vs prêt.

Nous devons prédire la valeur par défaut d’Andrew statut (Oui ou Non).

Calculez la distance euclidienne pour tous les points de données.