

K Vizinho Mais Próximo é um algoritmo simples que armazena todos os casos disponíveis e classifica os novos dados ou caso com base em uma medida de similaridade. É usado principalmente para classificar um ponto de dados com base em como seus vizinhos são classificados.
Vejamos o exemplo do vinho abaixo. Dois componentes químicos chamados Rutime e Miricetina. Considere uma medição do nível de rutina vs miricetina com dois pontos de dados, vinhos tintos e brancos. Eles testaram e onde se enquadram nesse gráfico com base na quantidade de Rutina e na quantidade de conteúdo químico da Miricetina presente nos vinhos.

‘k’ em KNN é um parâmetro que se refere ao número de vizinhos mais próximos a serem incluídos na maioria do processo de votação.
Suponha, se adicionarmos um novo copo de vinho no conjunto de dados. Gostaríamos de saber se o vinho novo é tinto ou branco?

Então, nós precisa descobrir quais são os vizinhos neste caso. Digamos que k = 5 e o novo ponto de dados seja classificado pela maioria dos votos de seus cinco vizinhos e o novo ponto seria classificado como vermelho, já que quatro dos cinco vizinhos são vermelhos.

Como devo escolher o valor de k no algoritmo KNN?

‘k’ no algoritmo KNN é baseado na similaridade de recursos, escolhendo o valor correto de K é um processo chamado ajuste de parâmetro e é importante para uma melhor precisão. Encontrar o valor de k não é fácil.

Poucas ideias sobre como escolher um valor para ‘ K ‘
- Não existe um método estruturado para encontrar o melhor valor para “K”. Precisamos descobrir com vários valores por tentativa e erro e assumindo que os dados de treinamento são desconhecidos.
- Escolher valores menores para K pode ser barulhento e terá uma maior influência no resultado.
3) Valores maiores de K terão limites de decisão mais suaves, o que significa menor variância, mas aumentada viés. Além disso, computacionalmente caro.
4) Outra maneira de escolher K é através da validação cruzada. Uma maneira de selecionar o conjunto de dados de validação cruzada do conjunto de dados de treinamento. Pegue uma pequena parte do conjunto de dados de treinamento e chame-o de conjunto de dados de validação e, em seguida, use o mesmo para avaliar diferentes valores possíveis de K. Desta forma, vamos prever o rótulo para cada instância no conjunto de validação usando com K igual a 1, K igual a 2, K igual a 3 .. e então olhamos qual valor de K nos dá o melhor desempenho no conjunto de validação e então podemos pegar esse valor e use isso como a configuração final do nosso algoritmo para minimizar o erro de validação.
5) Em geral, a prática, escolher o valor de k é k = sqrt (N), onde N representa o número de amostras em seu conjunto de dados de treinamento.
6) Tente manter o valor de k ímpar para evitar confusão entre duas classes de dados
Como funciona o algoritmo KNN?
Na configuração de classificação, o algoritmo K-vizinho mais próximo se resume essencialmente a formar um voto majoritário entre as K instâncias mais semelhantes a uma dada observação “invisível”. A similaridade é definida de acordo com uma métrica de distância entre dois pontos de dados. Um método popular é o método da distância euclidiana
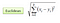
Outros métodos são os métodos de distância Manhattan, Minkowski e Hamming. Para variáveis categóricas, a distância de hamming deve ser usada.
Vamos dar um pequeno exemplo. Idade versus empréstimo.

Precisamos prever o padrão de Andrew status (Sim ou Não).

Calcule a distância euclidiana para todos os pontos de dados.